A central tenet of databases is that any committed data survives a crash or a failure. Write-ahead logging is a fundamental primitive that ensures all changes to data are first written safely to stable storage before being applied. Coupling that with some careful use of sequence numbers and we can guarantee that changes made to a database can survive system crashes.
Motivation
Let’s start with a simple transaction T1 that reads object
A, and updates the value for A with a write. To simplify matters, A
is stored on disk as a single page as in Figure 1.
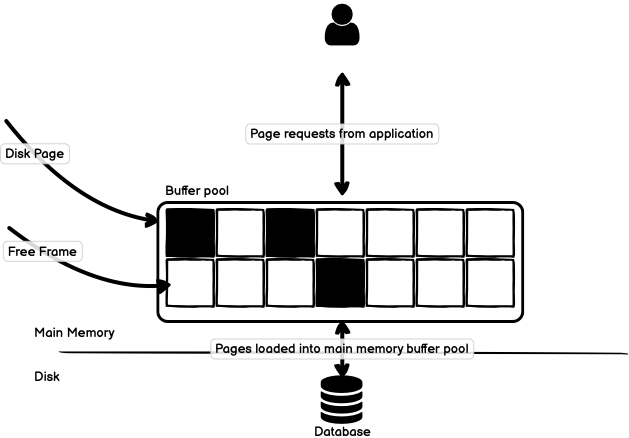
Databases execute transactions in main-memory, which is facilitated by the
buffer pool. The buffer pool holds an in-memory representation of the
state of the database and periodically writes that state to permanent
storage on disk. When the simple transaction starts, the value for A is
read from disk and stored in the buffer pool to take part in the
transaction, as in Figure 2.
As the transaction proceeds, it writes a new value for A. This value is
immediately updated in the buffer pool.
Lastly, the transaction commits.
At this point in time, the view of the database in-memory is that object
A has value 2, and the view of the database on disk is that object A
has value 1. To guarantee the atomicity and durability of transactions,
the database needs to determine what happens if the system fails in a way
that causes the loss of main memory. The database must ensure that any
updates to transactions that had committed prior to the crash are
reflected in the database and that any updates from transactions that were
in progress or aborted at the time of the crash are removed from the
database.
Buffer Management
Both file systems and databases use a buffer residing in main memory to cache frequently or recently used data. When the buffer fills up, or an event triggers a write to disk, the data in the buffer is flushed to non-volatile storage permanently and the space in the buffer can be freed for use for new data.
Buffers provide excellent performance advantages when accessing data, but they introduce reliability concerns when true crash recovery is required, particularly when you require ACID guarantees that database management systems (DBMS) provide. Any data in volatile storage, such as main memory, will be lost in the case of a process crash. This means that any data that is kept in a buffer without being written (or flushed) to disk is lost in the case of a crash. Non-volatile data, such as a magnetic disk or solid-state drive, store data durably and can survive process crashes.
The buffer manager divides changes to data into a unit of storage called a “page”. During normal operation, the pages in the buffer pool representing changed data become “dirty”. The buffer manager writes dirty pages from the buffer pool to stable storage periodically. When and how the buffer manager writes dirty pages in volatile memory to non-volatile disk dictates both the performance characteristics of the database and the complexity of any algorithm that recovers data in the face of a crash.
Stealing and Forcing
When using a buffer manager, the DBMS needs to uphold certain guarantees in the face of process crashes. First, it must ensure that any changes made a transaction are durable once the DBMS has told a user application that the transaction is committed. We cannot lose commits. Second, the DBMS must ensure that no partial changes are written to durable non-volatile storage if a transaction is aborted. Providing these two guarantees is complicated by the fact that data in the buffer may include transactions that must support typical ACID guarantees through system failures.
A key decision for the database recovery system to make is what to do about transactions that have been processed in main memory, but that have not been written to disk. Policies around handling this scenario are divided into two categories called “STEAL” and “FORCE”.
