Writing correct programs is hard; writing correct concurrent programs is harder. Java Concurrency in Practice.
So, why bother with concurrency? A number of reasons:
- Concurrency provides a natural method for composing asynchronous code.
- Concurrency allows your program to avoid blocking user operations.
- Concurrency provides one of the easiest ways take advantage of multi core systems.
As processor counts increase, exploiting concurrency will be an even more important facet of high performance systems. Yet, before diving in to writing a concurrent program, it pays to understand the fundamentals of concurrency. To aid in such understanding, this article will provide background material on concurrency and an exploration of different methods for managing state and different models for writing concurrent program. The article is split into three main sections:
- Background: In this section I will lay the groundwork for understanding concurrency, including the difference between processes and threads, and the difference between concurrency and parallelism.
- Managing State: In this section I will present three primitive methods for managing shared program state. Each of these three methods can be used to write thread-safe code.
- Achieving Concurrency: In this section I will present several concurrency models and programming patterns that effectively manage shared state.
Concurrency is a complex topic and cannot be covered completely in a single article. Consider this a jumping off point for additional exploration depending on your needs. Examples in this article are presented in Scala and Go, though they should be easy enough to understand for anyone with programming experience.
1. Background
To fully understand complex topics, it helps to understand some history. To aid in this understanding, this article begins with a very brief history of concurrency.
A (Very Brief) History of Concurrency
In the beginning, computers did not have operating systems and were designed to execute a single program from beginning to end — each program had access to all of the machine’s resources. Over time, operating systems evolved to allow multiple programs to execute at once, each within a process — an independently isolated program that is assigned resources like memory, file handles, and security controls. Processes allowed computers to handle multiple users and multiple programs, better allocating its scarce resources.
The same factors motivating the development of processes motivates the development of threads. Threads allow multiple streams of execution within the same process. Each thread shares the process’s memory and file resources, and each thread has its own local variable space and program stack. Threads provide a natural mechanism for exploiting multiple processors by allowing multiple threads from the same program to be scheduled by the operating system simultaneously on multiple processors. In fact, most modern operating systems treat threads, not processes, as the basic units of scheduling.
With the advent of threads as the key unit of computation, the question of writing safe and performant concurrent programs now becomes a question of how to best exploit operating system threads within your programs. Exploiting threads effectively depends on the concurrency model supported by your programming language, framework, or runtime.
Let’s recap.
- Concurrency: Concurrency is the scheduling of work to happen over multiple processors (or multiple nodes in a system). Concurrency implies that each unit of work is continuously making progress.
- Parallelism: Parallelism happens when at least two units of work are executing simultaneously. It’s notable that you can support concurrency on a single processor system using appropriate scheduling, while parallelism requires multiple processors or systems.
- Process: A process is an instance of a computer program that is being executed. It contains the program code and its current activity. Depending on the operating system, a process may have multiple threads of execution running concurrently.
- Thread: A thread of execution is managed independently by a scheduler, which is typically a part of the operating system. Multiple threads can exist within one process, executing concurrently and sharing resources.
- Green Thread: Green threads are scheduled by a runtime library or virtual machine instead of natively by the underlying operating system. Green threads emulate multithreaded environments without relying on any native OS capabilities.
A key takeaway from this discussion is that threads scheduled across a single process allow for shared access to common resources. To write thread-safe code implies managing safe access to this shared state. The next section discusses several models for managing shared state.
2. Managing State
Concurrent programs are written by decomposing your program into computational units (typically threads) that are scheduled for execution by the language runtime or operating system. To write a thread-safe concurrent program requires each thread of execution respect the invariants of your programs state in one of three ways:
- By using synchronization when accessing mutable shared state
- By isolating state between threads
- By making state immutable
If every thread respects these rules, your program is thread-safe.
This section describes each of these three methods for respecting thread safety in your program. Depending on your programming language, runtime, or operating system, one or more of these methods may be available to you.
Synchronization
Synchronization provides methods for controlling access to mutable shared state by ensuring that only a single thread accesses state at a time.
