Title and Author of Paper
Dynamo: Amazon’s Highly Available Key-value Store, DeCandia et al.
Summary
Dynamo, as the title of the paper suggests, is Amazon’s highly available key-value storage system. Dynamo only supports primary-key access to data, which is useful for services such as shopping carts and session management. Dynamo’s use case for these services is providing a highly-available system that always accepts writes. This requirement forces the complexity of conflict resolution to data readers. Writes are never rejected.
The paper focuses on how Dynamo combines several core distributed systems techniques to solve Amazon’s particular use case. This review focuses on the solutions to partitioning, replication, and data versioning.
Partitioning
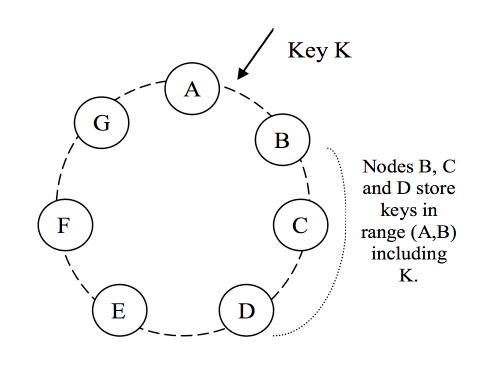
One design choice made with Dynamo was allowing the system to scale incrementally with the addition of nodes. This requires the system to dynamically partition data over the set of nodes. To achieve this, Dynamo relies on consistent hashing to assign each data item to a node. The nodes are arranged in a ring where the largest hash value wraps around to the smallest hash value.
By arranging nodes in a ring, the departure and arrival of nodes from the cluster only affects that nodes immediate neighbours.
Replication
Dynamo replicates data on multiple hosts to provide high data availability and durability. Each data item is replicated at N hosts. Each data key is assigned a coordinator node that is charged with replicating data at N-1 neighbouring hosts in the ring.
Data Versioning
Dynamo provides eventual consistency, where writes are propagated to replicas asynchronously. Get operations on non-updated nodes may return an objects that do not reflect the latest versions. To aid in reconciling inconsistencies, Dynamo treats the result of each modification as a new and immutable version of data. Each version of the data is assigned a vector clock that increments for every version of an object. When a client wants to update an object, it specifies the version of the object it is updating and when a client reads an object, all divergent versions are returned. It is the clients responsibility to merge these divergent versions according to the needs of the application.
In addition, Dynamo provides a background process that automatically merges versions of data that have no conflicts.
Wrapping Up
Dynamo was designed to address the very specific use case of providing highly available writes of building a key-value store that is always available for writes. By working within these constraints, Dynamo was able to deploy a combination of existing database techniques to solve their particular use case.