A STEAL policy states whether or not the database allows an uncommitted transaction to overwrite the most recent committed value of object in non-volatile storage. If you are using a STEAL policy, the buffer manager is allowed to overwrite data in memory with uncommitted data to increase performance. If you are using a NO-STEAL policy, this action is not allowed. Another way to think about this is, if the buffer pool is running out of space, is a transaction allowed to steal a slot in the buffer pool from another transaction that has not committed yet?
A FORCE policy requires that all updates made by a transaction are reflected on non-volatile storage before the transaction is allowed to be committed. A FORCE policy requires all changes to be written to disk before announcing a transaction is complete, whereas a NO-FORCE policy does not require this. Another way to think about FORCE is, are we allowed to acknowledge to the application that a transaction has completed before it is written to disk?
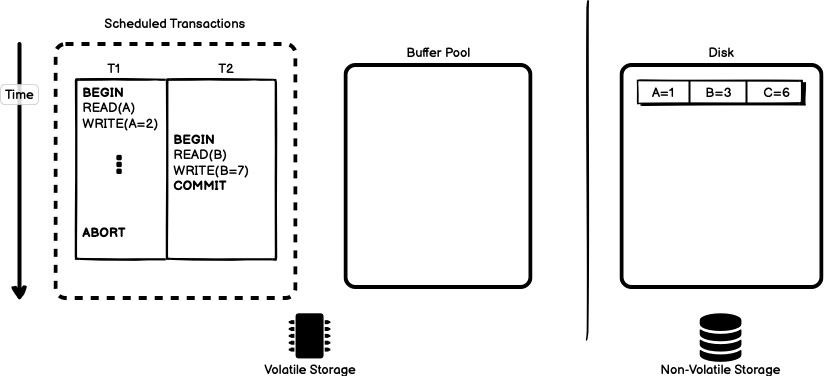
To make the ideas of STEAL and FORCE more concrete, let’s consider two
transactions like those in Figure 6 below. Two transactions T1 and T2
are scheduled for execution and their execution paths are interleaved so
that T2 begins after T1 and commits before T1. T1 reads and writes
to object A, and T2 reads and writes to object B. Both A and B
happen to be stored on the same page on disk.
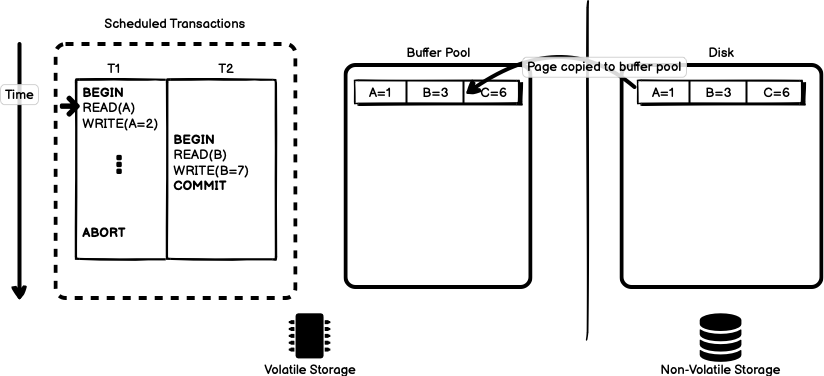
Transaction T1 begins and the page containing object A is read
from disk into the buffer pool, as in Figure 7.
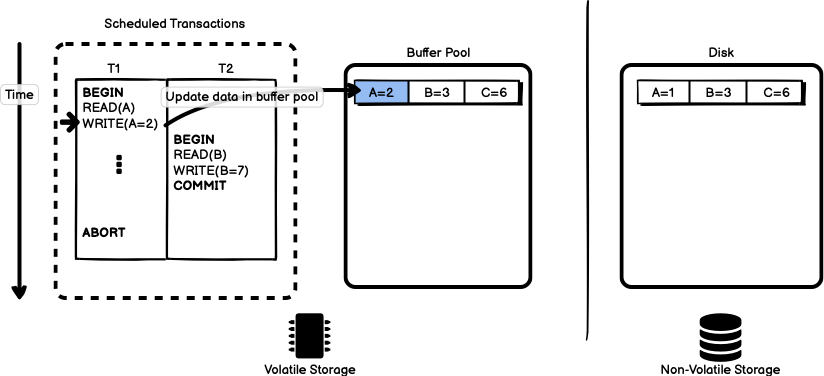
Transaction T1 continues, updating the value for A in the buffer pool
(but not yet on disk).
