What if you could deliver more value, with more speed and with more stability?
What if you could triage bugs faster?
What if you could fix bugs easier and with less user facing impact?
You can, with continuous delivery.
Terminology
First, some terminology. What distinguishes continuous integration, continuous deployment and continuous delivery? Continuous integration revolves around the continuous automated testing of software whenever change to the software is made. Continuous deployment is the practice of automatically deploying any change to the code. Continuous delivery implies that you can deploy any change to production but for any number of reasons you may choose not to. The focus of this article is on continuous delivery.
What is continuous delivery?
Continuous delivery is a set of development practices that allow you to release software to production at any time (Fowler, 2014). By following these practices you can reduce the cost, development time and risk of delivering features to users (Humble, 2014).
Let’s expand upon these definitions by talking about what differentiates continuous delivery from traditional software development. With continuous delivery, at any point in time any stakeholder in the business can ask for the current version of the software to be deployed to production. This implies that your software is deployable throughout the development lifecycle and that the development team prioritizes keeping the software stable and deployable over working on new features (Fowler, 2014). It also implies some level of testing and deployment automation.
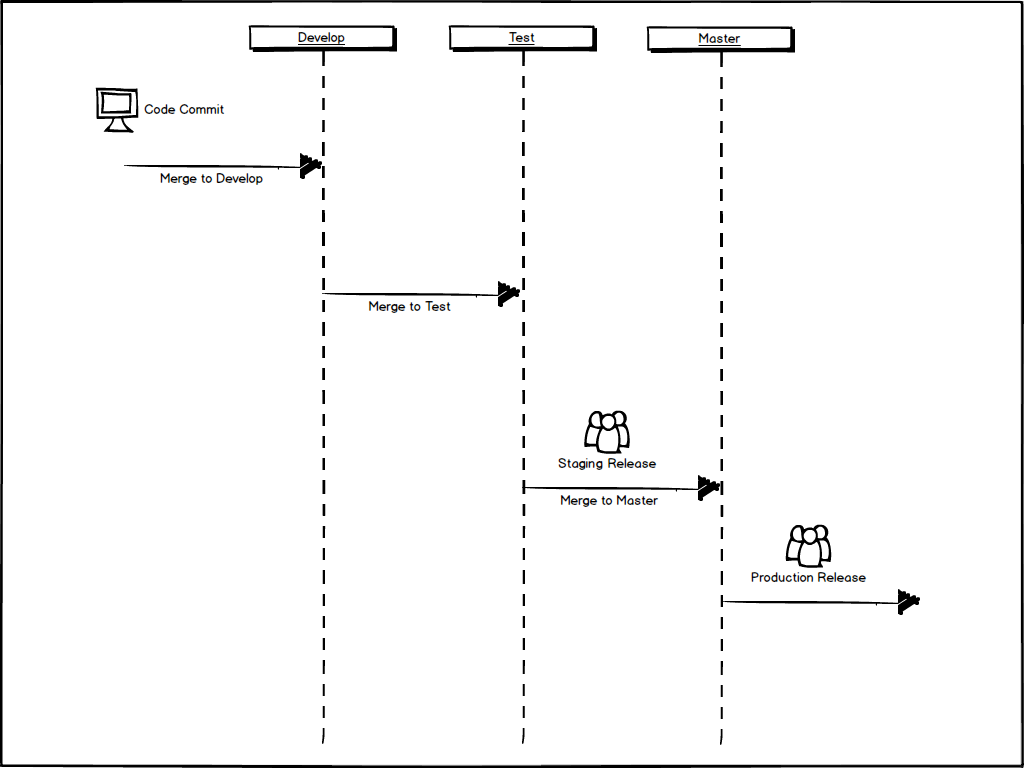
The following diagram of the continuous delivery process helps to visualize the automation steps that typically accompany a software change and the subsequent release of the software to production. The red bars in the diagram signal that failures at this stage of the process halt the entire process.
First, the delivery team or development team makes a change and commits that change to a version control system. This check in triggers automated unit tests that verify the commit. If those unit tests pass, automated acceptance tests run and if those pass we move on to manual user testing. Once the user has tested and approved the change a release can go out. From a development standpoint it is important to understand that any code commit that passes testing may be released to customers at any point in time.
Why Continuous Delivery?
Google, Facebook, LinkedIn, Netflix, Etsy, Ebay, Github and Hewlett-Packard, among many others, have adopted continuous delivery in their products. On average, Amazon makes changes to production code every 11.6 seconds (Jenkins, 2011) – that’s 3000 production deployments every day. Facebook commits to master 5000 times a day deploys to production twice a day (Rossi, 2011). Etsy deploys more than 50 times a day (Miranda, 2014). Why would companies do this? What is the benefit?
