For the past year I’ve been making a concerted effort to learn French using the methods from the book Fluent Forever, which is an excellent resource for learning how to learn a language. For those not familiar with the method, it boils down to this:
- Learn Pronunciation: knowing how to correctly pronounce words in your target language makes everything else easier.
- Learn Frequently Used Words: not all words are created equal, learn the most frequently used words first.
- Learn Grammar: put together grammatical sentences using the words you already know.
If you turn your head to the side and squint at that list, it somewhat resembles the steps you would take to learn a language as an infant — first understand the sounds of the language, then learn words (“mommy”, “daddy”), and finally put together correct sentences. In addition, as an infant you have a constant source of high quality input helping you learn words and grammar. You can imagine the following “conversation” between an adult and a hungry child:
- “Tommy, do you want an apple?”
- “Apple?”
- (points at Apple)
- “Apple? Want Apple?”
- (points at Apple again)
- “Apple now?”
It won’t take long for that hungry infant to connect the word “Apple” to the object in front of them. This type of reinforcement works great for an infant, but as an adult we are forced to simulate it using frequent review. This is where a spaced-repetition program can help. If you aren’t familiar with spaced repetition, the simplified version is that you create flash cards and review them at the points in time that help you remember them the best. Spaced repetition software helps by computing the optimal time to review flash cards to help drive them in to long-term memory. The most flexible and feature rich program for spaced-repetition I’ve found is Anki, which I’ve been using with a lot of success to learn frequently used words.
Now, a particular thorn in my progress learning French is verb conjugations. I’m trying to resolve this thorn using Anki by finding grammatically correct sentences and creating flash cards from them. These cards ask you to find the root form of a verb, and the correct conjugated form that fits grammatically in the example sentence (for a full explanation of the method, see the Fluent Forever blog). To reinforce correct grammar and pronunciation, each sentence should ideally be accompanied by a recording of a native speaker speaking the sentence. Unfortunately, it’s not always easy to find a native speaker willing to record sentences for you — this is where Amazon Polly comes in.
Amazon Polly is a service that turns text into speech in a wide variety of languages and voices. By leveraging Polly, you can easily create quality examples of native speakers for learning a language. To help automate the creation of these recordings, I created a simple serverless web application that takes text as input, turns that text to speech using Polly, and stores the result in S3. The rest of this post describes this application. Full source code is available on Github.
Architecture
The API for this simple service exposes two endpoints. One for creating a recording, and a second for retrieving recordings. These endpoints are exposed through API Gateway and are backed by Lambda functions. The Lambda functions handle converting text to speech and storing that speech in S3. A DynamoDB table lists all the recordings and their locations in S3.
The following diagram shows the application architecture.
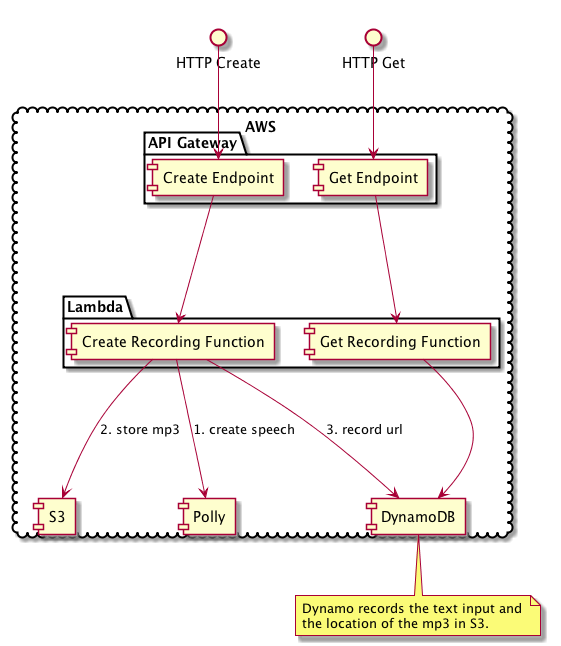
When the user wants to create a new recording:
- An HTTP call is made to the create endpoint exposed by API Gateway.
- API Gateway invokes a Lambda function responsible for converting the
text into speech and storing the result. The function performs the
following actions:
- Use Polly to convert text into an audio file.
- Store the result in S3.
- Store a record of the input text and the resulting mp3 file location in DynamoDB.