At this point, the transaction scheduler switches context and works on
T2. The READ(B) statement executes and since the data for B is
already in the buffer pool nothing needs to happen. Execution continues on
to WRITE(B=7). The change is made to the data in the buffer pool as in
Figure 9.
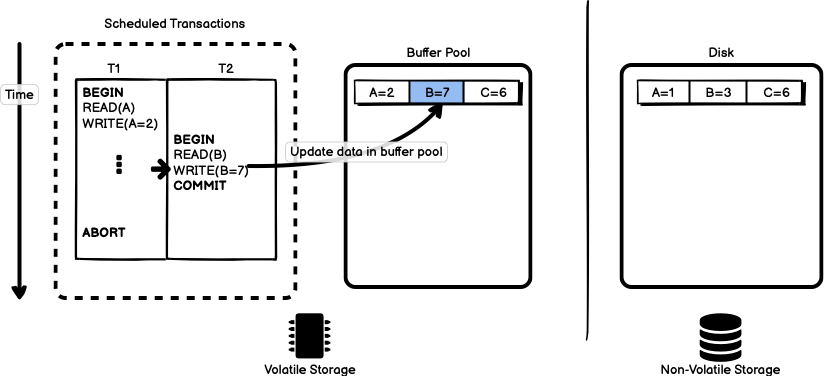
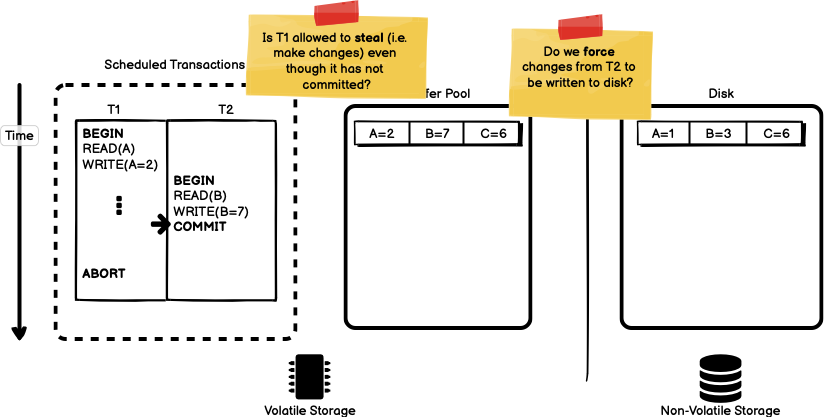
The next step in transaction T2 is to commit the data. At this point in
time, the database implementer has two decisions they need to make. First,
do we return to the calling application that transaction T2 is complete
and has committed? Or should we force a write of the dirty pages changed
by T2 to disk before returning to the calling application? In other
words, do we force the buffer pool to write out all of its changes to
disk before advertising a transaction as committed? Second, note that
transaction T1 has made changes to the buffer pool, even though data is
not committed. If we write the changes made to the buffer pool out to
disk, the changed value of A will be written out, even though the
transaction has not yet committed. Should we allow transaction T1 to
steal data by writing out uncommitted transactions?
A NO-STEAL and FORCE policy is the simplest set of policies to implement. A NO-STEAL policy does not allow overwriting data with something that has not been committed to disk. This provides atomicity without the need for UNDO logic when recovering because changes that were not part of a transaction committed to disk cannot be included in any other transaction. A FORCE policy makes sure that every update is on disk before a transaction commits. This provides durability without the need to handle complicated REDO logic when recovering from a crash because all committed data has been safely stored on non-volatile storage.
