View all articles in the MapReduce API Series.
In the last article we examined how to run one-off tasks that operate on a large dataset using a mapreduce.yaml configuration file. This article will take us a step further and look at how to run a MapReduce job programmatically using the App Engine Pipeline API.
Running a Mapper Job Using the App Engine Pipeline API
MapReduce jobs are based on the App Engine Pipeline API for connecting together time-consuming or complex workflows. We can define a pipeline for our MapReduce job to connect each stage of the MapReduce flow to one another. Let’s start by defining a pipeline for our simple Touch job that will update the timestamp of every entity Kind we specify.
To create a pipeline we inherit from the Pipeline object.
from mapreduce.lib import pipeline
class TouchPipeline(pipeline.Pipeline):
"""
Pipeline to update the timestamp of entities.
"""
pass
Our pipeline requires a single run method. Within this method we set the specification of our map function and yield a Pipeline object.
from mapreduce.lib import pipeline
from mapreduce import mapreduce_pipeline
class TouchPipeline(pipeline.Pipeline):
"""
Pipeline to update the timestamp of entities.
"""
def run(self, *args, **kwargs):
""" run """
mapper_params = {
"entity_kind": "app.models.user.UserModel",
}
yield mapreduce_pipeline.MapperPipeline(
"Touch all entities",
handler_spec="app.pipelines.touch",
input_reader_spec="mapreduce.input_readers.DatastoreInputReader",
params=mapper_params,
shards=64)
In this piece of code we define a MapperPipeline and pass it the parameters used to initialize the pipeline. The map function is specified by thehandler_spec parameter and our InputReader is given by the input_reader_spec parameter. You’ll notice from our previous article on running a MapReduce job using mapreduce.yaml that the parameters passed here match the specification supplied by the mapreduce.yaml file in that article. In effect, we are looking at two different ways to define the same specification for a MapReduce job. The benefit of the pipelined approach here is that we can easily start our job programmatically by instantiating our Pipeline object and executing the start() method.
pipeline = TouchPipeline()
pipeline.start()
Executing this code will start the MapReduce job. You can view the progress at the URL /mapreduce, analagous to when starting the MapReduce job through the UI using mapreduce.yaml.
Adding a Reduce Step to Our MapReduce Job
The previous example uses a MapperPipeline to define a job that executes a map function on every entity of a certain Kind. What about reduce? For this we turn to the MapreducePipeline object. This object accepts parameters for a mapper_spec and a reducer_spec. We can use this pipeline to perform a full MapReduce job. To make this discussion concrete and generate some useable code let’s use a feature built in to the MapReduce library especially for testing, the RandomStringInputReader.
The RandomStringInputReader generates x random strings of y length. x and y are both parameters we can use to control the reader. We can use this reader to create an example application that counts the number of occurrences of each character found in a random string.
For example, given ten random strings 20 characters in length
nzkeasmekjwewmvxgdre
pczrbnzpacpwxpmiffgw
kwsufcunznnzwqmfbszu
gmmfhvikvexnamjorxod
hpaedhjzuziouxaplnmp
thurvybxiuxaskoxjvco
ovwbokvfjiuoawyavpbs
hymsucnolibdivisotrt
durcotpoydwvkvtyyudl
fujkmdenoexximucikfv
we want to find the total occurrences of each character.
(n, 9)
(z, 8)
(k, 9)
etc.
Performing this calculation using MapReduce implies a two step process. First, the map function will count the number of occurrences of each letter in a given string. Second, the reduce function will sum these numbers for all strings to find the final result.
Let’s start by setting up a MapreducePipeline object using the RandomStringInputReader reader as our input_reader_spec along with a skeleton map and reduce function.
from mapreduce.lib import pipeline
from mapreduce import mapreduce_pipeline
def character_count_map(random_string):
pass
def character_count_reduce(key, values):
pass
class CountCharactersPipeline(pipeline.Pipeline):
""" Count the number of occurrences of a character. """
def run(self, *args, **kwargs):
""" run """
mapper_params = {
"count": 100,
"string_length": 20,
}
yield mapreduce_pipeline.MapreducePipeline(
"character_count",
mapper_spec="app.pipelines.character_count_map",
mapper_params=mapper_params,
reducer_spec="app.pipelines.character_count_reduce",
input_reader_spec="mapreduce.input_readers.RandomStringInputReader",
shards=16)
We can use a standard RequestHandler to execute our mock MapReduce Pipeline.
