
While microservices have become the defacto architectural pattern for building modern systems, they come with their own set of challenges. Key among them is ensuring application data consistency when data is spread over multiple databases. This article discusses one solution to this problem, distributed sagas. Distributed sagas provide consistency guarantees for systems spanning multiple databases in the face of failure using a clear and manageable implementation pattern. A saga is highly related to a finite state machines that moves consistently through a set of states, ensuring at each step that some conditions hold.
Credit to Caitie McCaffrey for introducing this idea. Make sure to watch the linked talk for more on distributed sagas.
Motivation
Imagine a simple application for booking a hotel. The user makes a request to a web frontend to book a room. The frontend forwards that request on to a hotel service. From here, the hotel service is responsible for two things: updating the booking information in their local database, and charging the user’s credit card using a third-party credit service.
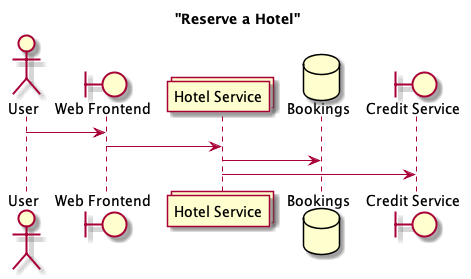
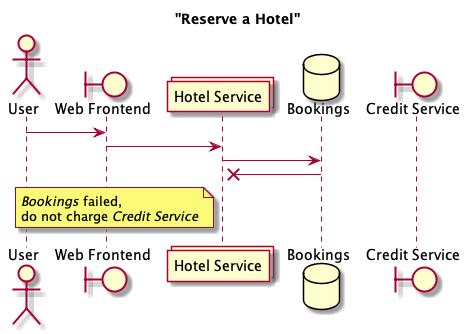
Immediately, we have a problem: it is up to the hotel service to guarantee consistency between the booking information in the Booking database and the credit card charge made to the Credit Service. One way to handle this handle this is to chain the requests to the two services so that we first ensure the Bookings database acknowledges that it stored the booking, and only then we make the request to the Credit Service to charge the user. If, for example, saving the booking to the Bookings database fails, we don’t charge the user’s credit card.
This is an example of feral concurrency control, where the application is responsible for maintaining data consistency between multiple systems. In terms of database design, the term feral implies that we have removed the responsibility for concurrency control from the database and placed it in the application. The paper Feral Concurrency Control: An Empirical Investigation of Modern Application Integrity examines this phenomenon more thoroughly by focusing on the common use of application-level mechanisms for maintaining database integrity.
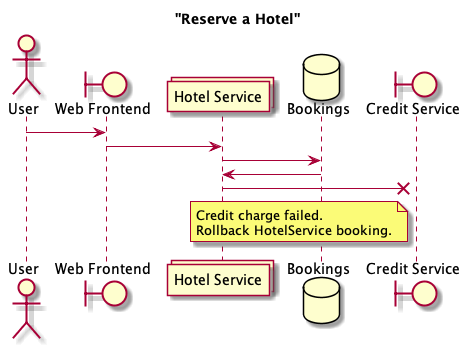
Another failure scenario in our example is that the booking succeeds but the charge to the credit card service fails. Here, you successfully book a hotel room in the Hotel Service, but the subsequent call to charge the customer’s credit card fails and you need to rollback the hotel booking. The application is responsible for maintaining the invariant that bookings must be charged to a credit card. This provides another example of feral concurrency control.
Our simple hotel service is gaining users at a rapid pace (and thanks to careful use of feral concurrency control we haven’t been charging customers for hotels they didn’t book). As the business grows, the product team comes to us with the additional requests to sell car rentals and flight reservations. Building in a microservice architecture, we develop a Car Service and Flight Service to handle these new features. Each of the services has its own business logic and writes data its own database before charging the customer using the Credit Service.