Though NO-STEAL/FORCE is the simplest policy to use when implementing a recovery system, it leads to the worst case performance scenario because every change to the database must be fully written to disk before completing a transaction. For this reason, commercial databases choose a STEAL/NO-FORCE policy to increase performance, even though it complicates the logic for recovering from failure. That choice dictates how we use logging to recover from failures, which is covered in the next section.
Write Ahead Logging
Most crash recovery systems are built around a STEAL/NO-FORCE approach, accepting the risks of writing possibly uncommitted data to memory to gain the performance improvements of not having to force all commits to disk. The STEAL policy imposes the need to UNDO transactions and the NO-FORCE policy imposes the need to REDO transactions. Databases rely on a log that stores transaction data and system state with enough information to make it possible to undo or redo transactions to ensure atomicity and durability of the database.
A database log is a file on disk that stores a sequential list of operations on the database. Each entry in the log is called a log record. During normal database operation, one or more log entries are written to the log file for each update to the database performed by a transaction. Each entry has a unique sequence number called the Log Sequence Number, or LSN that uniquely identifies each record in the log. A second type of log record is a checkpoint. Periodically, these records are written to describe the overall state of the database at a certain point in time and may contain information about the contents of the buffer pool, active transactions, or other details depending on the implementation of the recovery system. The log file contains enough information that we are able to undo the effects of any incomplete or aborted transactions, and that we are able to redo any effects of committed transactions that haven’t been flushed to disk.
Log records are only valuable if they can ensure recovery from failure. Write Ahead Logging (WAL) is a protocol stating that the database must write to disk the log file records corresponding to database changes before those changes to the database can be written to the main database files. The WAL protocol ensures that:
- All log records updating a page are written to non-volatile storage before the page itself is over-written in non-volatile storage.
- A transaction is not considered committed until all of tis log records have been written to non-volatile storage.
WAL ensures that all log records for an updated page are written to non-volatile storage before the page itself is allowed to be over-written in non-volatile storage. This ensures that UNDO information required by a STEAL policy will be present in the log in the event of a crash. It also ensures that a transaction is not considered committed until all of its log records (including its commit record) have been written to non-volatile storage. This ensures that REDO information required by NO-FORCE policy will be present in the log.
To highlight the performance advantages achieved with write-ahead logging, imagine that a transaction makes an update 1000 objects in the database and that each of those objects reside on different pages on disk. Without write ahead logging, the DBMS would need to write 1000 pages to disk to successfully complete the transaction. With WAL and a STEAL/NO-FORCE policy, we can update the data in-memory and write a single log record to disk that includes all information necessary to REDO the 1000 object update. Writing the remaining 1000 pages to disk can be done asynchronously without impacting running user-facing transactions.
The WAL Protocol
The actual WAL protocol needs to mark when a transaction begins using
a <BEGIN> record a transaction starting point. When a transaction
finishes, we write a <COMMIT> record to the log. Each additional entry
in the log contains information about the change to a single object. This
includes identifiers for the transaction being performed, the objects
being modified, the before value of the object (to facilitate UNDO) and
the after value of the object (to facilitate REDO). The database must
write all log records to disk before it returns an acknowledgement to the
calling application.
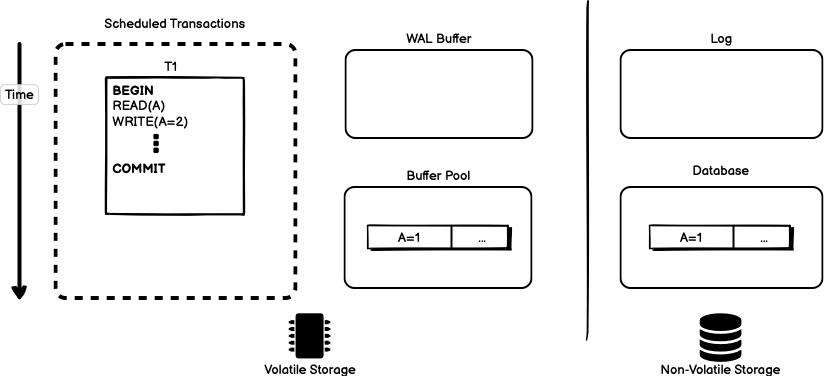
Figure 11 shows the starting state of a database using WAL. Here, we have an additional in-memory buffer dedicated to write-ahead logging called the WAL buffer. Changes destined for the log are buffered here in-memory before being written to non-volatile storage. For the sake of simplicity, the buffer pool has already been populated with the same page of data needed by the transaction.
