Business intelligence and analytics use cases involve complex queries on potentially very large databases. To minimize query response times, query optimization is critical. One approach to optimizing query response times is to precompute relevant values ahead of time, and to use those precomputed results to answer queries. Unfortunately, it is not always feasible to precompute every potential value that is required to answer arbitrary queries. This paper describes a framework and presents algorithms that pick a good subset of queries to precompute to optimize response time.
The Data Cube
A data cube is often used in business intelligence applications to present a multidimensional view of data that can be explored to find values of interest. Within a data cube, each dimensions represents an attribute of the data, and the value at each cell the measurement for that set of dimensions. Data cubes are commonly used to describe time series data, allowing a user to view dimensions of the data at different points in time. By cleverly choosing what parts of the data cube to precompute (or materialize), we can reap dramatic performance benefits.
Summary cells in a data cube can be represented by a value of ALL for a given dimensions. A cell in the cube with an ALL value for an attribute represents an aggregation of the data along that attribute of interest. Any cell that has an ALL value as a component is called a “dependent” cell — it’s value can be computed from those of other cells in the cube through aggregation.
As an example, we can imagine a database with three dimensions: (part, supplier, customer). This data can be grouped in 8 different ways.
- part, supplier, customer
- part, customer
- part, supplier
- supplier, customer
- part
- supplier
- customer
- none
The primary contribution of this paper is to recognize that this data can be organized as a “lattice”, where queries that can be answered from other data rest above that data in the lattice.
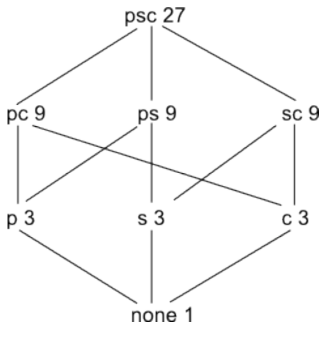
Consider two queries Q1 and Q2. Q1 is “dependent” on Q2 if Q1 can be answered using only the results of Q2. This dependence relation implies there is a “path downwards” from Q2 to Q1 in the lattice arrangement of the data.
Optimizing Data Cube Lattices
Given these observations, how can we optimize queries using a lattice? The paper presents a greedy algorithm for solving this problem.
The greedy algorithm assumes that each materialized view comes at a cost,
assumed to be the number of rows in the view. Given these costs, the
greedy algorithm attempts to select a set of views S that minimizes cost.
Another way to define this is to look at the benefit of adding
a materialized view to the set of views already materialized. If the newly
added view improves the cost of evaluating other views, then we can add
that view to the set of views materialized. This can be codified by
a benefit function B(v,S) that computes the benefit of adding view
v to the set of views S. The greedy algorithm can then be summarized.
S = {top view};
for i=1 to k do
select view v not in S such that B(v,S) is maximized
S = S union {v}
end
The paper goes on to prove that the greedy algorithm is always within 63% of the optimal solution for all lattices, providing a guaranteed range of performance optimization by applying this technique for selecting materialized views.