import webapp2
class CountCharacters(webapp2.RequestHandler):
def get(self):
pipeline = CountCharactersPipeline()
pipeline.start()
Let’s flesh out our MapReduce template to actually count the characters in a string. To do so our map function will yield a tuple of (character, count) for each character encountered in our string and the number of times it was encountered. So for our input string nzkeasmekjwewmvxgdre we would yield (n, 1), (z, 1), (k, 2), and so on. We update our map function to do this work.
import collections
def character_count_map(random_string):
counter = collections.Counter(random_string)
for character in counter.elements():
yield (character, counter[character])
Each tuple returned by our map will be fed to the Shuffle stage of the MapReduce job. The Shuffle stage groups all the values having the same key before passing the result to the reduce function. For example, if we yielded (n, 1) during one execution of our map function and (n, 4) in another execution, the Shuffle stage would group these and pass n, [1, 4] as the parameters to our reduce function (for more information on Shuffle refer to Part 1 of this guide).
Our reduce function takes the list of values returned by the Shuffle stage and sums them.
def character_count_reduce(key, values):
yield (key, sum([int(i) for i in values]))
We now have a full MapReduce job that will count the occurrence of each character for a set of random strings. Running our pipeline shows the map, shuffle and reduce stages operating over our dataset.
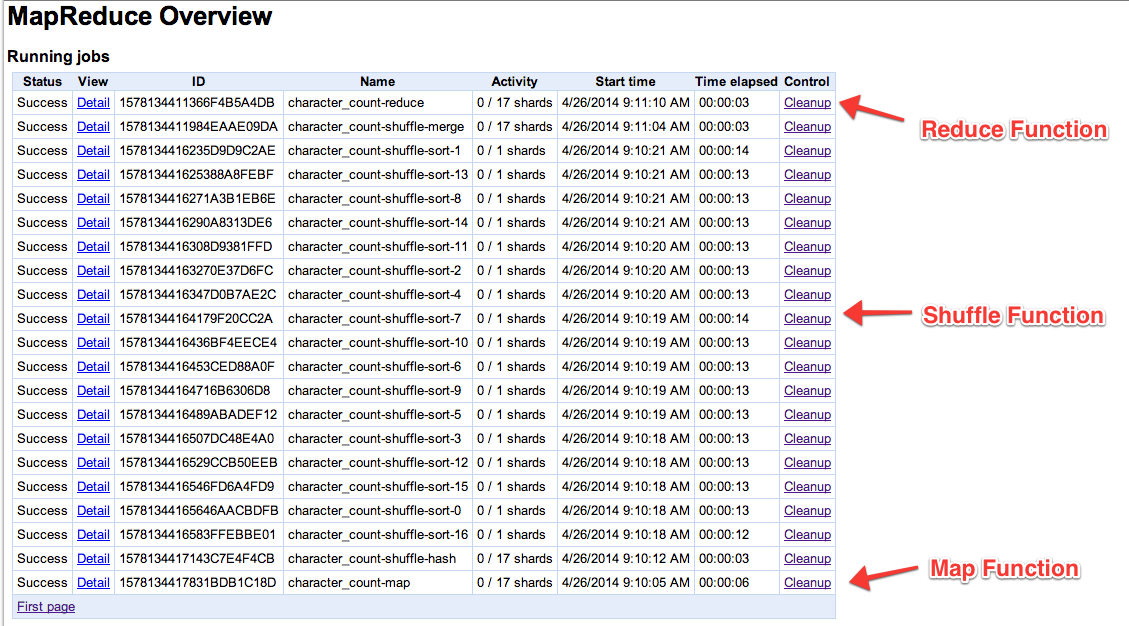
Where Is My Data?
How does the output of the map function arrive at the reduce function? If you look at the application logs you will see periodic writes to the blobstore.
Shard 1578130350583CAC16BCF-11 finalized blobstore file /blobstore/writable:RDlESEY4Q1U2UkRXT0pCVUpUTFQySlQ5VEJaTkJGUEpQS0RITVgzQ1lVREtKSzVUWTJVRlhTQjYwWFAzSE02OQ==.
Finalized name is /blobstore/7BpFYTPsvNp95XA2uS1MlBm1DsVegjTEO9EP6TAbXZAtsxV5C7HjuZmYnqPuXdJC.
These writes provide the blobstore location of the intermediate results from our calculation. A master MapReduce task coordinates with the individual map, shuffle and reduce shards to share these results via blobstore keys.