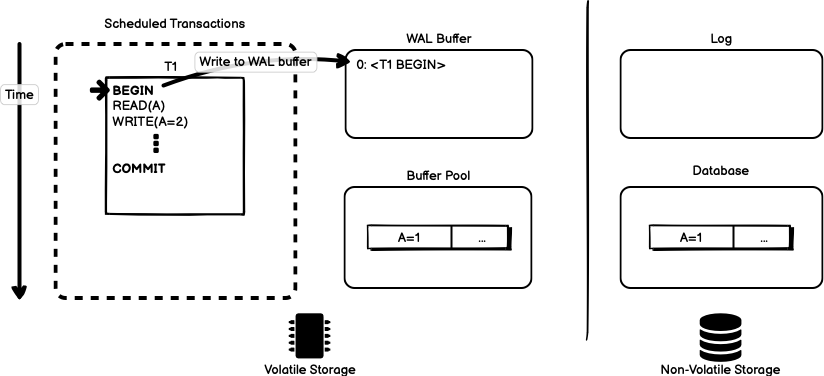
When the transaction begins, we start by marking the start of the transaction in the WAL buffer.
When it is time to update the data for the transaction, we first write the log entry to the WAL buffer with a sequence number, followed by the transaction responsible for the change, the object being changed, and the before and after value of the object. Once this change has been written to the WAL buffer, we make the change to the same object in the buffer pool.
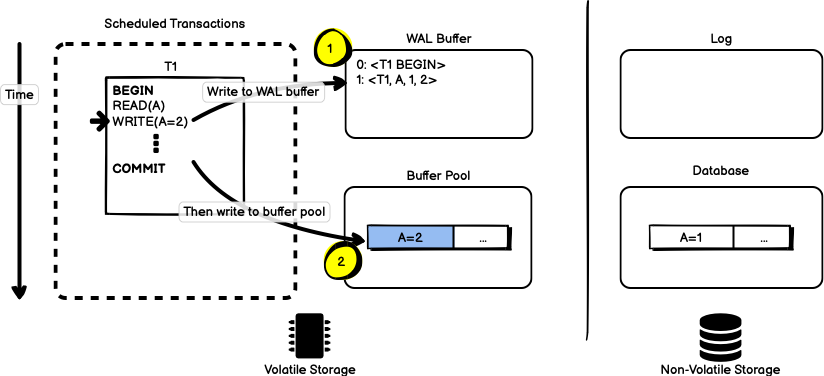
When the transaction reaches the COMMIT statement, we again write an entry in the WAL buffer. This time, because we have reached a commit, the entire buffer is copied into the log on disk. Once the log record has been safely stored on disk, the transaction can be flagged as “committed” and execution is free to return back to the application — we have enough information in the log to restore the state of the database even if we lose data in the buffer pool.
The write to the log on disk is a sequential write that appends to the end of the log. Sequential append-only I/O is significantly faster than the random access I/O that required to write the contents of the buffer pool out to disk. The use of a log here increases the performance of the database by condensing the transaction into a single sequential I/O operation before signalling to the application that the transaction has committed.
At a later point in time, the database is free to flush the data in the buffer pool to disk.
