In a microservices architecture, an API gateway can help address a number of challenges: providing a stable endpoint for clients to call, allowing an easy process for releasing new endpoints, or handling SSL termination on behalf of services, to name a few. So how do we decide what features of an API gateway to adopt, and which to leave behind? This article highlights the key functions that an API gateway can provide, suggests the scope of problem that API gateways are well-suited to solve, and cautions against the features that make API gateways too ambitious.
What is an API gateway and why would I want one?
In a microservice architecture, many different services are used to provide functionality to a client. For example, consider Amazon’s product pages. To assemble a full view of a book details page may require making API requests to several different services: a book details service for the title, author, and metadata of the book, a service for listing the different buying options, a service for tracking items frequently bought with this book, and more. In the following diagram, each highlighted section may be served by a different backend service.
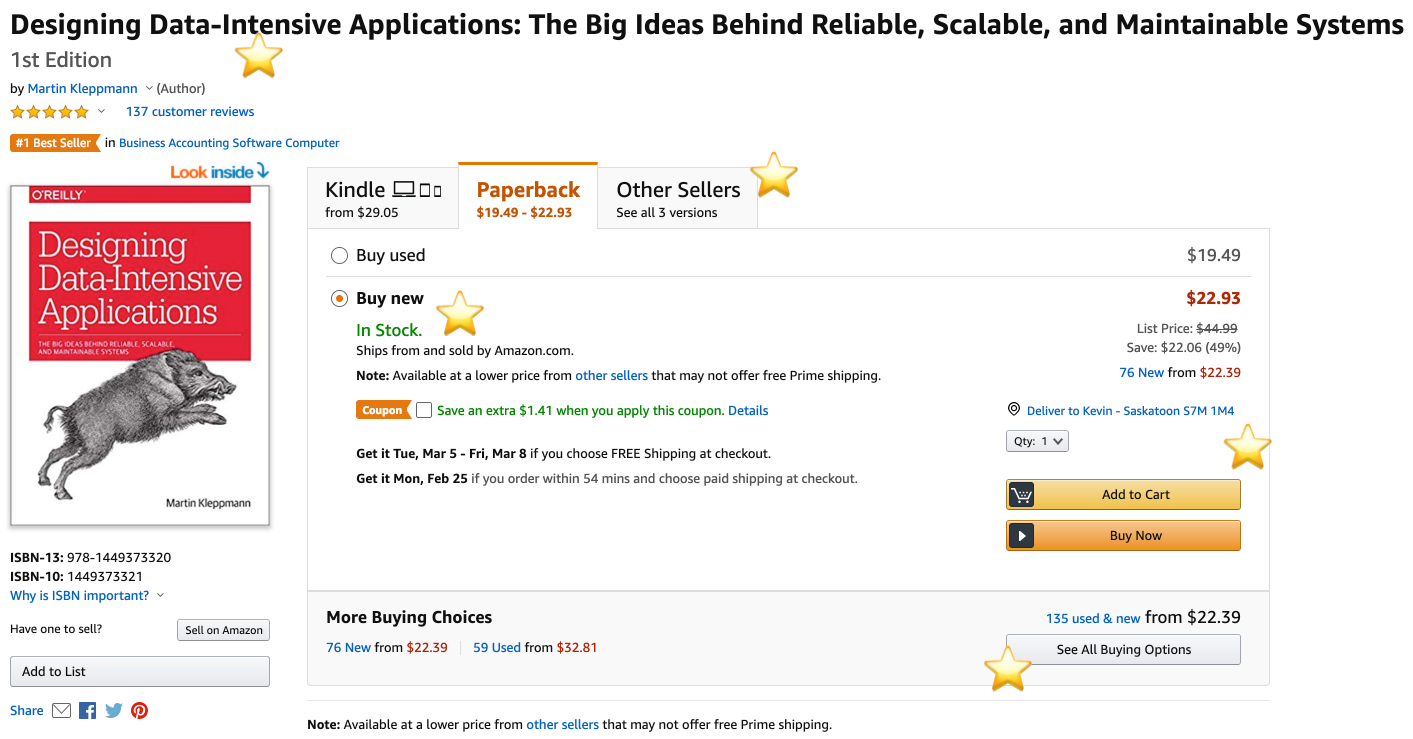
To assemble this page, the web client is responsible for making calls to each one of these services and assembling the response into a page. This approach can expose a number of problems for the client: it must keep track of multiple endpoints, it is tightly coupled with the backend, and it needs to know the composition of individual services. There are also problems for the server: each service needs to implement authentication, SSL, and rate limiting. The following figure shows this tightly coupled architecture, where a front-end client makes individual requests to multiple backend systems to assemble the page.