When the user wants to get an existing recording:
- An HTTP call is made to the get endpoint exposed by API Gateway.
- API Gateway invokes a Lambda function responsible for retrieving the record data from DynamoDB.
- The user uses the S3 URL returned by DynamoDB to download the mp3 file.
Now let’s walk through how to create the application using the Chalice serverless framework from AWS labs.
Creating The Backing Resources
Our serverless application relies on two AWS resources: an S3 bucket to store recorded speech, and a DynamoDB table to index the S3 url for the recorded text. Since I don’t want to keep these recordings forever, I set an expiration time of two days on all S3 objects in the bucket, and also configure a time-to-live for DynamoDB entries of two days. The following CloudFormation template creates the required resources:
---
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
S3BucketName:
Type: String
Description: "S3 bucket name"
MinLength: 4
MaxLength: 253
DynamoDBTableName:
Type: String
Description: "Dynamo table name"
MinLength: 4
MaxLength: 253
Resources:
TranslationsBucket:
Properties:
AccessControl: Private
BucketName: !Ref S3BucketName
LifecycleConfiguration:
Rules:
- ExpirationInDays: 2
Id: TranslationsBucketRule
Status: Enabled
Type: AWS::S3::Bucket
TranslationsTable:
Properties:
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
TableName: !Ref DynamoDBTableName
TimeToLiveSpecification:
AttributeName: expires
Enabled: true
Type: AWS::DynamoDB::Table
Outputs:
TranslationsBucket:
Description: S3 bucket storing translations.
Value:
Ref: TranslationsBucket
TranslationsTable:
Description: DynamoDB table indexing translations.
Value:
Ref: TranslationsTable
In the Resources section, we create TranslationsBucket of type
S3Bucket. The bucket includes a LifecycleConfiguration rule specifying
the expiration date of all objects placed in the bucket. The
TranslationsTable is a DynamoDB table with a simple id as the primary
hash key. The TimeToLiveSpecification lists the Dynamo attribute we will use to
expire records and enables TTL for the table. Note that Dynamo does not
require you to define a full schema ahead of time, you only need to
specify the key to start using the table.
You can deploy this CloudFormation template to create the required resources for our serverless application. Be sure to specify the desired name for your S3 bucket and for your Dynamo table.
aws cloudformation create-stack \
--stack-name polly-recorder \
--template-body file://cloudformation.yaml \
--parameters ParameterKey=S3BucketName,ParameterValue=<s3-bucket-name> \
ParameterKey=DynamoDBTableName,ParameterValue=<dynamo-table>
The Chalice Application
With our resources ready to use, we can create the Chalice application implementing our application. The following sequence of commands creates a new Chalice application:
$ pip install --pre chalice
$ chalice new-project polly-recorder && cd polly-recorder
$ cat app.py
You can then deploy and test the simple hello world example:
$ chalice deploy
...
Your application is available at: https://endpoint/dev
$ curl https://endpoint/dev
{"hello": "world"}
Create Endpoint
The create endpoint is responsible for synthesizing text into speech, storing the result in S3, and indexing the S3 URL in Dynamo for future retrieval.
Using Chalice, we define a route called recordings that accepts POST
requests. We also enable CORS support and require an API key for a minimal
layer of security. You can add the endpoint to app.py:
@app.route('/recordings',
methods=['POST'],
cors=True,
api_key_required=True)
def create_recording():
pass
Now we need to fill this out to implement the desired functionality.
VOICES = ['Celine', 'Mathieu', 'Chantal']
@app.route('/recordings',
methods=['POST'],
cors=True,
api_key_required=True)
def create_recording():
"""
Create a new recording.
"""
body = app.current_request.json_body
record_id = str(uuid.uuid4())
text = body.get("text")
voice = random.choice(VOICES)
synthesize_speech(record_id, text, voice)
url = upload_to_s3(record_id, S3_BUCKET)
item = index_in_dynamodb(record_id, text, voice, url, DYNAMO_DB_TABLE)
return [item]
This function starts by accessing the JSON body of the current request, available from the Chalice request metadata. From here, it extracts the text from the request, and converts that text to a randomly chosen French voice.
We can now implement each of the functions required to create a recording.
