We’ve learned how to execute and chain together pipelines, now let’s take a look at how pipelines execute under the hood. If necessary, you can refer to the source code of the pipelines project to clarify any details.
The Pipeline Data Model
Let’s start with the pipeline data model. Note that each Kind defined by the
pipelines API is prefixed by _AE_Pipeline, making it easy to view individual
pipeline details by viewing the datastore entity.
PipelineRecord
Every pipeline is represented by a PipelineRecord in the datastore. The PipelineRecord records the pipeline’s root identifier (if this pipeline is a child), any child pipelines spawned by this pipeline, the current status of the pipeline, and a few additional bookkeeping details.
At any point in time a Pipeline may be in one of four states: WAITING, RUN, DONE, and ABORTED. WAITING implies that this pipeline has a barrier that must be satisfied before the pipeline can be RUN. RUN means that the pipeline has been started. DONE means that the pipeline is complete. ABORTED means that the pipeline has been manually aborted.
SlotRecord
The output of a pipeline is represented as a Slot stored in the datastore as a SlotRecord. When a pipeline completes, it stores its output in the SlotRecord to be made available to further pipelines.
BarrierRecord
A BarrierRecord represents the slots that must be filled before a pipeline can execute. The barrier tracks blocking_slots that must be filled before the barrier can be lifted. Once the barrier is lifted a target pipeline is notified and the target can transition to the RUN state.
Barriers that depend on a slot being filled are stored in the BarrierIndex, which tracks barriers that are dependent on a slot. The purpose of the BarrierIndex is to force strong consistency when querying for a SlotRecord’s Barriers.
StatusRecord
The StatusRecord tracks the current status of a pipeline and facilitates the pipeline user interface. The StatusRecord is updated as the pipeline progresses to give a view of the current pipeline state. Not much more than that.
Pipeline Execution
Having an understanding of the pipeline data model gives a rough idea of how pipelines are executed. Each stage of execution corresponds to a webapp2 handler that services the request and advances the state of the pipeline. The following diagram shows each of the pipeline stages during typical execution and the description that follows provides more detail on each stage.
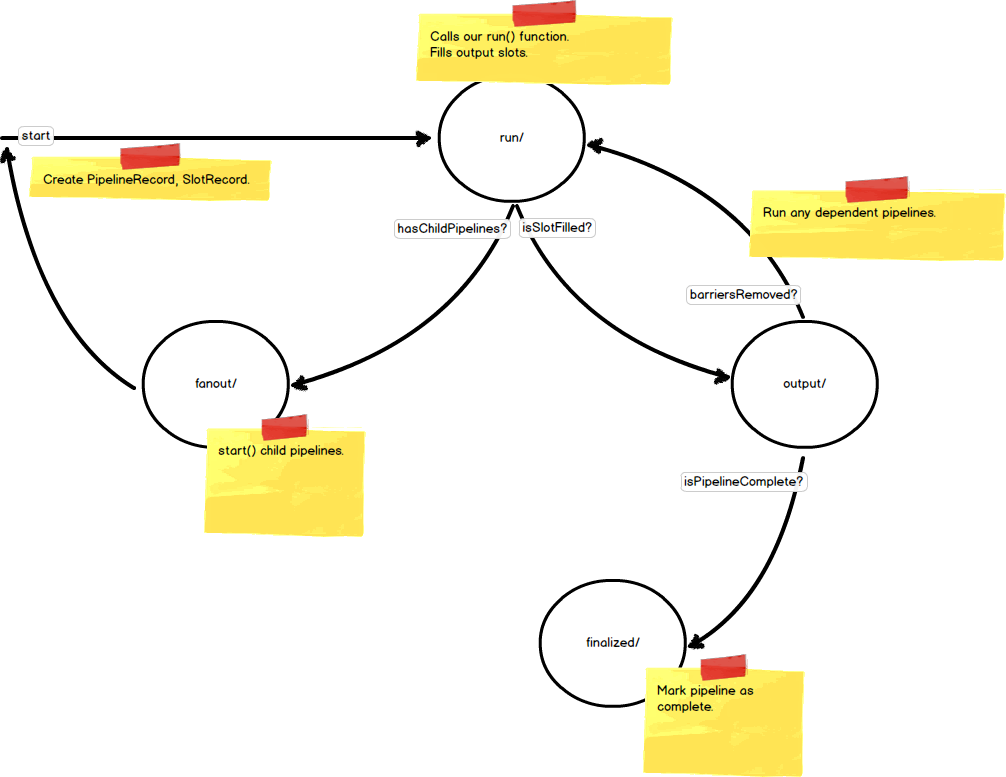
start()
A pipeline is started by calling its start() method. When calling start() a
PipelineRecord is created and marked as a RootPipeline, SlotRecords are
created for each of the pipelines outputs and marked as children of the
pipeline, and BarrierRecords are created corresponding to each of the output
slots of the pipeline. Finally, a task is queued to the /run handler to
execute the pipeline.
/run handler
The /run handler transitions the pipeline from the WAITING state to the RUN
state by setting a flag on the PipelineRecord, the pipeline object instance is
then reconstructed given the data from the request and the pipeline’s run()
method is called. When the run() method is complete, any outputs are used to
fill SlotRecords and yielded to the parent pipeline when necessary. Finally,
any child pipelines and their dependent slots and barriers are created and
marked as children of the parent pipeline. Calls to the /fanout
handler are made to queue tasks to start any child pipelines.
/fanout handler
The /fanout handler loads all child pipelines given a parent pipeline and queues
a task to the /run handler for each of them.
/output handler
Whenever a slot is filled a task is queued to the /output handler to notify any
barriers to a pipeline’s execution that they can be removed. If a pipeline has
all its barriers to completing removed, a task is queued to the /finalize handler
to mark our pipeline as complete. The /output handler queues tasks to the
/run method for any pipelines that have their barriers to starting removed.
/finalized handler
When the /finalized handler is called, the pipeline is marked as complete and
our pipeline’s finalized() method is called.
Conclusion
Understanding the Pipeline data model and run-time can help you to visualize and debug any pipeline problems. Stay tuned for the next article covering asynchronous pipelines.