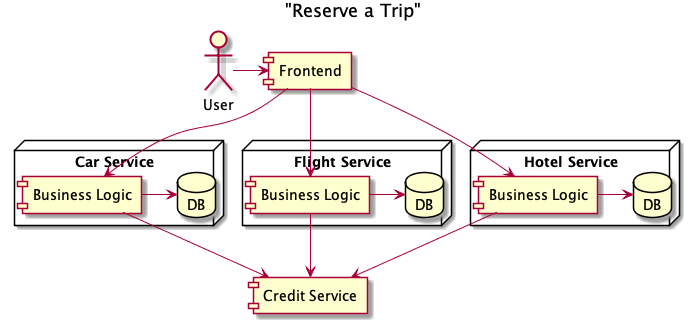
Now that we have all three services up and running, the next logical feature the product team wants to add is booking a trip — a flight, car, and hotel booked together as a package. The easiest way to extend our architecture is to add a new service to handle booking trips using our three existing services. What’s interesting now is that, from the perspective of the user, the trip is one logical transaction. Physically, however, the trip is made up of multiple independent transactions at each service.
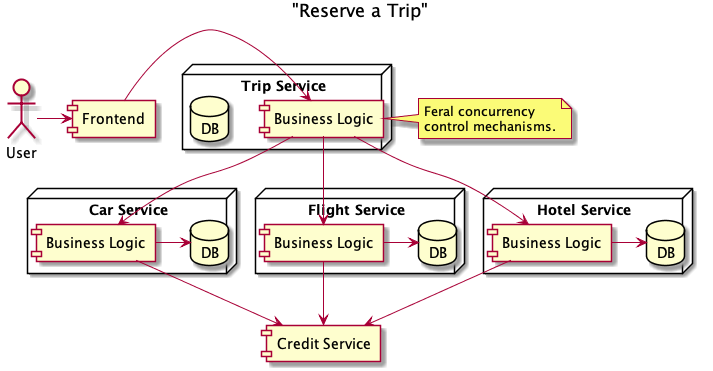
The Trip Service is a rich source of feral concurrency control. Within this service there are a lot more failure scenarios that need to be handled cleanly and a lot more business logic to make sure each dependent service remains consistent. For example, how do we handle the case where the request to book a hotel fails, but the request to book a car and a flight succeed? How do we make make sure that we cancel reservations that have already been made? How do we handle the case where the Trip Service goes down and we fail to notify the user that their trip was successfully booked? Will the user try again and double book each item of the trip? The Trip Service is responsible for implementing a transaction that chains together multiple services through API calls — we are operating on a single logical dataset, the trip, that is spread across multiple physical databases and microservices. How can we make sure our services remain consistent in the face of failures?
Sagas
In a single database, long-lived transactions can significantly delay the scheduling and termination of shorter transactions. A Saga provides a way to rewrite a long-lived transaction as a sequence of smaller transactions that can be interleaved.
The database management system guarantees that either all the transactions in a saga are successfully completed or compensating transactions run to amend a partial execution.
Sagas were introduced primarily as a performance optimization in single databases. For example, calculating monthly account statements, processing large insurance claims, or calculating statistics over an entire database can each lead to serious performance problems if large tables are traversed to compute an answer. If the DBMS locks the objects being accessed by a long-lived transaction until the transaction commits, other transactions will suffer delays. Long-lived transactions also have the potential to suffer many deadlocks and many aborts due to the need to traverse a wide range of the dataset.
A saga works by relaxing the requirement that a long-lived transaction be executed as a single atomic statement. Returning to our running example of booking a trip using the Trip Service, we can split the long-lived transaction, \(T\), for booking a trip into the smaller transactions of booking a car, \(T_1\), a flight, \(T_2\), and a hotel room, \(T_3\).
However, we do not wish to submit \(T\) to the database management system (DBMS) simply as a collection of independent transactions because we still want \(T\) to be a unit that is either successfully completed or not done at all.
If we were running the transaction \(T\) in a single database, we would not be satisfied if the DBMS allows you to book a car and a flight but fails to reserve the hotel room. However, we may be okay with a system that would cancel the car and flight on our behalf if it cannot book the hotel. This relaxed requirement on atomic consistency would still be useful for our application, and this relaxed atomic consistency is a requirement for a transaction to be written as a saga. To allow this relaxed consistency, each individual transaction \(T_i\) should be given a compensating transaction \(C_i\).
The compensating transaction \(C_i\) undoes, from a semantic point of view, any of the actions performbed by \(T_i\).
It’s important to note that a compensating transaction \(C_i\) does not necessarily return the database to the original state it was in before the transaction \(T_i\) was run. The compensation only needs to be semantically equivalent. Returning to our trip example, if the transaction \(T_i\) reserves a seat on a flight, then \(C_i\) cannot simply return the database to the original state that existed when \(T_i\) ran because other transactions may have altered the database during the executing of \(T_i\) and the compensating transaction \(C_i\). Rather, \(C_i\) would run a new transaction that cancels the effect of \(T_i\), returning it to a semantically equivalent state.