Synthesizing Speech
Synthesizing speech requires an API call to Polly with the text to synthesize, and the voice to speak with. We save the result to the Lambda functions temporary file system.
def synthesize_speech(record_id, text, voice):
"""
Synthesizes the text, writing the result to Lambda's temp filesystem.
"""
response = polly.synthesize_speech(
OutputFormat='mp3',
Text=text,
VoiceId=voice
)
output = os.path.join("/tmp/", record_id)
if "AudioStream" in response:
with closing(response["AudioStream"]) as stream:
with open(output, "a") as file:
file.write(stream.read())
Uploading to S3
We can now upload the result from the temporary file system to S3. After uploading, we set the file to be publicly readable so we can retrieve it later through a web interface.
def upload_to_s3(record_id, s3_bucket):
"""
Upload the tmp file to S3.
Returns the S3 URL of the uploaded result.
"""
s3.upload_file('/tmp/' + record_id,
s3_bucket,
record_id + ".mp3")
s3.put_object_acl(ACL='public-read',
Bucket=s3_bucket,
Key=record_id + ".mp3")
location = s3.get_bucket_location(Bucket=s3_bucket)
region = location['LocationConstraint']
if region is None:
url_begining = "https://s3.amazonaws.com/"
else:
url_begining = "https://s3-" + str(region) + ".amazonaws.com/" \
url = url_begining + s3_bucket + "/" + record_id + ".mp3"
return url
Indexing with Dynamo
Lastly, we can index the request and the S3 url in Dynamo for later
retrieval. We set the expires attribute to be two days in the future so
that Dynamo’s time-to-live feature will expire old recordings.
def index_in_dynamodb(record_id, text, voice, url, table_name):
"""
Index the record in DynamoDB.
Returns the Item.
"""
table = dynamodb.Table(table_name)
# Set the expiration for two days from now
posix_day = 86400
expire_time = long(time.time()) + 2 * posix_day
item = {
'id': record_id,
'text': text,
'voice': voice,
'url': url,
'created': datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'expires': expire_time,
}
table.put_item(Item=item)
return item
Putting this all together, we get the following Chalice file for creating a French recording of input text.
import os
import uuid
import random
import time
import datetime
from contextlib import closing
import boto3
from boto3.dynamodb.conditions import Key
from chalice import Chalice
app = Chalice(app_name='recorder')
app.debug = True
DYNAMO_DB_TABLE = <your-table-name>
S3_BUCKET = <your-bucket-name>
VOICES = ['Celine', 'Mathieu', 'Chantal']
dynamodb = boto3.resource('dynamodb')
polly = boto3.client('polly')
s3 = boto3.client('s3')
def synthesize_speech(record_id, text, voice):
"""
Synthesizes the text, writing the result to Lambda's temp filesystem.
"""
response = polly.synthesize_speech(
OutputFormat='mp3',
Text=text,
VoiceId=voice
)
output = os.path.join("/tmp/", record_id)
if "AudioStream" in response:
with closing(response["AudioStream"]) as stream:
with open(output, "a") as file:
file.write(stream.read())
def upload_to_s3(record_id, s3_bucket):
"""
Upload the tmp file to S3.
Returns the S3 URL of the uploaded result.
"""
s3.upload_file('/tmp/' + record_id,
s3_bucket,
record_id + ".mp3")
s3.put_object_acl(ACL='public-read',
Bucket=s3_bucket,
Key=record_id + ".mp3")
location = s3.get_bucket_location(Bucket=s3_bucket)
region = location['LocationConstraint']
if region is None:
url_begining = "https://s3.amazonaws.com/"
else:
url_begining = "https://s3-" + str(region) + ".amazonaws.com/" \
url = url_begining + s3_bucket + "/" + record_id + ".mp3"
return url
def delete_from_s3(record_id, s3_bucket):
"""
Delete a file from S3.
"""
bucket = s3.Bucket(s3_bucket)
bucket.delete_key(record_id + ".mp3")
def index_in_dynamodb(record_id, text, voice, url, table_name):
"""
Index the record in DynamoDB.
Returns the Item.
"""
table = dynamodb.Table(table_name)
posix_day = 86400
expire_time = long(time.time()) + 2*posix_day
item = {
'id': record_id,
'text': text,
'voice': voice,
'url': url,
'created': datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'expires': expire_time,
}
table.put_item(Item=item)
return item
@app.route('/recordings',
methods=['POST'],
cors=True)
def create_recording():
"""
Create a new recording.