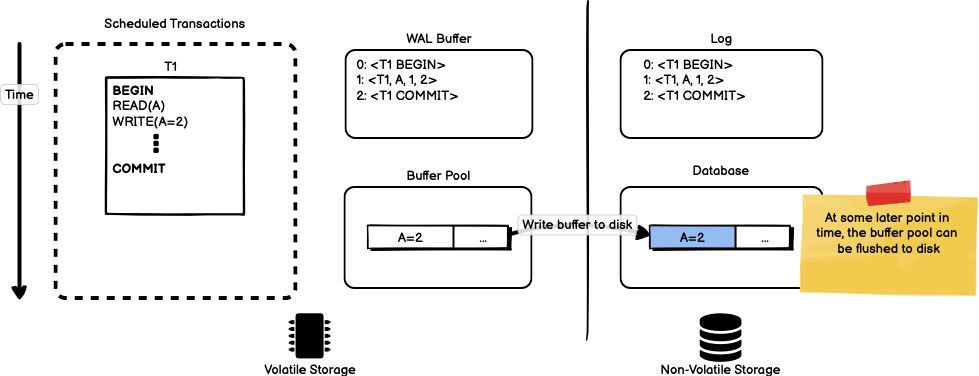
There is enough information in the log to recreate the state of the database if the buffer pool is killed before it is flushed to disk. The next section covers exactly to recover data after a crash using the log.
Maintaining Log Records
In a system using WAL, we write all modifications to the database to a stable log before applying them to the database itself. This simple act facilitates crash-recovery because we have a record of what changes were made before they are actually applied. Imagine a process that is in the middle of performing some operation when the machine it’s running on loses power. Upon restart, that process might need to know whether the operation it performed succeeded, partially succeeded, or failed. If the process uses a write-ahead log, it can replay the changes in the log to recover state, and compare that state to the current state of the process. On the basis of this comparison, the process could decide to undo what it had started, complete what it had started, or keep things as they are.
Conceptually the log is a single ever-growing sequential file that is append-only. Every log record has a unique log sequence number (LSN), and LSNs are assigned in ascending order. Log records may contain redo and undo information. A log record containing both is called an undo-redo log record, there may also be undo-only log records and redo-only log records. A redo record contains the information to redo a change made by a transaction (if they have been lost). An undo record contains the information needed to reverse a change made by a transaction (in the event of rollback). This information can simply be a copy of the before/after image of the data object, or it can be a description of the operation that needs to be perform to undo/redo the change.
The database uses the log sequence numbers to facilitate recovery by tracking the state of database pages, transactions, and flushed data during normal database operation. Each component of the system required for crash recovery tracks the sequence number of the log records that have modified data they require for recovery:
flushedLSN:- The largest sequence number flushed to disk so far.
- This number tracks whether a log record is durably persisted.
pageLSN:- The last log record that modified a page
recLSN:- The oldest update to the page since last flushed
lastLSN:- The last record of for each transaction
Each page of data contains the sequence number of the most recent update
to the page (the pageLSN). In addition, the database system tracks the
maximum sequence number that has been flushed so far (the flushedLSN).
During operation, we write a page x to disk only after all pages up to
x have been flushed to disk. That is, we can write a page x if
pageLSN(x) <= flushedLSN. This means that before we flush a dirty page
to disk, we first have to flush the log record that made the page dirty to
disk.
Figure 15 shows a conceptual idea of how the different
sequence numbers are maintained. For each page we maintain
a pageLSN marks the most recent log sequence number that modified this
page along with a recLSN that records the first log sequence number that
modified this page to make it dirty. Together, recLSN and pageLSN
provide a boundary recording the before and after state of the page and
the log records that modified data at those points in time. Lastly, we
flushedLSN records the last log sequence number that was written to
disk. The pageLSN and recLSN are committed to disk in the database
alongside each page when that page is written to disk.