Given that each transaction \(T_i\) has a valid compensating transaction \(C_i\), then the saga implementation can make the following guarantee:
Either the sequence
\(T_1, T_2, \mathellipsis, T_n\)
(which is the preferable one) or the sequence
\(T_1, T_2, \mathellipsis, T_j, C_j, \mathellipsis, C_2, C_1\)
for some \(0 \le j \lt n\) will be executed.
Note that a compensating transaction may see the effect of a partial saga execution because each compensating transaction is run independently. Because of this, it is up to the user to design their compensating transactions to be idempotent. The implication is that the saga is composed of a sequence of relatively independent steps, where each step does not have to observe the exact same consistent database state to run successfully.
The key challenge in implementing sagas correctly is handling a failure that interrupts saga operation by executing compensating transactions to restore the semantic state of the database. So called backward recovery is handled by introducing a Saga Execution Coordinator (SEC) (sometimes called a Saga Execution Component). This coordinator relies on the existing transactional facilities provided by the database provided by a component called the Transaction Execution Coordinator (TEC). The SEC and TEC are similar in spirit — the SEC executes transactions as a non-atomic unit, and the TEC executes transactions as an atomic unit. Both the SEC and TEC require a write-ahead log implementation that records the activities of sagas and transactions and facilitates error recovery and rollbacks.
To execute sagas, all saga-related commands are first recorded in the write-ahead log before any action is taken. If, at any point, the saga receives an abort command, the SEC records that command in its log, and then instructs the native DBMS’s TEC to abort any currently running transactions. The SEC then consults its log to see which transactions have already been run by the saga, and begins running compensating transactions to semantically undo the saga. If the SEC itself crashes, the SEC reads back the status of the saga and of each transaction that makes up the saga, and either resumes execution of the saga from the failure point or executes compensating transactions to restore the data to a semantically valid state.
Up until now, the discussion has revolved around executing long-lived transactions in a single database. However, the problem we wish to solve is running transactions that span multiple databases. This can be implemented using distributed sagas, as described by Caitie McCaffrey.
Distributed Sagas
Distributed Sagas are a generalization of sagas from single databases to distributed systems. Whereas sagas execute long-lived transactions by breaking them into smaller transactions and compensating transactions, distributed sagas execute transactions that span multiple physical databases by breaking them into smaller transactions and compensating transactions that operate on single databases. Caitie McCaffrey discusses this protocol in an excellent talk that this article is based on.
Distributed sagas are implemented using processes that communicate via an asynchronous network. Distributed sagas come with a few preconditions that are required to overcome failure conditions inherent in asynchronous networks:
- individual transaction can abort, and must be idempotent.
- compensating transactions must idempotent, commutative, and they cannot abort (they must be retried indefinitely or resolved through manual intervention when necessary).
| Transactions | Compensating Transactions |
|---|---|
| Idempotent | Idempotent |
| Can Abort | Can Not Abort |
| Commutative |
Given these properties, we can implement a Saga Execution Coordinator (SEC) that provides a number of guarantees. In particular, we can guarantee that all transactions in a saga were completed successfully, or that a subset of the transactions and their corresponding compensating transactions were executed successfully. The saga will complete successfully or abort completely.
The paper on distributed sagas describes the implementation of an SEC along with some proofs that follow from the implementation. The implementation assumes that the SEC is run as a highly available service spread across multiple nodes, where each node may run concurrently. Since the SEC nodes can run concurrently, they must coordinate their work by storing the progress of a saga in a linearizable data store (i.e., a log), ensuring that each saga is executed sequentially. The flowchart implementation from that paper is reproduced here, with a sample successful execution of a saga highlighted.
