View all articles in the MapReduce API Series.
Last time we looked at an overview of how MapReduce works. In this article we’ll be getting our hands dirty writing some code to handle the Map Stage. If you’ll recall, the Map Stage is composed of two separate components: an InputReader and a map function. We’ll look at each of these in turn.
Getting Started: Installation
First, let’s install the MapReduce API for Python. The API is constantly changing so the best way to install the latest version is to checkout the code directly from the SVN repository.
svn checkout http://appengine-mapreduce.googlecode.com/svn/trunk/python/src/mapreduce
Place the mapreduce folder into your application root directory and add the mapreduce handler to your app.yaml file.
includes:
- lib/mapreduce/include.yaml
handlers:
- url: /_ah/pipeline.*
script: mapreduce.lib.pipeline.handlers._APP
login: admin
You can verify your installation by going to the /mapreduce URL in your app. You’ll see a UI listing the status of any MapReduce jobs. You’ll also see a notice that the UI could not find the file mapreduce.yaml. You can ignore that notice for now.

To get a proper view of the data you will also need to add two indexes to your index.yaml file to allow the MapReduce library to query for MapReduce jobs that are run via Pipelines and display them in the GUI.
indexes:
- kind: _AE_Pipeline_Record
properties:
- name: is_root_pipeline
- name: start_time
direction: desc
- kind: _AE_Pipeline_Record
properties:
- name: class_path
- name: start_time
direction: desc
Running Your First MapReduce Job
The easiest way to get started with MapReduce is to use the mapreduce.yaml file. This file allows you define a mapper function that will be executed for each entity passed to it. Let’s go straight to an example and create a mapreduce.yaml file (in your applications root directory) that will iterate over all entities of a certain Kind and put them to the datastore (updating their timestamp).
mapreduce:
- name: Touch all entity_kind Models
mapper:
input_reader: mapreduce.input_readers.DatastoreInputReader
handler: path_to_my.touch
params:
- name: entity_kind
default: path_to_my.MyModel
Go to the /mapreduce URL in your app and you should see the Touch all entity_kind Models job selectable under the Launch job setting.
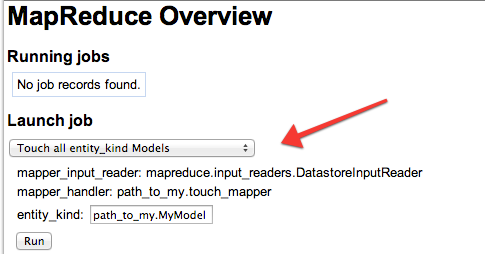
Go ahead and select this job and click Run. You will get an error saying that MyModel could not be found.

This is a great time to edit your yaml file point to an actual model in your application to continue with this tutorial. Now that our InputReader is pointing to a model we can define the map function specified by our yaml files handler parameter. The map function is iteratively passed entities from our InputReader and we can take actions on those entities.
def touch(entity):
"""
Update the entities timestamp.
"""
entity.put()
Go back to the /mapreduce URL in your app and run the job again. Refresh the page (if it does not auto-refresh) and you can see your job running.

You can click on the Detail link to get full details on the MapReduce job. This view gives you the status of individual shards in the MapReduce job and an overview of the processing time that was required.

We’ve ran our first MapReduce job!
The MutationPool
In our touch function we put our entity to the datastore once for each entity. This is wasteful when the datastore allows putting multiple items at a time. To take advantage of this feature the MapReduce library offers a MutationPool that collects datastore operations to be performed in batches.
We can re-write our map function to take advantage of the MutationPool by yielding a database operation from within our map function. If you are unfamiliar with yield you can think of it as returning a value to the MapReduce job. You can have multiple yield statements in a function that will all return values to be handled by the MapReduce job.
from mapreduce import operation as op
def touch(entity):
"""
Update the entities timestamp.
"""
yield op.db.Put(entity)
You can run the MapReduce job again and see that the job works correctly using datastore operations via the MutationPool.
The source code for MapReduce operations can be found in the mapreduce.operation module. The mapreduce.operation.db module currently supports two operations via the MutationPool Put and Delete.