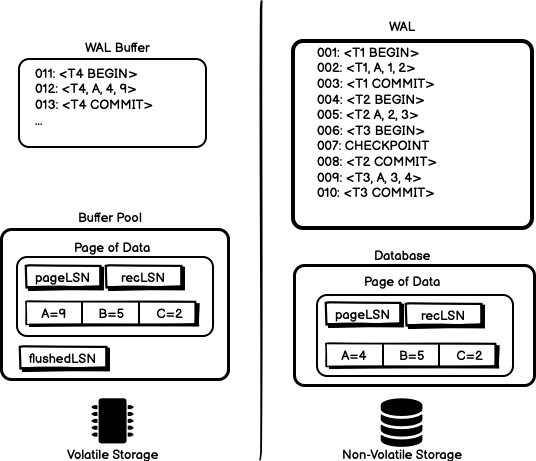
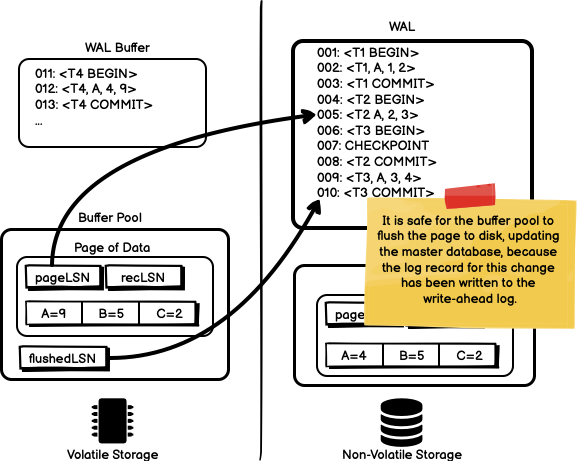
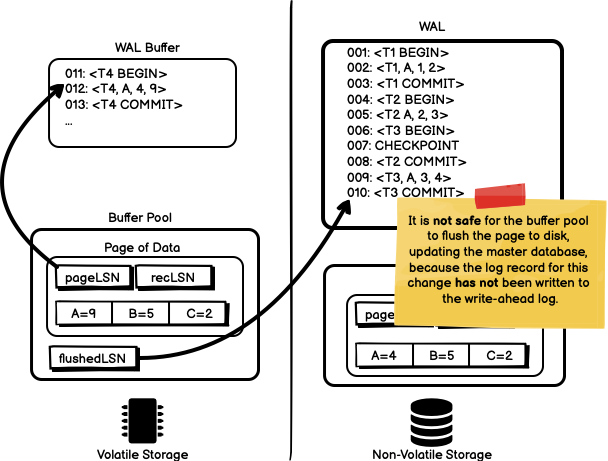
To following two diagrams show the case where pageLSN is less than
flushedLSN, or greater than flushedLSN. In the first case, it is safe
to write modified page to the master database because the pageLSN is
less than flushedLSN and we know that the log record modifying the page
has been written to disk. In the second case, the log record modifying the
page has not been written to disk and we cannot write the modified page
data to disk yet.
Maintaining Abort Records
As an optimization for handling aborts, the database also maintains
a prevLSN that records the previous log sequence number for this
transaction and a “transaction end” record signalling that a transaction
has completed and there will be no more log records for this transaction.
These two additions allow the recovery system to easily walk through any
log records that are part of the same transaction to make recovery more
performant. We also add compensation log records (CLR). The CLR describes
the changes made to undo any actions of a previous update. It has all the
fields of a regular log record and it gets added to the write ahead log
like any other record. For each undone update, the database creates a CLR
entry in the log and restores the old value to the database. After the
databases reverses the aborted transaction’s updates it then writes
a transaction end log record to signal that we will not see any additional
changes for this transaction.
As an example, we can look at a section of the log record as it is added
to over time. In the table below, we have a transaction T1 that updates
the value for A. At some later point in time, the transaction is
aborted. To facilitate the abort of the transaction, we need to undo the
change that was made to A. To do this, we create a compensation log
record log for the transaction id T1. You will notice that the record
with sequence number 026 sets A back to the value it had before the
update was made to object A through sequence number 002. Lastly,
a TXN-END log record is added to signal that we will never see any more
changes made to the database from transaction T1.
| LSN | prevLSN | txnId | type | object | beforeValue | afterValue | undoLSN |
|---|---|---|---|---|---|---|---|
| 001 | nil | T1 | BEGIN | ||||
| 002 | 001 | T1 | UPDATE | A | 30 | 40 | |
| … | |||||||
| 011 | 002 | T1 | ABORT | ||||
| … | |||||||
| 026 | 011 | T1 | CLR | A | 40 | 30 | 001 |
| 027 | 026 | T1 | TXN-END |
Using compensation log records, whenever a transaction is aborted, the
database plays back transaction updates in reverse order, and for each one
writes a compensation log record noting what changes were made. At the end
of the abort, write a TXN-END record to signal that this transaction is
complete.