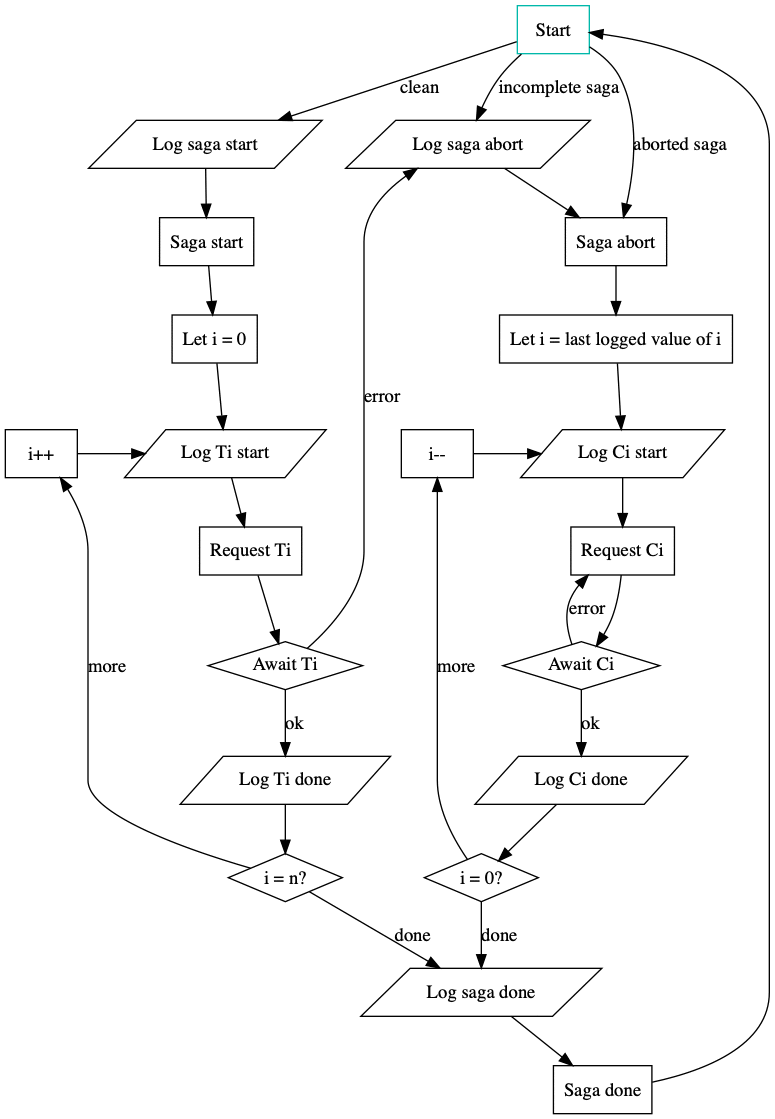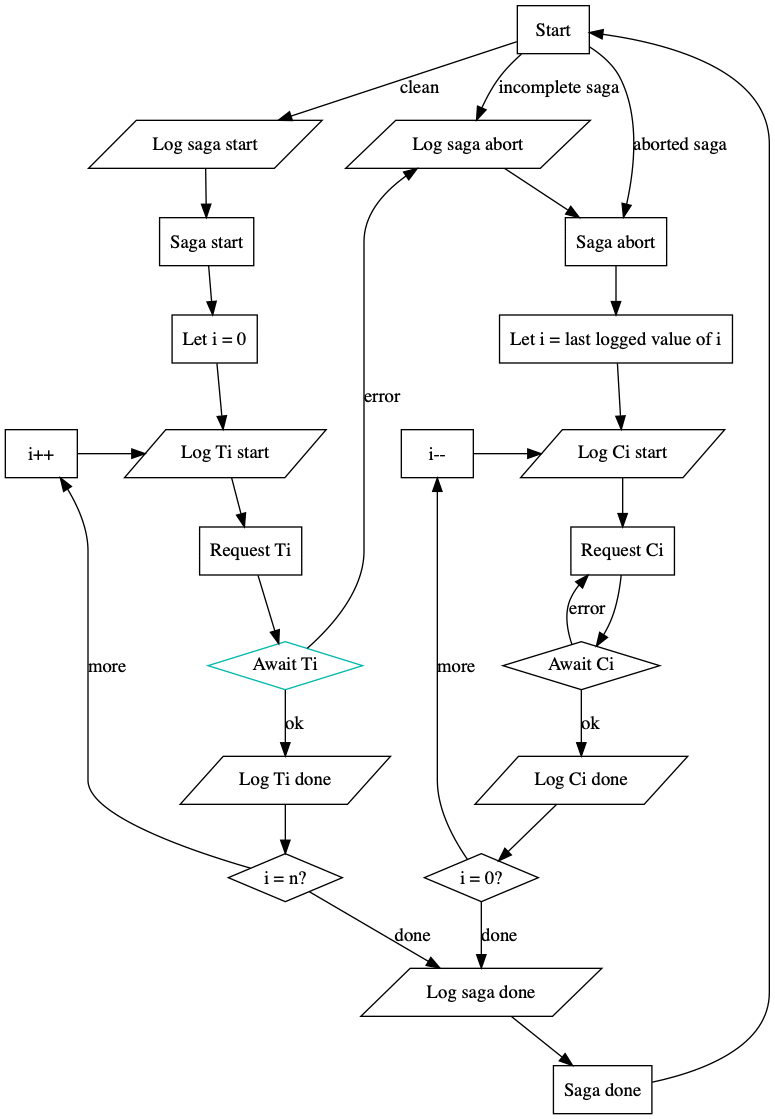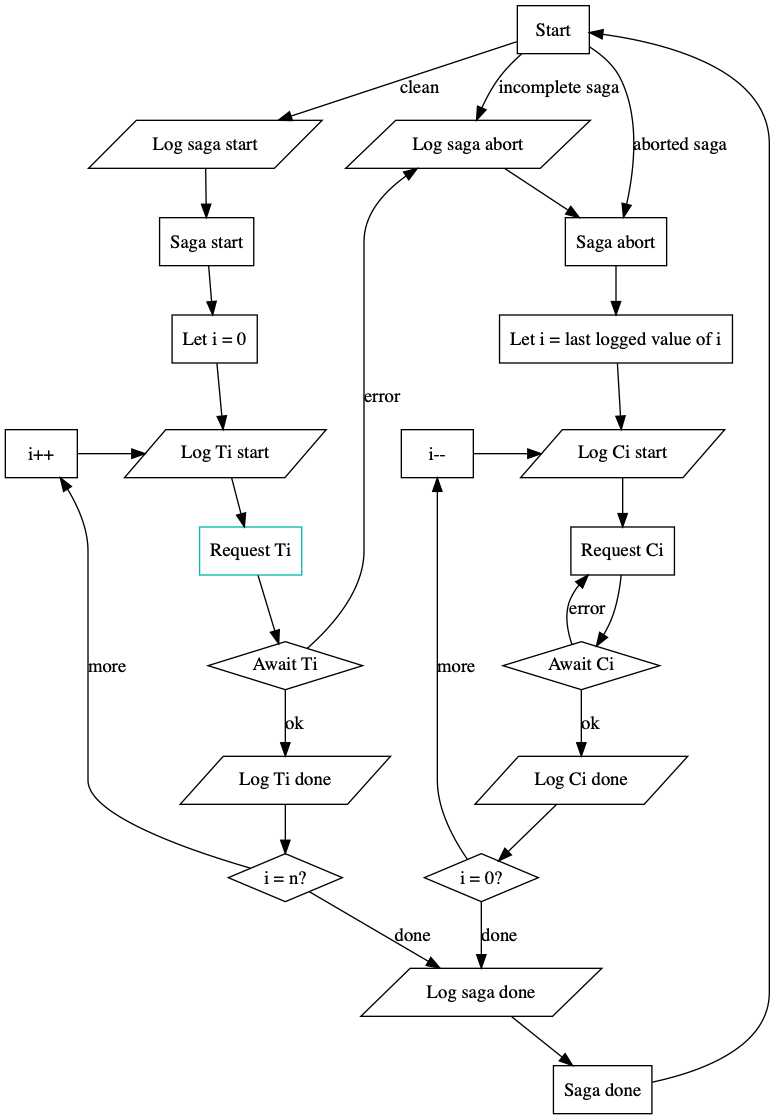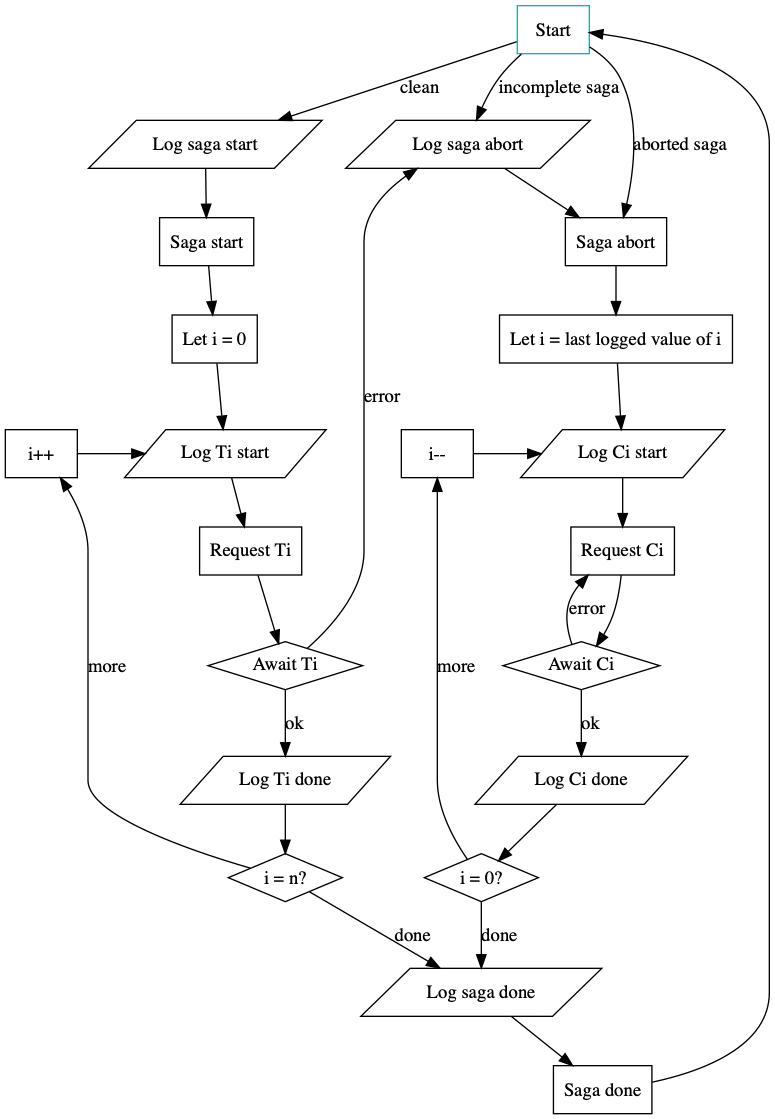
The successful execution begins by logging the start of the saga to a durable, linearizable datastore that is shared among all instances of the SEC. The “saga start” command is logged durably before the SEC begins iterating through the individual transactions that make up the saga. Likewise, before each transaction is executed, a “start transaction” entry is logged by the SEC so that if a transaction does not complete we know whether we need to rollback the transaction or retry it. This behaviour of logging intention before making any changes is a key method