To illustrate synchronization, here is an example of a class that is not
thread-safe. You can imagine this class tracking the number of requests
a web server has received. This class holds its state as a single variable
counter and offers methods to retrieve the current value using the
getCount method, and to increment the current value using the increment
method.
class UnsafeCounter {
private var counter: Long = 0
def getCount: Long = {
return counter
}
def increment {
counter += 1
}
}
This counter is not thread-safe. Why? Incrementing the counter with
counter += 1 requires three operations: first reading the value of
a counter, second adding a value to it, and third assigning the updated
value back to the counter. If two threads attempt to increment the counter
and due to unlucky timing are interleaved by the scheduler, each may read
the same initial value of the counter, leading to errors in subsequent
operations. Figure 1 shows how this can happen.
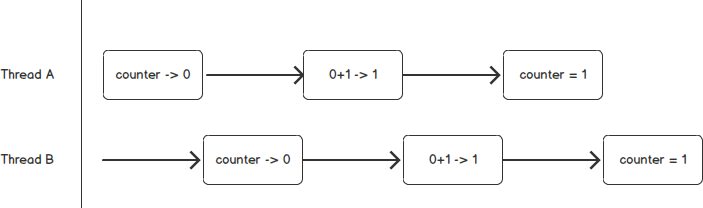
This example illustrates the common concurrency hazard of a race condition; the value returned by an operation depends on how the runtime interleaves threads. To solve this problem you must use synchronization, or locking, to signify that only one thread may access the data in a code block at a time.
class SafeCounter {
private var counter: Long = 0
def getCount: Long = {
this.synchronized {
return counter
}
}
def increment {
this.synchronized {
counter += 1
}
}
}
Without explicit synchronization, the compiler and runtime are free to arbitrarily order thread execution, cache variable values in registers or processor caches, and even to re-order statement execution for performance gains. The rule here is: whenever you need to check a value and then act upon that result, you must use synchronization to ensure safe state transitions.
Now imagine a NumberRange class that represents an interval of numbers.
In this example, you can adjust the interval by setting the upper and
lower bounds. The implementation takes advantage of Java’s concurrency
primitive AtomicInteger which provides synchronization for writing
values similar to what we just saw in SafeCounter — each get and set
call in the following code is thread-safe.
import java.util.concurrent.atomic.AtomicInteger
class UnsafeNumberRange {
private val lower: AtomicInteger = new AtomicInteger(0)
private val upper: AtomicInteger = new AtomicInteger(0)
def setLower(i: Int) {
if (i > upper.get) throw new IllegalArgumentException("Cannot set lower greater than upper")
lower.set(i)
}
def setUpper(i: Int) {
if (i < lower.get) throw new IllegalArgumentException("Cannot set upper less than lower")
upper.set(i)
}
def isInRange(i: Int): Boolean = {
i >= lower.get && i <= upper.get
}
}
Even though lower and upper are thread-safe, this class is not
thread-safe since it does not preserve the constraint that lower be less
than upper. Why? The entire compound action must be synchronized to
ensure atomicity of the operation and respect for the logical invariants
of the class.
import java.util.concurrent.atomic.AtomicInteger
class SafeNumberRange {
private val lower: AtomicInteger = new AtomicInteger(0)
private val upper: AtomicInteger = new AtomicInteger(0)
def setLower(i: Int) {
this.synchronized {
if (i > upper.get) throw new IllegalArgumentException("Cannot set lower greater than upper")
lower.set(i)
}
}
def setUpper(i: Int) {
this.synchronized {
if (i < lower.get) throw new IllegalArgumentException("Cannot set upper less than lower")
upper.set(i)
}
}
def isInRange(i: Int): Boolean = {
this.synchronized {
i >= lower.get && i <= upper.get
}
}
}
The rule here is: compound actions must be synchronized.
This section presented two different concurrency problems solved through synchronization. Dealing with synchronization issues in a shared-memory environment is challenging and whenever possible, should be avoided.