Reduced Risk
The first benefit is reduced risk. Each deployment is a smaller change that can easily be understood in isolation. If an error occurs it is trivially easy to roll-back a single change or push a new release on top of the change.
Believable Progress
Developers are generally quite bad at estimating software delivery projects ([Milstein, 2013][Milstein2103]). If the definition of “done” means “developers declare it to be done” that is much less believable than if it’s safely deployed into a production environment.
Faster Iteration Towards Product Fit
Generally speaking, the biggest risk in software development is building something that the user doesn’t want. Continuous delivery is a great enabler of A/B testing and allows you to frequently get working software in front of real users to assess user behaviour and performance impact of software changes.
Expose Inefficiencies
Continuous delivery enforces discipline on the software development team to always keep the product in deployable condition. This discipline naturally exposes inefficiencies in the development process – anything that gets in the way of the goal of releasing working software quickly is an impediment to development that will quickly be brought to light with continuous delivery.
Encourage Responsibility
With continuous delivery, the developer making a change and the developer deploying the code is the same person. This avoids any problems with handing your deployment ‘over the wall’ and allowing another person or team to test, deploy and verify the code. It keeps the onus on working software with the people most knowledge about how the software works.
Does Continuous Delivery Actually Work?
Rather than reflect on a few abstract benefits, let’s look at some of the available data on continuous delivery.
ThoughtWorks (Humble, 2014) analyzed their data on high performing companies and found that those practicing continuous delivery ship code 30 times faster, have 50% fewer failed deployments, and restore service 12 times faster than their peers.
In A Practical Approach to Large-Scale Agile Development (Gruver, 2012). Hewlett-Packard, who had been practicing more traditional software delivery process, experimented with continuous deployment in an organization having roughly 400 developers working over 3 continents. After switching to continuous delivery, they integrated small changesets over 100 times a day and deployed at least ten times a day. What happened? The number of features under active development increased by 140% and development costs per feature reduced by 78%. This amounted to a total development cost reduction of 40%.
How to do Continuous Delivery?
At this point, you may be sold on the benefits of continuous delivery and are asking how to get started. Continuous delivery requires a few components to be effective.
1. Continuous Integration
A build server performing continuous intergration of every commit is a necessity. Once a code change is committed, the build server triggers the testing and deployment pipeline ultimately leading to successfully deploying a production release.
2. Automated Testing
Automated unit testing, and, where applicable, automated performance testing, makes it easy to spot issues in code about to be deployed. If any of these tests fail the current release is rejected. This is not a silver bullet. Manual QA is still needed to verify a build and test before releasing.
3. Feature Flags
Some features are too big to commit as one chunk. In these cases a feature flag is used to hide functionality that is not ready for general release, while still allowing code to be released to production.
4. Monitoring
Monitoring systems allow the development and test teams to easily see the effect a given change has on user behaviour, system performance or system stability.
5. “One-Click” Deployment and Roll-Back.
Deployments and roll-backs must be easy enough for anyone to do at a moments notice.
Continuous Delivery in Practice
Let’s run through three examples of how continuous delivery would look like in practice, contrasting continuous delivery with a more traditional release process. In these examples, the traditional release process assumes that any changes scheduled to be released are held in a development environment for one week, a staging environment for one week, and finally deployed to a production environment after one week on the staging environment. Each envrionment corresponds to a unique code branch (develop, test, master) and weekly merges take place to push the development code up to the test branch (and staging environment) and the test code up to the master branch (and production environment).
Scenario 1: Bug Fix
Imagine a scenario where a customer reports a bug in the system. The bug is simple enough for a single developer to work on and the fix is small enough to understand within a single code commit. Let’s begin by examining the traditional release process to see how this bug fix reaches the customer.
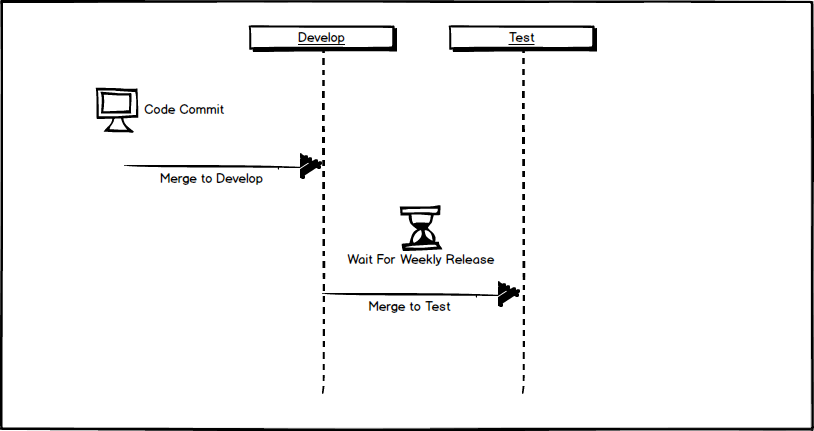
The developer, Brad, begins by checking out the latest copy of the development branch, and begins work on the bug. Once he is confident that the bug has been fixed he goes over the changes with QA and merges the bug into the develop branch where it waits for the weekly deployment to test.