for ensuring database consistency developed by the ARIES project and proven through database implementations. As long as transactions continue to complete, the saga progresses forward until no more outstanding transactions remain. Finally, an “end saga” command is durably logged and the control loop exits to await the execution of new sagas or handle aborted sagas. The abort loop runs similarly, iterating through all outstanding compensating transactions and logging their progress as they are executed.
Example: Booking a trip using a Saga
Let’s return to our example of booking a trip and see how we can use distributed sagas to implement fault tolerance and guarantee consistency across multiple databases. Following the example set out by Caitie McCaffrey, we define our saga as a directed acyclic graph.
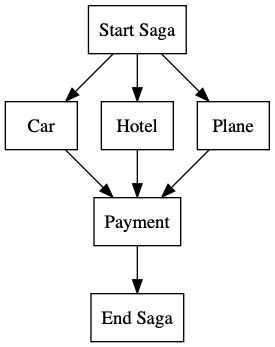
This graph defines the workflow for our saga where nodes can be executed only once all of their incoming edges (i.e. the node’s parents) have been executed. In this example, we can book the car, hotel, and flight in parallel and payment will be handled as a single step only once the car, hotel, and flight reservations have completed successfully. The status of each node is tracked by the saga execution coordinator to ensure that each node completes successfully or is rolled back on failure. Viewed this way, the implementation of the SEC is a breadth-first traversal of a directed acyclic graph.