Writing our Results with OutputWriters
The last thing we need to finish our MapReduce job is outputting the result. To do so we add an output_writer_spec to our MapReduce initialization.
class CountCharactersPipeline(pipeline.Pipeline):
""" Count the number of occurrences of a character. """
def run(self, *args, **kwargs):
""" run """
mapper_params = {
"count": 100,
"string_length": 20,
}
yield mapreduce_pipeline.MapreducePipeline(
"character_count",
mapper_spec="app.pipelines.character_count_map",
mapper_params=mapper_params,
reducer_spec="app.pipelines.character_count_reduce",
input_reader_spec="mapreduce.input_readers.RandomStringInputReader",
output_writer_spec="mapreduce.output_writers.BlobstoreOutputWriter",
shards=16)
Unfortunately we don’t know where the BlobstoreOutputWriter saves our result. To access this we can capture the output of the MapreducePipeline.
class CountCharactersPipeline(pipeline.Pipeline):
""" Count the number of occurrences of a character. """
def run(self, *args, **kwargs):
""" run """
mapper_params = {
"count": 100,
"string_length": 20,
}
output = yield mapreduce_pipeline.MapreducePipeline(
"character_count",
mapper_spec="app.pipelines.character_count_map",
mapper_params=mapper_params,
reducer_spec="app.pipelines.character_count_reduce",
input_reader_spec="mapreduce.input_readers.RandomStringInputReader",
output_writer_spec="mapreduce.output_writers.BlobstoreOutputWriter",
shards=16)
yield StoreOutput(output)
output is a PipelineFuture object – a generator that takes on a value after the execution of the MapreducePipeline is complete. We can access the value of this generator from within a second pipeline object that writes the location of the blobkey to the datastore for future retrievals..
class CharacterCounter(ndb.Model):
count = ndb.StringProperty(required=True)
class StoreOutput(pipeline.Pipeline):
"""A pipeline to store the result of the MapReduce job in the database. """
def run(self, output):
counter = CharacterCounter(count=output[0])
counter.put()
This is a simplified version of the StoreOutput pipeline provided by the MapReduce Made Easy demo application.
Conclusions
In this article we’ve shown how to perform a full MapReduce job using the Google App Engine MapReduce API for Python. MapReduce is a powerful abstraction to use when processing large datasets. This article should provide a good starting point for defining and running your own MapReduce jobs. For reference here is the full source code used in this post.
"""
app.mapreduce
"""
import webapp2
import collections
from google.appengine.ext import ndb
from mapreduce.lib import pipeline
from mapreduce import mapreduce_pipeline
###
### Entities
###
class CharacterCounter(ndb.Model):
""" A simple model to sotre the link to the blob storing our MapReduce output. """
count_link = ndb.StringProperty(required=True)
###
### MapReduce Pipeline
###
def character_count_map(random_string):
""" yield the number of occurrences of each character in random_string. """
counter = collections.Counter(random_string)
for character in counter.elements():
yield (character, counter[character])
def character_count_reduce(key, values):
""" sum the number of characters found for the key. """
yield (key, sum([int(i) for i in values]))
class CountCharactersPipeline(pipeline.Pipeline):
""" Count the number of occurrences of a character in a set of strings. """
def run(self, *args, **kwargs):
""" run """
mapper_params = {
"count": 100,
"string_length": 20,
}
reducer_params = {
"mime_type": "text/plain"
}
output = yield mapreduce_pipeline.MapreducePipeline(
"character_count",
mapper_spec="app.pipelines.character_count_map",
mapper_params=mapper_params,
reducer_spec="app.pipelines.character_count_reduce",
reducer_params=reducer_params,
input_reader_spec="mapreduce.input_readers.RandomStringInputReader",
output_writer_spec="mapreduce.output_writers.BlobstoreOutputWriter",
shards=16)
yield StoreOutput(output)
class StoreOutput(pipeline.Pipeline):
""" A pipeline to store the result of the MapReduce job in the database. """
def run(self, output):
""" run """
counter = CharacterCounter(count_link=output[0])
counter.put()
###
### Handlers
###
class CountCharacters(webapp2.RequestHandler):
""" A handler to start the map reduce pipeline. """
def get(self):
""" get """
counter = CountCharactersPipeline()
counter.start()
redirect_url = "%s/status?root=%s" % (counter.base_path, counter.pipeline_id)
self.redirect(redirect_url)