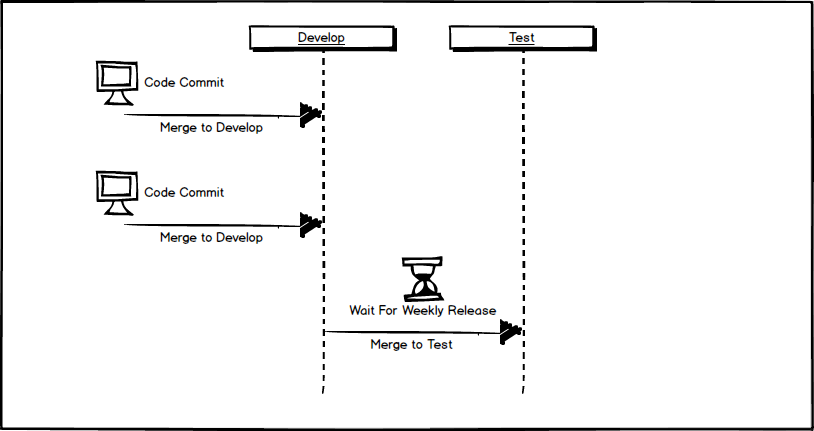
Brad is now free to pick up another issue and commit the code for that issue to develop, where it waits once again for the weekly deployment to test. Test now has two issues that have been committed to development that will be released to the test environment in one week.
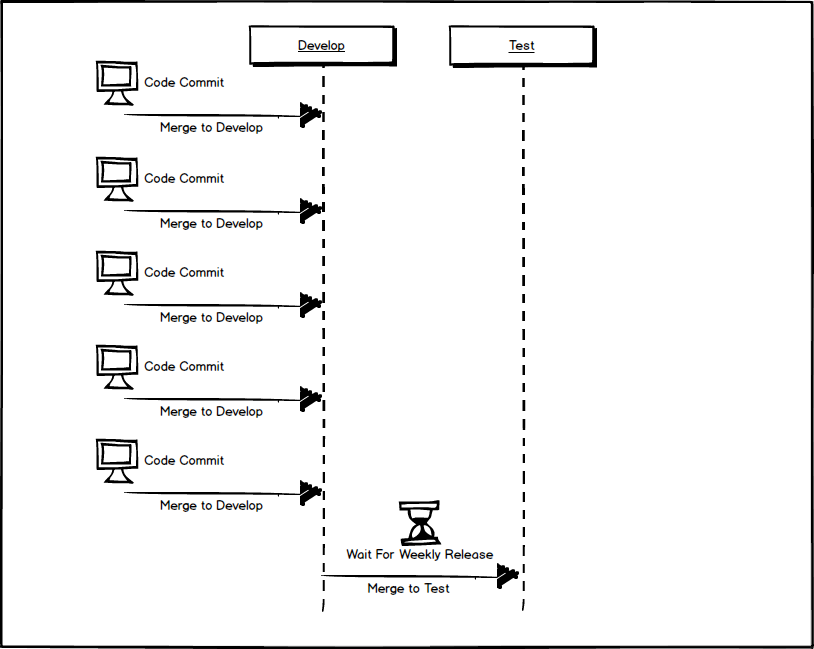
Meanwhile, other developers are working on issues and committing the code to develop. By the time the weekly deployment to the testing environment comes around we end up with 13 disparate issues being pushed to the test environment.
Now, the QA team can perform regression testing of all of these 13 issues for the week that this release is held in the test environment for staging. After one week has passed, the test branch is merged with the master branch and a deployment to production is done.