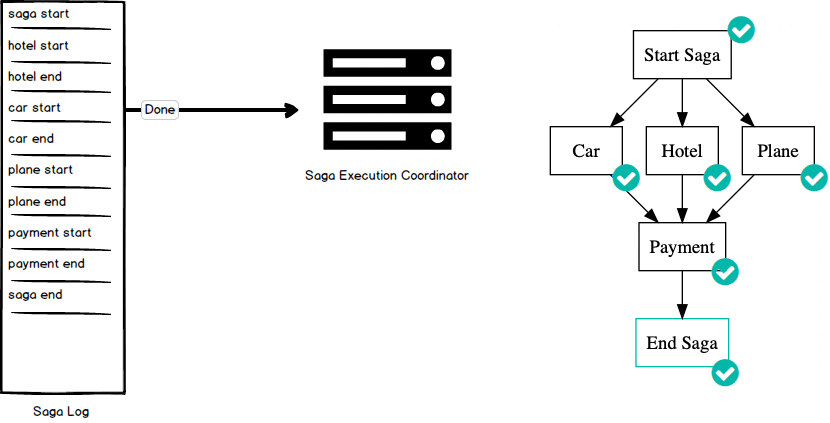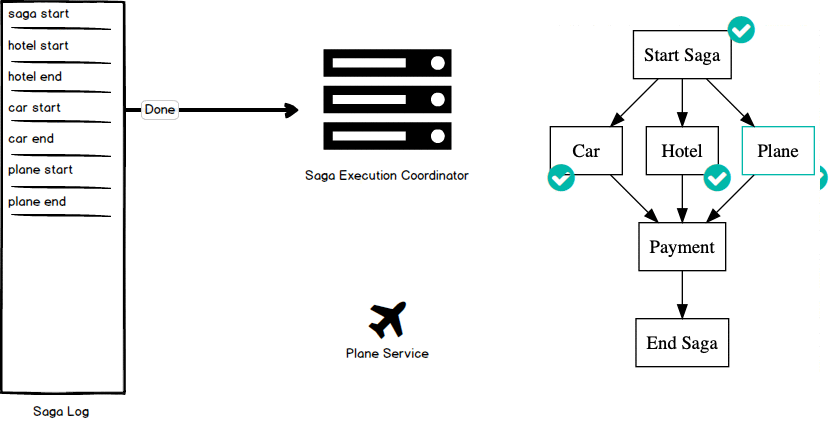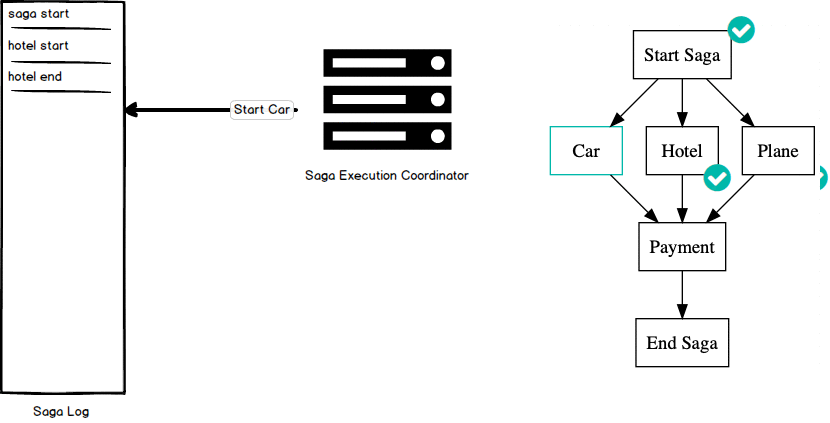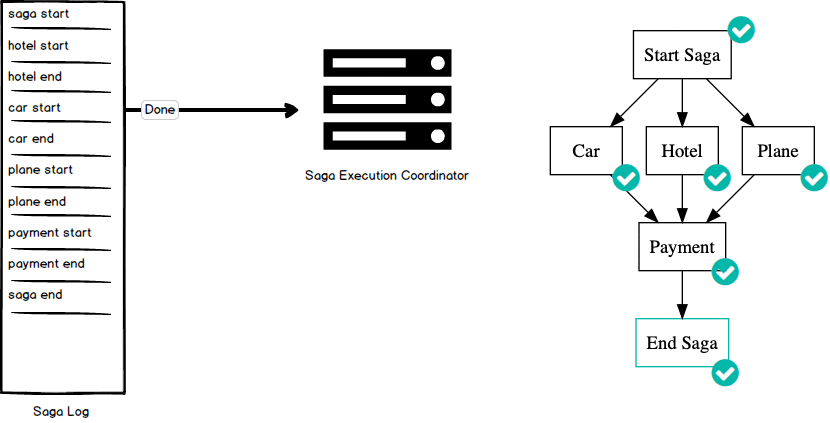
Let’s run through an example execution of this graph using the Saga Executing Coordinator. The SEC begins by writing a “start saga” command to its highly available log. You can include with this transaction any information necessary to successfully complete or debug the saga. Once the start saga command successfully completes, it implicitly marks that node in the graph as complete and the saga begins execution. Here, the SEC can execute any node in the graph that has a parent that is complete (even in parallel). For example, we can begin work on the Hotel node by writing a “start transaction” command to the log and executing the transaction to reserve a hotel. Once that request successfully completes, the SEC logs an “end transaction” command to mark that portion of the saga complete. Both the Car and Plane nodes can be executed since all of their parents are complete. Each of these nodes are executed in the same manner: log a “start transaction” command, execute the transaction, and on success log an “end transaction” command. Since all parents of the Payment node have completed, the SEC can now complete the payment by first logging a “start transaction”, executing the payment request, and logging an “end transaction” command. This concludes our saga execution and we can log an “end saga” command to signal saga completion.