Thread Isolation
Since dealing with synchronization between threads is difficult, you should strive to isolate state to the thread itself whenever possible. That is, isolate state changes to a single thread. The methods for thread isolation are the same as those of object-oriented programming: use encapsulation to ensure state is accessed using appropriate synchronization.
In the following example, we create a collection of non-thread-safe
UnsafeCounter objects. Yet this class is thread-safe; the only access to
the non-thread-safe state is through a synchronized method call.
import java.util.Set
import java.util.HashSet
class CounterSet {
final private val set: Set[UnsafeCounter] = new HashSet[UnsafeCounter]
def addCounter(c: UnsafeCounter) {
this.synchronized {
set.add(c)
}
}
}
With this approach, care must be taken not to inadvertently publish data that is supposed to be kept isolated within the thread. For example, if we add a method to get a counter out of the set, that counter would not be thread-safe and access to it would require appropriate synchronization.
Immutability
Taking the approach of thread isolation to its logical extreme results in
immutable objects which have no data that can be changed; they are, by
definition, thread-safe. Immutable objects can be freely shared between
threads without worrying about synchronization. For example, an immutable
Point class can be represented as follows.
class Point(val x: Int, val y: Int) { }
Since the values of the Point cannot be changed, synchronization is not required. Whenever possible, design your data structures to be immutable.
3. Achieving Concurrency
Assuming that we have used synchronization, thread-isolation, and immutability to write thread-safe objects and methods, how can we compose a thread-safe program? This requires defining consistent policies for how threads in your program interact with one another. There are several methods for composing a thread-safe program and some may depend on the programming language, runtime, or operating system. You may also need to mix and match different models within a single program.
Synchronizers
The producer-consumer design pattern separates the identification of work to do from the doing of work; the producer thread adds work to a queue while one or more consumer threads process work from the queue. This design removes dependencies between producers and consumers and simplifies workload management. A typical implementation of a thread-safe producer-consumer is done using blocking queues. With this implementation, the blocking queue is the only means of communication between a producer and consumer. Java’s concurrent BlockingQueue provides an interface for coordinating queue operations in a thread-safe manner and can be leveraged to design a thread-safe program.

As a concrete example, you can imagine building a thread-safe indexing service that creates user objects from a file listing user names. Here, the producer is instantiated with a blocking queue and adds user names to the shared queue.
import java.util.concurrent.{BlockingQueue, LinkedBlockingQueue}
class Producer[T](path: String, queue: BlockingQueue[T]) extends Runnable {
def run() {
Source.fromFile(path, "utf-8").getLines.foreach { line =>
// insert a line of text into a shared concurrent queue
queue.put(line)
}
}
}
val queue = new LinkedBlockingQueue[String]()
// One thread for the producer
val producer = new Producer[String]("users.txt", q)
new Thread(producer).start()
The consumer takes items off of the queue, and creates user objects that are added to our index.
class Consumer(index: InvertedIndex, queue: BlockingQueue[String]) extends Runnable {
def run() {
while (true) {
// retrieve an item off of the queue for processing
val item = queue.take()
consume(item)
}
}
def makeUser(line: String) = line.split(",") match {
case Array(name, userid) => User(name, userid.trim().toInt)
}
def consume(t: String) = index.add(makeUser(t))
}
The take method on BlockingQueue will wait for an element to become
available before returning control back to the thread — it is a blocking
operation. The BlockingQueue implementation provides the internal
synchronization necessary to coordinate thread-safe access between the
producer thread and each consumer.
To complete our example, we can increase consumer throughput by running a pool of consumers that will each take work from the queue as it becomes available.
val cores = 8
val pool = Executors.newFixedThreadPool(cores)
// Submit one consumer per core.
for (i <- i to cores) {
pool.submit(new Consumer[String](index, q))
}
A blocking queue is an instance of the more general concept of synchronizer objects or synchronizers. A synchronizer is any object that coordinates the control flow of threads based on its state. In addition to blocking queues, many environments provide other synchronizers like mutex variables, semaphores, barriers, and latches. Each of these synchronizers can be used to provide thread-safe communication between threads.