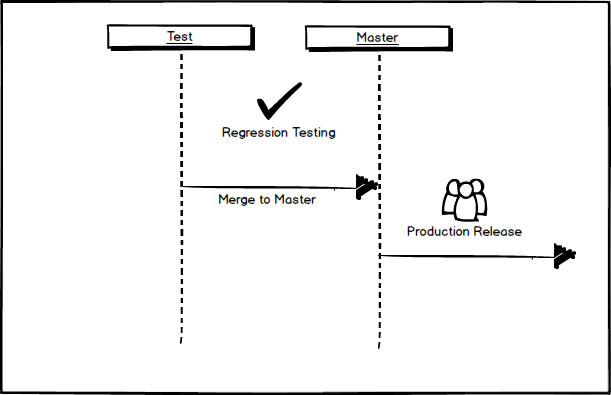
It’s also important to note that we still do not know that the bug fix will address the customer’s issues on production. We can’t know for sure that the bug fix not complete until it fixes the issue on the production environment. So, after the release a prudent developer will check back to make sure the bug is no longer an issue and it can be marked as resolved.
At this point we delivered the bug fix to the customer after a two week waiting period. We also dedicated testing time to this bug fix before merging it to the development branch, to regression test the release in the staging environment, and to test this bug fix on the production environment. For arguments sake, let’s say this testing time took 1 hour on each environment.
Total Customer Time Waiting For This Bug Fix:
2 weeks
Total Testing Time:
3 hours
Now imagine we have 13 issues that have been delivered with this release, we can compound the total waiting time and total testing time.
Total Customer Time Waiting For This Release:
26 weeks
Total Testing Time For This Release:
39 hours
Let’s contrast this with a continuous delivery approach. In this scenario, Alice works on an issue by first checking out the latest production code from the master branch. Once she is confident she has fixed the bug and it has passed QA, she merges the bug in to the master branch and deploys the fix to production. Let’s assume that she took two hours to fix the bug and that the bug required one hour of testing.
Total Customer Time Waiting For This Release:
2 hours
Total Testing Time For This Release:
1 hour
We can compound this by assuming we have 13 issues that are being worked on for the week.
Total Customer Time Waiting For This Week:
26 hours
Total Testing Time For This Week:
13 hours
Scenario 2: Regressions and Rollback
Now imagine that the bug fix in the scenario above actually causes a regression on production that needs to be fixed immediately or rolled back.
In Brad’s case (the weekly release process), someone on the devops or change management team packages the production release and pushes it to the production environment. And something goes wrong. Devops knows that one of 13 different change sets have been released but have no way of knowing which of those change sets is causing the regression. A critical issue is created identifying the problem and this issue is handed off to the development team. The team works to triage the issue, notices that Brad’s change caused the problem and Brad is now in charge of fixing it. But the last time Brad worked on this piece of code was two weeks ago and his memory is a bit fuzzy about why the change was made. Or maybe Brad is on holiday and someone else needs to pick up his work without fully understanding the intricacies and risks involved with the chage. Ultimately, the team decides they can’t go forward and all 13 change sets are rolled back until they can properly fix the problem.
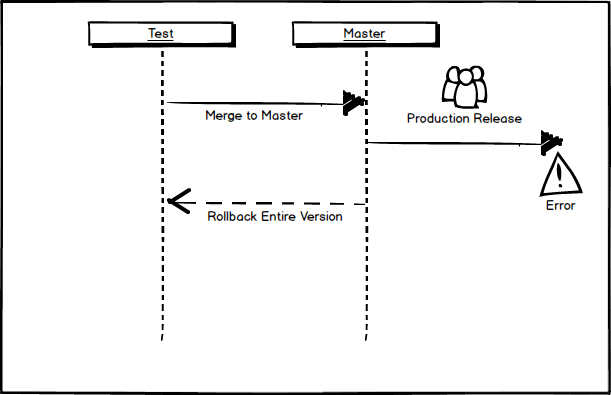
Contrast this with a continuous delivery approach. Alice works with QA to verify her change. Alice and QA deploy the change to production and immediately verify that the integrity of the fix. And something goes wrong. In this case, there is only one change set that could have cause the problem – Alice’s. Alice has immediate knowledge of the changes she just committed and possible reasons for a failure. She can choose at this point to fix the issue and release her fix or to roll-back her single change. In this scenario, Alice is responsible for the integrity of her changes and for verifying that her work was done correctly. She is able to work in concert with QA to test the issue and does not simply push her issue ‘over the wall’ for someone else to test and deploy.
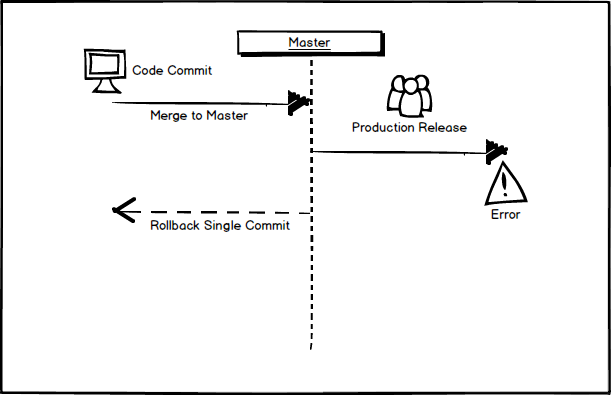
With continuous delivery, each deployment is a smaller change that can be easily understood, fixed or, when necessary, rolled-back.