Counters
The MapReduce library also provides counters that can be incremented when a condition is met. In our example we can count the number of entities that were touched by incrementing a counter.
from mapreduce import operation as op
def touch(entity):
"""
Update the entities timestamp.
"""
yield op.db.Put(entity)
yield op.counters.Increment('touched')
All the counters that were incremented during operation of the job are listed with the job details summary.

Passing Parameters to the Map Function
We can pass additional parameters to our map function by specifying them in mapreduce.yaml. Parameters are passed to both our InputReader and to our map handler function. In our example, we listed entity_kind and this parameter was expected by our InputReader and used to specify the datastore Kind processed by our InputReader. On the MapReduce status page (/mapreduce) we can type in a new value for this parameter to specify a different Kind before running the job.
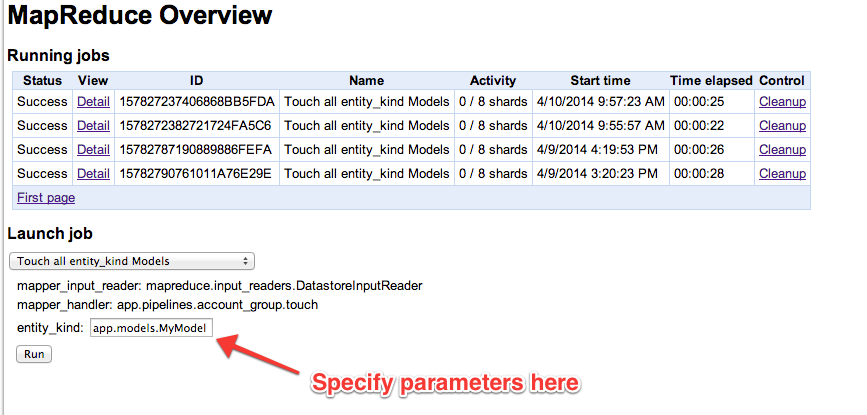
Let’s add an additional parameter for the map function that will only touch the entity if it is older than a specific date.
- name: Touch all entity_kind Models
mapper:
input_reader: mapreduce.input_readers.DatastoreInputReader
handler: app.pipelines.touch
params:
- name: entity_kind
default: app.models.UserModel
- name: if_older_than
default:
The mapreduce context holds the specifation for the job as defined by the mapreduce.yaml file. Within this context we can access our parameters.
from mapreduce import operation as op, context
from datetime import datetime
def touch(entity):
"""
Update the entities timestamp if not updated since if_older_than.
"""
params = context.get().mapreduce_spec.mapper.params
if_older_than = params.get('if_older_than')
older_than = datetime.strptime(if_older_than, '%b %d %Y') if if_older_than else datetime.now()
if entity.updated < older_than:
yield op.db.Put(entity)
yield op.counters.Increment('touched')
Now our map function will operate on entities that have been updated previous to our if_older_than parameter.
Parameter Validation
The MapReduce library also provides a method to do parameter validation. In our previous example we passed a date to our map function as a string. We can use a validator to validate that parameter and modify it as necessary. To use a validator function, specify it in mapreduce.yaml as params_validator.
- name: Touch all entity_kind Models
mapper:
input_reader: mapreduce.input_readers.DatastoreInputReader
handler: app.pipelines.touch
params:
- name: entity_kind
default: app.models.UserModel
- name: if_older_than
default: Jun 1 2014
params_validator: app.pipelines.touch_validator
The validator function accepts a single argument, a dictionary of parameters. The function can modify this dictionary and any modifications will be made available to the map function. In our example we can use the validator to attempt converting our input date into a datetime object. The strptime function returns a ValueError if it cannot convert a string to the datetime.
def touch_validator(user_params):
"""
Validate the parameters of our map function.
"""
if_older_than = user_params['if_older_than']
datetime.strptime(if_older_than, '%b %d %Y')
We can trigger the validator to fail by passing in an invalid date format.