Futures
A future represents an asynchronous computation that may be
executed on a separate thread. When you need to access the
result of the computation, you call a blocking get method to retrieve
its result. Futures hold the promise of a result that is not yet
complete. You can think of them as a container or placeholder for
a result.
val myFuture = SomethingVerySlow() // returns immediately
...
val result = myFuture.get() // blocks until SomethingVerySlow completes
Common examples of operations that can be represented using futures are a remote procedure call, disk I/O, or a long computation running on another thread. Note that each of these operations may fail, and thus a future can occupy one of three states: pending, failed, or succeeded.
Rather than creating a future and then getting the result directly, you may want to register callback functions that are invoked when results are available.
val f: Future[Int] = ???
f.onSuccess { res: Int =>
println("The result is " + res)
}
f.onFailure { res: Throwable =>
println("f failed with " + res)
}
Callbacks are useful, but futures provide the most power when they are
composable — when the result of one future is used as the input to a second
future, and so on. Future combinations let you express chained events of
asynchronous API calls naturally. For example, in the following code
we create a sequence out of two futures. The first future has a return
type of A and the function f uses that value to return a future of
type B. The flatMap operator provides the necessary plumbing to
combine these sequences.
def Future[A].flatMap[B](f: A => Future[B]): Future[B]
The result of this code is a future that will return the value of the entire sequence of asynchronous operations.
Futures are available in most programming environments and provide a simple and effective method for performing concurrent operations. Typically, these operations involve some form of I/O that you wish to perform asynchronously to increase the liveliness of your application.
Communicating Sequential Processes
Communicating Sequential Processes (CSP) is a mathematical formalism for describing interaction patterns in concurrent systems. Concurrency within a CSP system is achieved by allowing each process to operate independently, interacting with each other solely through message passing. This form of concurrency keeps each thread fully isolated and avoids the issues of sharing memory between threads by exploiting thread isolation. The Go programming language and the core.async Clojure library are designed around the CSP concurrency model.
At a high level, CSP provides two primitives for concurrent processing: events and processes. Events represent atomic interactions, while processes represent behaviours. Given these two primitives, CSP defines operators specifying how two processes are allowed to communicate. If a runtime correctly implements the CSP operators, programs running on the system can communicate safely using message passing.
In Go, message passing is handled explicitly through goroutines and channels. As a motivating example, we can imagine the problem of retrieving data from a list of URLs and adding the results to a shared data structure. In a traditional threading environment, this would require locking of the shared data structure. In Go, you can simply send output to the appropriate channel and the CSP implementation takes care of managing thread safety.
type Resource string
func Poller(in, out chan *Resource) {
for r := range in {
// poll the URL
...
// send the processed Resource to out
out <- r
}
}
Go implements the CSP model as part of the language runtime using green threads that are mapped to OS threads, allowing developers to succinctly express concurrent thread-safe programs that are not tied to a particular OS threading implementation.
Actor Model
The Actor Model assumes that all communication within the system is done by passing one way messages between actors.
Formally, each actor is restricted to:
- send a finite number of messages to other actors
- create a finite number of new actors
- designate the behaviour used for the next message it receives
Informally, you can treat actors like people who only communicate through snail mail. For example, imagine an Employee and their Boss. Each morning the Employee mails the Boss a status update, and the Boss replies back with a new list of items to accomplish that day. In this system, you can observe the following properties:
- Once the Employee sends the mail, it cannot be edited (Immutable)
- The Employee does not wait for the Boss to reply (Non-blocking)
- The Boss and Employee check their mailbox at arbitrary times
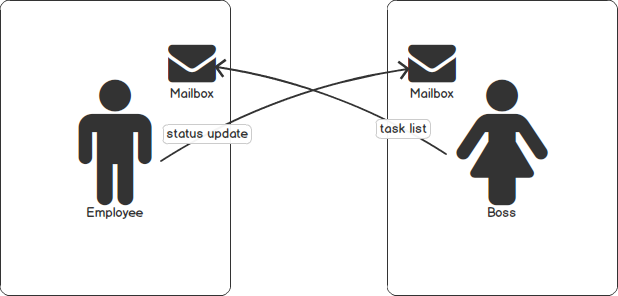
At its most basic, an Actor is defined to simply receive messages delivered to it:
import akka.actor.Actor
class BossActor extends Actor {
def receive = {
case StatusMessage => {
// process status update message
}
}
}
Scaling Actor Systems
Now, imagine scaling this system to support three employees and three bosses. The behaviour of each person does not need to change — each has their own mailbox to receive and respond to mail.