Scenario 3: New Features
We’ve seen how continuous delivery can aid in deploying bug fixes, but what about delivery new features? Remember that with continuous delivery any commit at any time can be deployed directly to the production environment. So how can you deploy partially complete features? The answer is feature flags. Feature flags allow the developer to write a new feature or edit an existing feature without exposing those changes to the end user.
For a brand new feature, it’s relatively easy to develop the entire feature behind a feature flag that is inaccessible to the user by not exposing the new page, button or widget at all. Once the feature matures it can be opened up to QA or product managers for testing and eventually rolled out to a small percentage of users. These users are able to test the feature with real production data and real production load – making sure everything works as expected.
Gradually rolling out the feature also gives you the ability to measure user behaviour and gather feedback before committing to a certain path of action.
When enhancing existing features or doing refactoring, feature flags work best with continuous delivery when following a parallel change design pattern, where both the old and the new code is run during a request, but only one version of the result is returned to the user. As a concrete example, imagine we are trying to improve the performance of a page through a refactoring. When a request comes in, we route the request to both the old and new code and can measure – on production – the performance of the new code. We can easily see if our proposed refactoring has measurable performance improvements in a real-world setting.
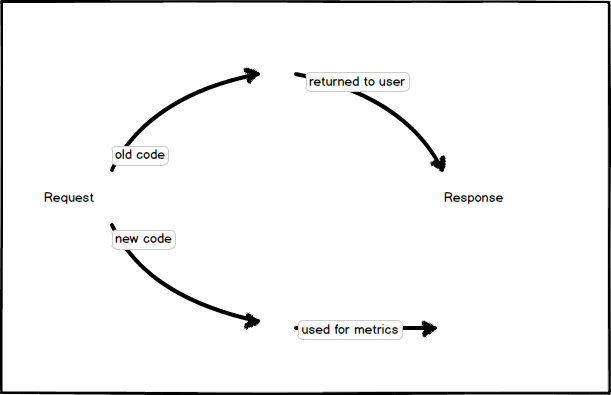
For example, by extracting performance measurements over each iteration of the code we visually compare the effect of a code change.
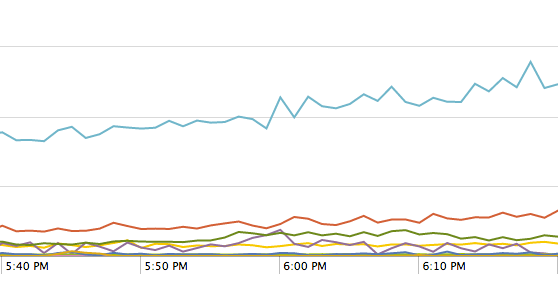
We can also use the same pattern to ensure we have confidence in the results of our new code. For example, on each request, we can run both the old and the new code, and compare the results on real-world production data. When we are confident that the differences between the new and old code are within an acceptable error range the new code is ready to go live. We also have the ability to use production data to inform our unit tests and guard against future regressions.
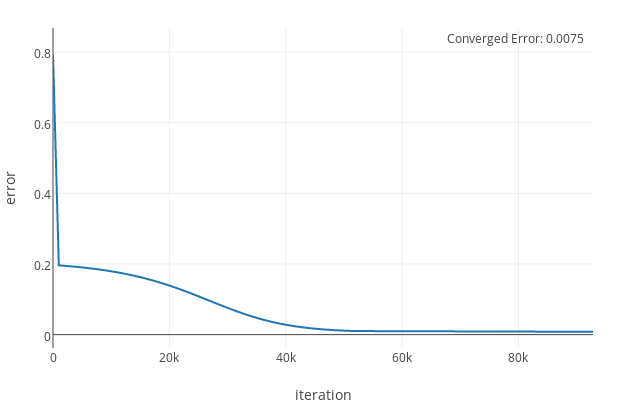
Caution must be exercised whenever using feature flags. Every feature flag that is in use within the product is technical debt that should be short lived.
Towards Continuous Delivery
Continuous delivery is not a panacea – it requires diligence and responsibility on behalf of the development team. However, if the team is able to cross these hurdles continuous delivery can be used to deliver stable software to customers faster than ever before.