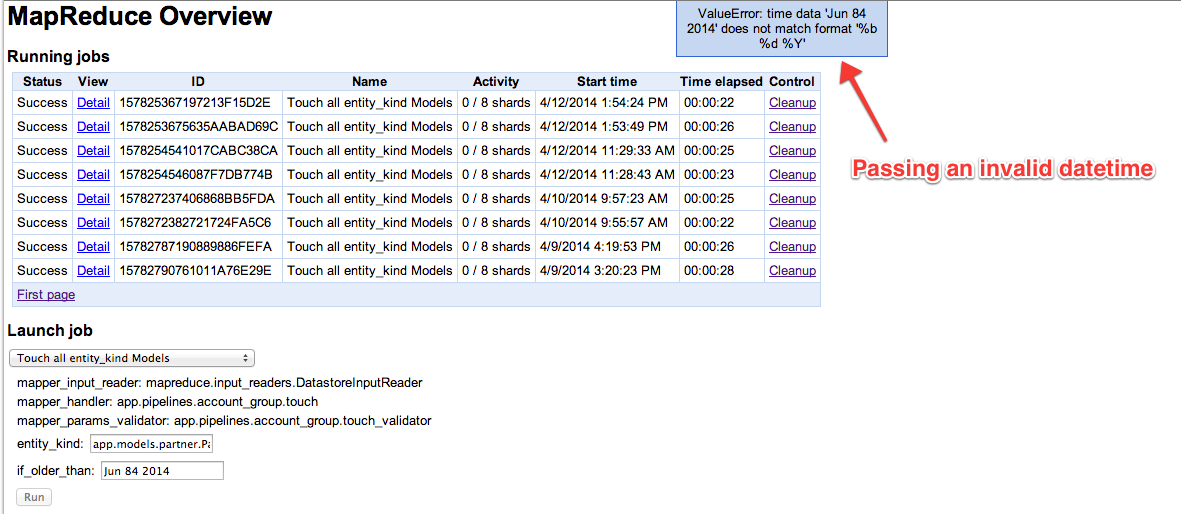
If parameter validation fails the MapReduce job is not started and no entities are passed from our InputReader to the map function.
Callbacks
The MapReduce library allows you to specify a callback function that is called after the MapReduce completes. This can be used for logging purposes or to trigger a specific event in code. The callback is specified in your mapreduce.yaml file as done_callback and points to a user specified function. This is a parameter of the MapReduce itself and not the map function – note the independent entry in mapreduce.yaml.
- name: Touch all entity_kind Models
params:
- name: done_callback
value: /done_touch
mapper:
input_reader: mapreduce.input_readers.DatastoreInputReader
handler: app.pipelines.touch
params:
- name: entity_kind
default: app.models.UserModel
- name: if_older_than
default: Jun 1 2014
params_validator: app.pipelines.touch_validator
Upon completion a POST request is made to the URL given by the done_callback parameter. The MapReduce library sets a custom header in this request with the jobs Mapreduce-Id. You can use this header to retrieve details on the job that just completed. This is also a great place to do any cleanup such as deleting temporary files. In our example we will just log the original specification for this job that we set via mapreduce.yaml
import webapp2
import logging
from mapreduce.model import MapreduceState
class DoneTouch(webapp2.RequestHandler):
"""
Callback function upon completion of touch MapReduce job.
"""
def post(self):
"""
Log the MapReduce ID and input parameters.
"""
mapreduce_id = self.request.headers['Mapreduce-Id']
state = MapreduceState.get_by_key_name(mapreduce_id)
spec = state.mapreduce_spec
logging.info(spec)
Additional Input Readers
In addition to the DatastoreInputReader the library includes readers for the
Blobstore, Files and Google Cloud Storage Buckets. The documentation for these
readers is scarse but you can consult the mapreduce.input_readers module for
more information on the expected parameters for these readers. This information
was gathered from a combination of the offical Python Users
Guide
and from reading the
source.
This should give you enough information to get started with the InputReader of
your choice.
Input Reader Reference
As a reference here is a list of InputReaders and their parameters. All
InputReaders support the namespace parameter for specifying the namespaces to
iterate over. If no namespace is given then all namespaces are used
- namespace
- The list of namespaces that will be searched.
BlobstoreLineInputReader
Input reader for a newline delimited blob in Blobstore.
- blob_key
- The BlobKey that this input reader is processing. Either a string containing a single key or a list of blob key strings.