"""
body = app.current_request.json_body
record_id = str(uuid.uuid4())
text = body.get("text")
voice = random.choice(VOICES)
synthesize_speech(record_id, text, voice)
url = upload_to_s3(record_id, S3_BUCKET)
item = index_in_dynamodb(record_id, text, voice, url, DYNAMO_DB_TABLE)
return [item]
We can go ahead and deploy our application:
$ chalice deploy
Update IAM Policies
The Lambda function deployed by Chalice will need to have access to the S3 bucket, the DynamoDB table, and to Amazon Polly. Set the policy on the Lambda execution role created by Chalice to include this access.
Testing Record Creation
You can deploy and test our recording function using
httpie by calling your endpoint. Substitute your
API gateway URL for <endpoint>:
$ http https://<endpoint>/dev/recordings 'text=Bonjour'
HTTP/1.1 200 OK
Access-Control-Allow-Headers: Authorization,Content-Type,X-Amz-Date,X-Amz-Security-Token,X-Api-Key
Access-Control-Allow-Origin: *
Connection: keep-alive
Content-Length: 247
Content-Type: application/json
Date: Fri, 28 Jul 2017 18:05:53 GMT
Via: 1.1 d9adada028fe3a04aed64f9ed9d80dd2.cloudfront.net (CloudFront)
X-Amz-Cf-Id: dN7O52phUUew64CLNMKNTkBFZNqmzuMVz6y0eCQV0dDGXDxh8wrvKw==
X-Amzn-Trace-Id: sampled=0;root=1-597b7d01-1fd4e99f39f639de71e5d034
X-Cache: Miss from cloudfront
x-amzn-RequestId: 651bfc48-73bf-11e7-95c2-a1560fa94d06
[
{
"created": "2017-07-28 18:05:53",
"expires": 1501437953,
"id": "3b0b048c-d0dc-449b-b385-7793a641e44c",
"text": "Bonjour",
"url": "https://s3.amazonaws.com/<s3-bucket>/3b0b048c-d0dc-449b-b385-7793a641e44c.mp3",
"voice": "Celine"
}
]
Get Endpoint
The create endpoint is fairly straightforward. We use Chalices’ URL
parameter functionality to specify a URL parameter called record_id. We
use that identifier to fetch the corresponding entry from DynamoDB and
return that to the user. For convenience, we use a record_id of * to
return all entries from the table.
@app.route('/recordings/{record_id}',
cors=True)
def get_recording(record_id):
"""
Get existing recordings.
"""
if record_id == "*":
# List all recordings
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(DYNAMO_DB_TABLE)
items = table.scan()
return items["Items"]
else:
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(DYNAMO_DB_TABLE)
items = table.query(
KeyConditionExpression=Key('id').eq(record_id)
)
return items["Items"]
Testing Recording Retrieval
We can use our get endpoint to retrieve recordings our recordings.
$ chalice deploy
...
$ http https://<endpoint>/dev/recordings/*
HTTP/1.1 200 OK
Access-Control-Allow-Headers: Authorization,Content-Type,X-Amz-Date,X-Amz-Security-Token,X-Api-Key
Access-Control-Allow-Origin: *
Connection: keep-alive
Content-Length: 18144
Content-Type: application/json
Date: Fri, 28 Jul 2017 18:05:00 GMT
Via: 1.1 86335fa0218c5bd3b89dc26ce10431df.cloudfront.net (CloudFront)
X-Amz-Cf-Id: xdXPN4jzxrkwtfAC00ZuFpnNHZ3U3ssTnCzubflcT_rkwTzowY8Fyg==
X-Amzn-Trace-Id: sampled=0;root=1-597b7ccc-13b475d72462df7b4a83012d
X-Cache: Miss from cloudfront
x-amzn-RequestId: 458b63aa-73bf-11e7-81ae-e3cf445a26c6
[
{
"created": "2017-07-27 21:27:55",
"expires": 1508966875.0,
"id": "1fb0e41b-8b0a-4c78-967d-fa72f56348c1",
"text": "test",
"url": "https://s3.amazonaws.com/<s3-bucket>/1fb0e41b-8b0a-4c78-967d-fa72f56348c1.mp3",
"voice": "Mathieu"
},
{
"created": "2017-07-27 21:43:57",
"expires": 1508967837.0,
"id": "7daded04-ea70-4244-899b-f862abd6318b",
"text": "test",
"url": "https://s3.amazonaws.com/<s3-bucket>/7daded04-ea70-4244-899b-f862abd6318b.mp3",
"voice": "Chantal"
}
]
User Interface
To help make generating example sentences a little easier, I created a simple user interface that accepts text and calls the API endpoints to store record that text as an mp3 file in S3 using our API.