Actor models allow for scalability by restricting each actor to asynchronous and immutable “mail processing”. Given this restriction, a scheduling system is free to interleave actor execution without shared memory, and therefore without additional synchronization.
The actor model seamlessly scales horizontally as well — each message can be delivered to remote nodes without any change to actor behaviour.
Fault Tolerant Actor Systems
The actor model supports fault tolerance by arranging actors as part of a supervisor hierarchy. In this hierarchy, a supervisor watches actor processes for failure and restarts failed actors when necessary. By designing your system to account for failure of individual actors, the supervision mechanism will keep your system running regardless of individual failures.
The actor model has become popular as the realities of distributed systems engineering have surfaced. The model provides a simple programming abstraction that allows you to scale a fault tolerant service with minimal effort. One notable example comes from WhatsApp, who were able to support 900 million users with fifty engineers using the Actor model built into Erlang/OTP.
Software Transactional Memory
The problems of concurrency are problems of sharing access to common state. Thankfully, database researchers have formalized and implemented methods for sharing access to common data in the 1970’s, leading to the development and commercialization of the relational database — allowing millions of users to safely access data in a shared environment. The key method that databases use to ensure safe access is through transactions.
At any point in time, competing transactions are prevented from seeing any intermediate or inconsistent state through the use of appropriate record-level locks. If a transaction fails, it is typically retried until success, or aborted completely, with durability handled through the use of write-ahead-logging. Software transactional memory (STM) expands on database research to provide transaction support to language runtimes.
STM achieves concurrency via thread isolation — each transaction in your application can be viewed as a single-threaded computation with any deadlock or livelock issues handled transparently by the STM system. STM has the advantage that it supports programming abstractions such as objects and modules without the performance and cognitive overhead of explicit synchronization, allowing the programmer to write performant multi-threaded code using object-oriented program design.
Notably, Clojure has STM support built in to the core language and Haskell provides a STM as part of the Haskell Platform library.
Concurrent Baby Steps
At its core, managing concurrent execution involves managing access to shared state — either explicitly through locking and synchronization, or implicitly through a runtime system that supports concurrency. You can write a safe concurrent program by following one of these three practices:
- Using synchronization when accessing mutable shared state
- Isolating state between threads
- Making state immutable
The first practice, using synchronization, is the most powerful — it gives you complete control over when, where, and how synchronization is used in your program. Unfortunately, this power comes at great cost. Reasoning about concurrent programs using locking techniques is notoriously difficult. In almost all cases, use explicit synchronization as a last resort.
The second practice, isolating state, is a great way to add concurrency to an existing program. Go’s goroutine functionality and Java’s java.util.concurrent package provide simple methods for isolating concurrent access to a single thread. Futures are another easy way to add thread-isolated concurrency to your program.
The third practice, making state immutable, provides arguably the easiest way to reason about and maintain concurrent systems — it frees the programmer from thinking about shared state at all. The practice of developing with immutable state has gained traction over recent years through the use of functional programming. Functional programs that depend on immutable state can be easily distributed across multiple threads or even nodes in a cluster.
If you are developing a new system, take the time to think about your needs for concurrency and parallelism and how they can best be addressed. Is concurrency important to your application? Is there a concurrency model that is a natural fit for your problem domain? Can you leverage existing libraries and frameworks? Can your program leverage immutable state or functional programming?
Remember that it is far easier to build concurrency into your program from the beginning than to add concurrency to an existing program. The time taken to understand how concurrency affects your program’s safety, scalability, and fault tolerance is time well spent.