From a DevOps perspective having a historical record of application logs can aid immensely in tracking down bugs, responding to customer questions, or finding out when and why that critical piece of data was updated to the wrong value. One of the biggest grievances with the built-in log handling of Google App Engine is that historical logs are only available for the previous three days. We wanted to do a little bit better and have logs available for a 30 day time period. This article outlines a method we’ve developed for pushing App Engine logs to an elasticsearch cluster.
A side benefit of this approach is that if you have multiple App Engine projects, all of their logs can be searched at the same time. This provides an immediate benefit when tracking down systems integration problems or parsing API traffic between applications.
The solution we chose for this problem revolves around the MapReduce API. If you need a refresher on this API please check out my MapReduce tutorial series.
Overview
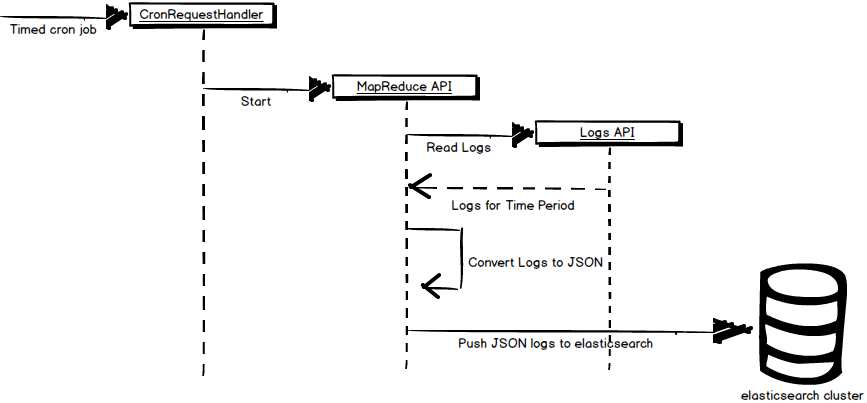
The gist of this solution is to run a MapReduce job that reads data from the App Engine Logs API using the LogInputReader, converts the data to a JSON format for ingestion into elasticsearch, and finally write the parsed data to the elasticsearch cluster using a custom MapReduce OutputWriter.
We execute this MapReduce job on a timer using cron to push logs to elasticsearch on a specific schedule. In our case, we run this job every 15 minutes to provide a relatively recent view of current operational data.
The following diagram presents the architecture of our solution.
Example
The majority of the solution is contained in a MapperPipeline. The following code illustrates how to setup the MapperPipeline. What’s remaining is to write a custom MapReduce OutputWriter that pushes data to elasticsearch and a function that converts a RequestLog object to JSON suitable for elasticsearch.
class CronHandler(webapp2.RequestHandler):
def get(self):
run()
def run():
start_time, end_time = get_time_range()
logging.debug('Dumping logs for date range (%s, %s).', start_time, end_time)
start_time = float(start_time.strftime('%s.%f'))
end_time = float(end_time.strftime('%s.%f'))
p = Log2ElasticSearch(start_time, end_time)
p.start()
class Log2Elasticsearch(pipeline.Pipeline):
def run(self, start_time, end_time, module_name, module_versions):
"""
Args:
module_versions: A list of tuples of the form (module, version), that
indicate that the logs for the given module/version combination should be
fetched. Duplicate tuples will be ignored.
"""
yield mapreduce_pipeline.MapperPipeline(
"vlogs-elasticsearch-injestion",
handler_spec="log2json",
input_reader_spec="mapreduce.input_readers.LogInputReader",
output_writer_spec="mapreduce.output_writers.ElasticSearchOutputWriter",
params={
"input_reader": {
"start_time": start_time,
"end_time": end_time,
"include_app_logs": True,
},
},
shards=16
)