- start_position
- the line number position to start reading at.
- end_position
- The last line number position to read.
BlobstoreZipInputReader
Input reader for files from a zip archive stored in the Blobstore. Iterates over all compressed files in a zipfile in Blobstore.
- blob_key
- The BlobKey that this input reader is processing. Either a string containing a single key or a list of blob key strings.
- start_index
- the index of the first file to read.
- end_index
- The index of the last file that will not be read.
BlobstoreZipLineInputReader
Input reader for files from a zip archive stored in the Blobstore. Iterates over all compressed files in a zipfile in Blobstore. Each compressed file is expected to be a newline delimited file.
- blob_key
- The BlobKey that this input reader is processing. Either a string containing a single key or a list of blob key strings.
- start_file_index
- the index of the first file to read within the zip.
- end_file_index
- the index of the last file that will not be read.
- offset
- The by offset with `BLOB_KEY.zip[start_file_index]` to start reading.
DatastoreInputReader
Iterates over a Model and yields model instances. Supports both db.model and ndb.model.
- entity_kind
- the datastore kind to map over.
- keys_only
- use a keys_only query.
- batch_size
- the number of entities to read from the datastore with each batch get.
- key_range
- a range of keys to return from your query
- filters
- Any filters to apply to the datastore query.
DatastoreKeyInputReader
Iterate over an entity kind and yields datastore.Key.
- entity_kind
- the datastore kind to map over.
- keys_only
- use a keys_only query.
- batch_size
- the number of entities to read from the datastore with each batch get.
- key_range
- a range of keys to return from your query
- filters
- Any filters to apply to the datastore query.
FileInputReader
Iterate over Google Cloud Storage files using the Files API.
- files
- A list of filenames or globbed filename patterns. The format is `/gs/bucket/filename` or `/gs/bucket/prefix*`.
- format
- One of "lines", "bytes", "zip". "lines" reads the input file line-by-line, "bytes" reads the whole file at once and "zip" iterates over every file within the zip.
LogInputReader
Input reader for a time range of logs via the Logs API.
- start_time
- The earliest request completion or last-update time of logs that should be mapped over, in seconds since the Unix epoch.
- end_time
- The latest request completion or last-update time that logs should be mapped over, in seconds since the Unix epoch.
- minimum_log_level
- An application log level which serves as a filter on the requests mapped over.
- include_incomplete
- Whether or not to include requests that have started but not yet finished, as a boolean.
- include_app_logs
- Whether or not to include application level logs in the mapped logs, as a boolean.
- version_ids
- A list of version ids whose logs should be read. This can not be used with module_versions
- module_versions
- A list of tuples containing a module and version id whose logs should be read. This can not be used with version_ids.
NamespaceInputReader
An input reader to iterate over namespaces. This reader yields namespace names as string.
- namespace_range
- An alphabetic range for the namespace. As defined by [namespace_range.py](https://code.google.com/p/appengine-mapreduce/source/browse/trunk/python/src/mapreduce/namespace_range.py).
- batch_size
- The number of namespaces to read with each batch.
RandomStringInputReader
Yields random strings as output. Useful to populate output with testing entries.
- count
- The total number of entries this reader should generate.
- string_length
- The length of the generated strings.
RawDatastoreInputReader
Exactly the same as DatastoreInputReader but yields a datastore.Entity.
- entity_kind
- the datastore kind to map over.
- keys_only
- use a keys_only query.
- batch_size
- the number of entities to read from the datastore with each batch get.
- key_range
- a range of keys to return from your query
- filters
- Any filters to apply to the datastore query.
RecordsReader
Reads a list of Files API files in records format.
- files
- A comma separated string of files to read from.
Conclusions
Defining a MapReduce job via mapreduce.yaml provides a convenient way to
iterate over large datasets and run a function on each unit of work.
Unfortunately, running a MapDeduce job this way has a few limitations.
First, there is no way to specify a reduce phase, limiting the type of jobs we
can perform. Second, you cannot start a MapReduce job programmatically.
The next article in this series will show how to overcome these limitations using MapReduce Pipelines to programmatically control your API.