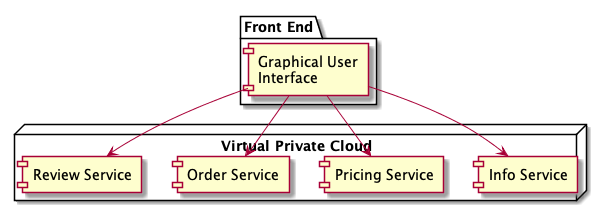
An API gateway helps address these issues by decoupling clients from services. In its simplest form, an API gateway is a reverse proxy that sits between clients and services. A client makes a request to the proxy, and the proxy retrieves resources on behalf of a client from one or more services. These resources are then returned to the client, appearing as if they originated from the proxy server itself. In this setup, reverse proxies can hide the existence and characteristics of an origin server or servers, and provide clients with an improved user experience by limiting the number of integration points. Figure 3 shows how the client is decoupled from backends through the API gateway.
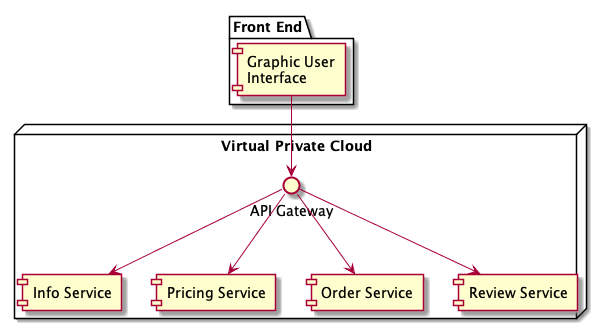
The many functions of a gateway
Now that we have the gateway in place, it is interesting to look at the functionality it can provide. This can be roughly divided into three categories: routing, offloading, and aggregation.
Routing
Routing is the functionality we just described. The gateway acts as a reverse proxy that routes requests to one or more backend services. When configured correctly, the client only needs to know about a single domain or endpoint and traffic is routed to the correct backend service on the client’s behalf. This decoupling allows backend services to be added, split, or refactored without making any change to the client. Gateways can also help with deployment by making it easy to deploy new versions of an API. Routing at the gateway level can give you control over how clients are routed to particular versions of an API.
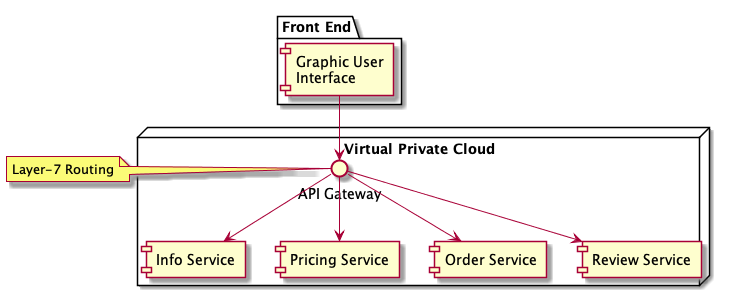
Offloading
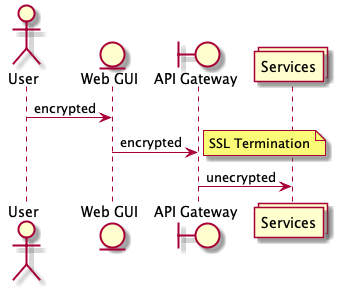
Because of the centralized location of the API gateway, it serves as an excellent point for implementing functionality that is common to all services. This functionality can range from security and operations, to load balancing and throttling. For example, it can be difficult to configure each and every service with valid SSL certificates and enforce that they implement authentication and authorization correctly. An alternative is to provide SSL termination at the gateway level. In this model, the API gateway terminates SSL connections and traffic flowing between services be left unencrypted (beware that there are cons to this approach). Another common concern is rate-limiting or throttling. Rather than have each service implement per-client rate limiting, you can implement it at the gateway level. A final example is protocol translation. Internally, services may communicate using an RPC framework like Thrift or gRPC, while externally APIs are exposed as RESTful HTTP+JSON endpoints. The API gateway is uniquely positioned to provide the translation between these protocols. External clients can benefit from a standard HTTP+JSON interface and internal clients can benefit from the improved performance of an RPC framework.