Recovery — ARIES
The most widely known and emulated implementation of crash recovery is ARIES — Algorithms for Recovery and Isolation Exploiting Semantics, which is based on the background we’ve covered so far. The ARIES recovery algorithm is split into there phases: analysis, redo, and undo.
- Analysis: The analysis phase reads the log from the last recorded checkpoint to identify any dirty pages and active transactions at the time of the crash.
- Redo: The redo phase repeats all changes to the database from a point in the log forward. This includes transactions that will abort. This retrace brings the database back to the exact state it was in before the crash.
- Undo: Reverse the changes made by transactions that did not commit before the system crashed.
Although it may seem counter-intuitive to redo all changes, even ones that will eventually be aborted, it actually simplifies the overall algorithm considerably.
Analysis Phase
During the analysis phase, the log is scanned starting form the last
checkpoint recorded via the database’s log sequence numbers. The scan
proceeds forwards until it finds a transaction end record (TXN-END).
Whenever a transaction end record is found, the associated record keeping
for that transaction can be removed from the buffer pool. For all other
records (ones that are not transaction end), we add a transaction to the
buffer pool with the status of UNDO. The transaction is marked as UNDO
because we don’t yet know if the transaction will succeed and we need to
record the potential of having to undo these steps. On a commit record in
the log, the transaction can be changed from UNDO to COMMIT. Lastly,
for any UPDATE log records, if the associated page is not marked as
dirty, we mark the page as dirty and set the pages recLSN to signal the
oldest update to the page since it was last flushed.
Redo Phase
The redo phase repeats all history that was written to the log to reconstruct the state of the database at the exact moment of the crash. During this phase, we reapply all updates (even aborted transactions) and rewrite all compensation log records.
To perform the redo phase, the database scans forward from the log with
the smallest recLSN in the dirty page table that was reconstructed
during the analysis phase. For each update record or compensation record,
for a given sequence number, the database re-applies the update. This
update happens for all records unless the affected page has not been
marked as dirty, or the records sequence number is greater than the
recLSN, or if the pageLSN is already written to disk.
When redoing an action, the database acts as though it is a normal update
to the database. All changes are first applied to the log record and then
the affected page’s pageLSN is set to that log record’s sequence number.
At the end of the redo phase, any committed transactions are included in
the log with a TXN-END record and they are removed from the list of
active transactions.
Undo Phase
In the last phase, the database reverses all transactions that were active at the time of crash but that have not been committed. Since we removed any committed transactions from the buffer pool during the redo phase, any remaining transactions in the buffer pool can be undone. These are all transactions with UNDO status in the ATT after the Analysis and REDO phase.
The database processes transactions in reverse sequence number order. As it reverses the updates of a transaction, the database writes a compensation log record entry to the log for each modification. Once the last transaction has been successfully aborted, the database flushes out the log and then is ready to start processing new transactions.
Conclusions
ARIES was designed to support the needs of industrial strength transaction processing systems. ARIES uses logs to record the progress of transactions and their actions which cause changes to recoverable data objects. The log is the source of truth and is used to ensure that committed actions are reflected in the database, and that uncommitned actions are undone. Conceptually the log is a single ever-growing sequential file (append-only). Every log record has a unique log sequence number (LSN), and LSNs are assigned in ascending order.
Crash-recovery is a fundamental primitive underpinning databases and data storage technologies. Although the implementation can be challenging, the ideas around recovery are fairly straightforward: write all changes to disk in a log before applying any changes to the master data record. By tracking sequence numbers of each change, we can facilitate redoing and undoing database changes and restoring the system to the state it was in before the crash.