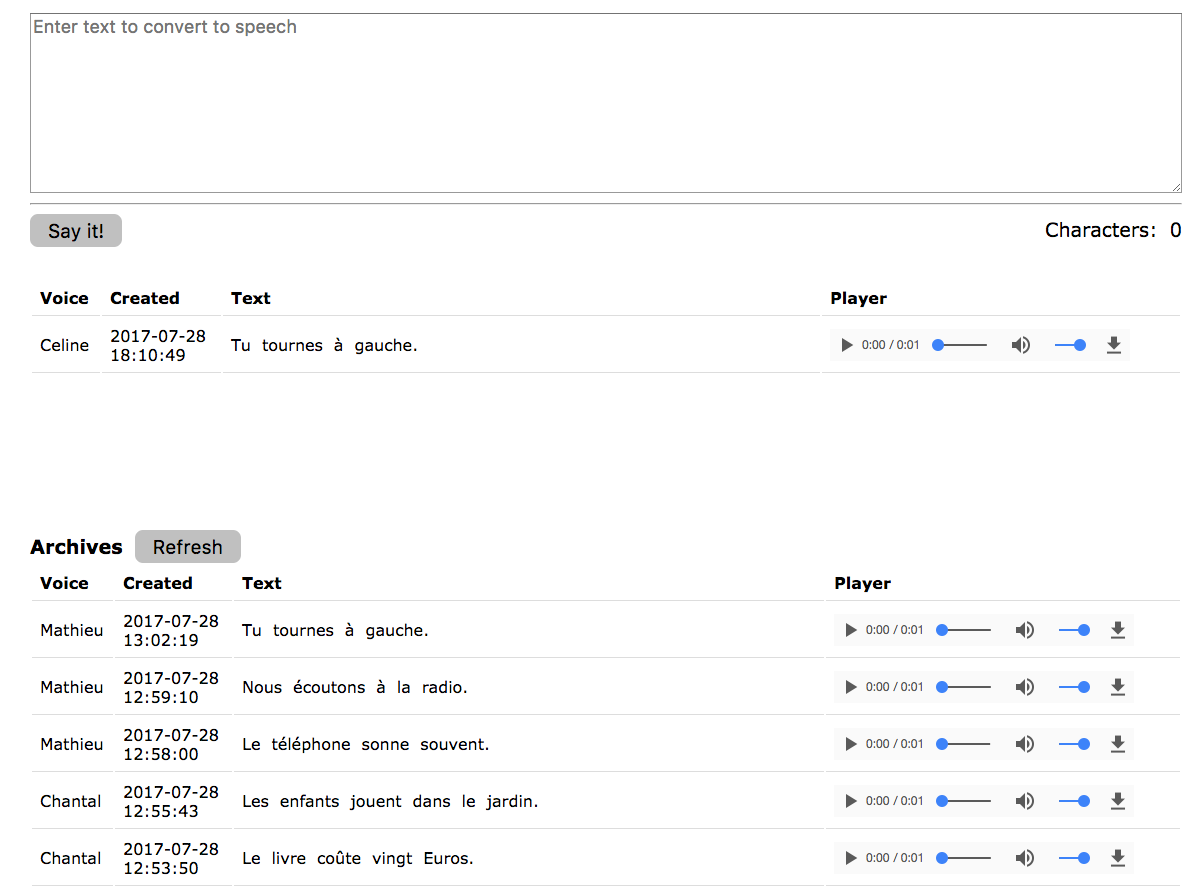
You can find the full source code for the interface on Github.
Summary
When starting this application I was skeptical that Polly would provide a natural expression of example sentences. Thankfully, I was quite surprised by the quality of the sentences. With the serverless application, I am now able to quickly create recordings of any French word or phrase to aid in language learning. Combining this with Anki for spaced repetition I’ve found a valuable resource for learning and recalling verb conjugations.