Aggregation
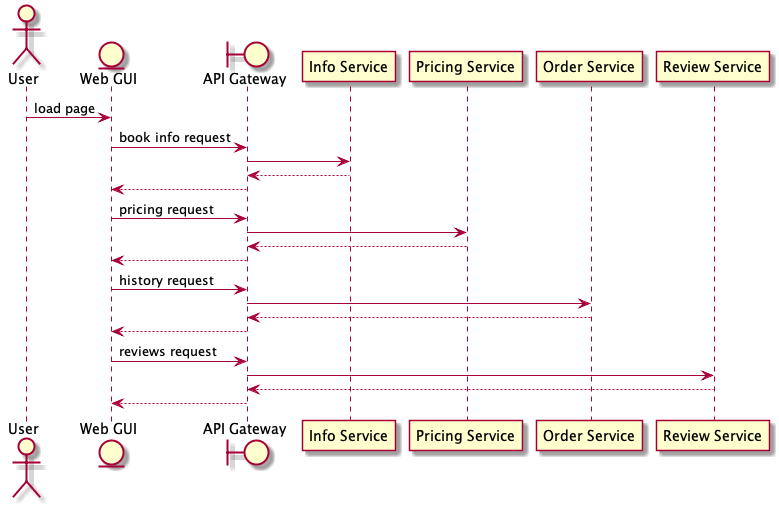
Sometimes, a client needs to make requests to multiple services to perform an operation. In Figure 6, the client sends four requests to individual services. Each service processes the request and sends the response back to the application. While each request can made parallel, the application must send, wait, and process data for each request, all on separate connections, increasing the latency of the entire operation and the chance of failure.
You can leverage the gateway as an aggregation point that limits the number of requests from the client. The client sends one request to the gateway and the gateway dispatches mulitple requests to the various backend services. The gateway aggregates the results and sends back a response to the client.
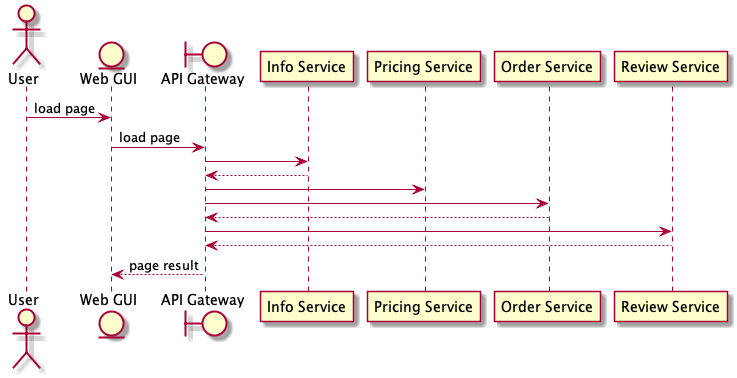
You can also to transform or shape the request and response data along the way. For example, the gateway can aggregate data from multiple backends and shape it to a data model that is best suited to the client. This typically takes the form of altering JSON data from an internal representation to an external one.
Are you being too ambitious? Keeping logic out of the gateway
Because of the unique and central position of an API gateway in your API architecture, they can be leveraged for a lot of functionality. Yet we need to keep sight of the core purpose of the gateway: decoupling clients from services. Most of the commercial implementations of API gateways tend to promote the data transformation and aggregation features of their product as a means of differentiating themselves from the competition. For example, you can use the data transformation and aggregation features of a gateway to expose variations of your APIs to different partners with different needs. This approach is risky — it can lead to complex business logic being implemented through a middleware solution that is difficult to deploy and test, rather than being managed by application teams and their defined software development best practices. If you are not careful, you end up implementing an untestable integration system in the gateway that is so complex that nobody can understand it and so critical that everyone is afraid to change it.
We remain concerned about business logic and process orchestration implemented in middleware, especially where it requires expert skills and tooling while creating single points of scaling and control. Vendors in the highly competitive API gateway market are continuing this trend by adding features through which they attempt to differentiate their products. This results in overambitious API gateway products whose functionality — on top of what is essentially a reverse proxy — encourages designs that continue to be difficult to test and deploy. API gateways do provide utility in dealing with some specific concerns — such as authentication and rate limiting — but any domain smarts should live in applications or services.
API gateways do provide a lot of benefits. Yet there are dangers in relying on gateways to do too much. To best leverage the power of gateways, you need to focus on letting the gateway do what it does best: traffic routing and offloading of common tasks. Avoid using the gateway to aggregate requests and responses from multiple services and avoid transforming data the gateway level. Those tasks are better suited to being done in testable application code that follows the defined software development best practices of your organization. In short, keep logic out of the gateway!