Of course, not all executions of our saga will complete successfully. For example, let us suppose that our saga has progressed to the point where we have successfully reserved a hotel, but then the request to reserve a car has failed. In this case, we need to log an “abort saga” command to our highly available log. This triggers a rollback of the saga because we cannot guarantee that all requests have executed successfully. You can imagine now that the edges in the directed acyclic graph have been reversed, and we begin working backwards through the graph executing any necessary compensating transactions. The compensating transaction is executed in the same manner as the original transaction: log a “start of transaction” command, execute the compensating transaction, and log an “end of transaction” command. We continue traversing backwards through the graph until there are no more nodes to process, ensuring we have maintained our guarantee that any transactions that have been run during a failed saga execution have been compensated for.
Architecture of a System Using Distributed Sagas
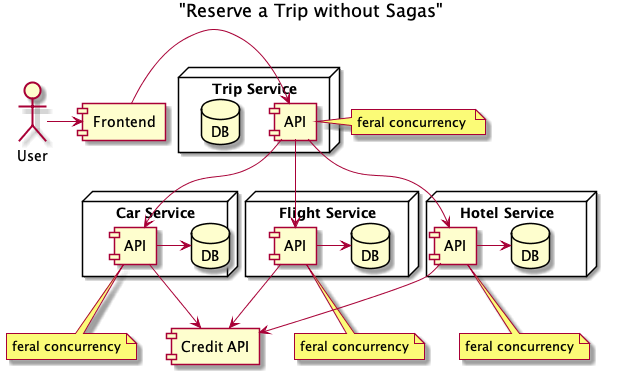
Let’s compare the architecture of our trip-booking system without and with sagas. Without sagas, we need to implement feral concurrency control within each of the services that make up the distributed transaction for booking a trip.
With sagas, we introduce a central point of coordination, the Saga Execution Coordinator, or SEC, and a highly available linearizable datastore to serve as a log of saga executions. This central coordination point implements concurrency control and fault tolerance on behalf of the dependent systems, so they don’t need to implement it themselves.
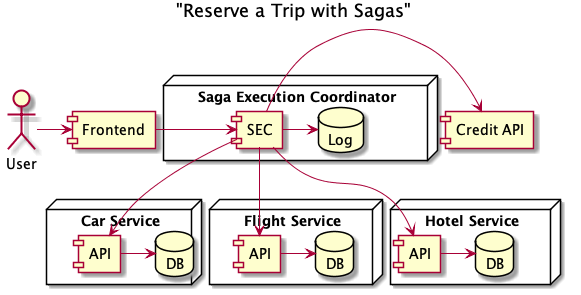
In this scenario, we remove the Trips Service altogether. In its place we define a new saga defining the workflow for reserving a trip and let the saga execution coordinator handle successfully booking a trip or rolling back any changes. All of our concurrency control logic is implemented by the SEC, and our business logic is encoded by the directed acyclic graph defining the saga. This approach isolates the complex code and business logic to one component of the system — the SEC. Removing the business logic and concurrency control from each of the individual services makes them easier to debug and maintain, and allows them to serve their single purpose well. A side benefit of the implementation is that each execution of a saga is durably persisted to a log. This is an excellent source of information for debugging and system maintenance.
Conclusion
One of the key problems in implementing distributed systems is ensuring data consistency across multiple independent services. This article presented one approach to solving this problem: distributed sagas. A distributed saga can implement fault-tolerance and data consistency in distribute systems by serving as a central point for coordination and error recovery, providing a robust building block for consistent distributed systems.