Cloud Dataflow is Google’s managed service for batch and stream data processing. Dataflow provides a programming model and execution framework that allows you to run the same code in batch or streaming mode, with guarantees on correctness and primitives for correcting timing issues. Why should you care about Dataflow? A few reasons. First, Dataflow is the only stream processing framework that has strong consistency guarantees for time series data. Second, Dataflow integrates well with the Google Cloud Platform and provides seamless methods for reading from and writing to the Datastore, PubSub, BigQuery and Cloud Storage. Third, the Dataflow SDK is open source and has received contributions for interfacing with Hadoop, Firebase, and Salesforce — AWS integration is absolutely possible. Lastly, Dataflow is completely managed, whereas competing offerings such as Spark and Flink typically run on top of a Hadoop installation used for intermediate storage.
This article provides a high-level introduction to Dataflow by discussing the underlying technology that powers it: MapReduce, FlumeJava, and MillWheel. To understand how Dataflow works requires a basic understanding of these core components, and how each are leveraged by the Dataflow Model for effective processing of bounded and unbounded data sets.
Batch Processing: MapReduce
MapReduce is a programming model and implementation for batch processing designed to handle large quantities of data. As the name implies, MapReduce provides a functional API for data processing where a user defines a map function that produces intermediate key-value pairs, and a reduce function that merges intermediate values into final results. Since each invocation of the map and reduce function can operate independently of one another, MapReduce naturally allows for scaling out of data processing by adding more nodes to the computation that can independently run the map or reduce functions. MapReduce was designed to solve embarrassingly parallel programming problems, for which little or no effort is required to separate the problem into parallel tasks. A lot of programs can be expressed in this functional style, and MapReduce has proven useful in many problem domains.
Although MapReduce was not a new idea, the Google paper proved the practical application of the technique for large-scale data processing. Other companies saw the value in this approach, and adopted MapReduce in house with the development of the Hadoop ecosystem. MapReduce and Hadoop have since became the de facto standard for batch data processing.
Dataflow Programming Model: FlumeJava
MapReduce is not without its faults, with one of the biggest being the limitations of the MapReduce programming model. Although many programs can be expressed as a combination of Map and Reduce functions, expressing programs in this fashion is tedious and error prone. Naturally, programmers developed abstractions for dealing with this problem. In the Hadoop ecosystem, Hive, Pig, and Impala were developed to allow programmers to use SQL-like queries or higher-level languages to write MapReduce programs. These programs would then be compiled by the respective frameworks into MapReduce programs to be run on Hadoop. FlumeJava is Google’s offering of a programming model for simplifying MapReduce programs.
FlumeJava is based on the abstraction of parallel collections of immutable data. As a developer, you express your program as a sequence of transformations and operations on parallel collections — when you are ready to run your FlumeJava program, the system constructs an execution graph expressing your program as a data pipeline, and optimizes that graph. The graph is run using an underlying data processing framework like MapReduce. FlumeJava’s combination of higher-level programming abstractions and an optimization framework frees developers from thinking about the tedious details of MapReduce.
A FlumeJava program acts as a directed graph of processing steps defined using four major primitives:
- Pipelines: an entire series of computations representing the processing job as a whole.
- PCollections: A collection of data in your pipeline. The data represents a potentially tedious details of infinitely sized set of unbounded data.
- Transforms: A transform takes one or more PCollections as input, performs a processing function, and returns one or more PCollections as output.
- I/O Sources and Sinks: Functionality for reading from and writing to external data sources.
In the simplest case, the pipeline represents a sequence of linear operations on data. In more complex cases, a pipeline can represent a directed acyclic graph of steps with multiple input sources or output sinks and intermediate transformations. In either case, the FlumeJava environment will construct and optimize an execution graph for your program to run on an underlying processing framework.
Handling Streaming Data: MillWheel
MapReduce is a batch processing framework designed to periodically process fixed size data sets. In the real world, most data is being continually collected as an ever growing and essentially infinite size data set, and users want to process and view that data in real-time. MillWheel is Google’s stream processing framework for handling unbounded data sets in real-time, providing a programming model and implementation framework with robust primitives for dealing with time in distributed systems. Unlike many stream processing systems, MillWheel was designed from the beginning to be fault-tolerant and offer strong correctness guarantees. These correctness guarantees are augmented by methods for reasoning about time: windowing and triggers.
Windowing
Dealing with unbounded data requires you to somehow limit the amount of data you process at one time — you cannot collect the infinite data set and process it later. The typical method for dealing with this problem is windowing. Windowing chops up a data set into finite pieces across time boundaries. For example, you could process five minutes worth of data per window. Unfortunately, because of the nature of distributed systems, windowing introduces its own problems that require some understanding of time in the domain of unbounded data:
- Event Time: the time at which an event occurred within the system generating the event. For example, the time at which a server writes a log entry — according the server’s system clock.
- Processing Time: the time at which an event is observed during data processing — according to the stream processor’s system clock.
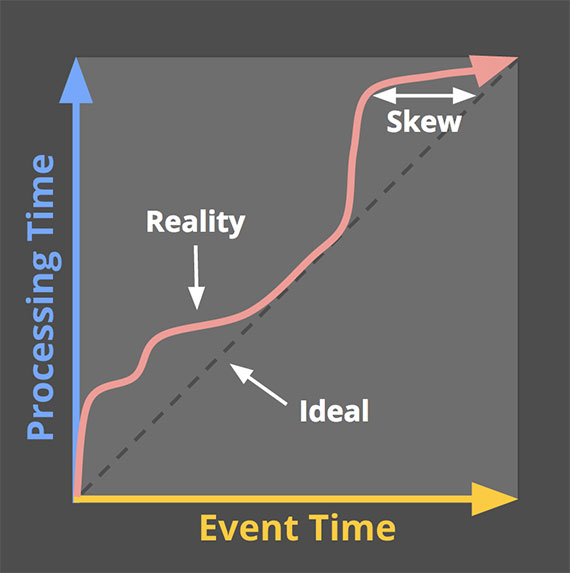
In an ideal world, event time and processing time would be exactly equivalent, and all events would be processed as they occur. In reality, system lag, network issues, or system load may cause processing times to lag behind event times. This is known as event time skew. The figure below shows an example time domain mapping. The X-axis represents event time in the system. The Y-axis represents the progress of processing time.
Triggers
If you ignore event time skew (as most stream processing systems do), some event time data will arrive in the wrong processing time window. If you care about correctness, event time skew has real implications on stream processing systems. MillWheel is designed to handle event time skew by allowing you to deal with late data using triggers. Triggers allow you to adjust the results of previous windows as new data arrives. In other words, you are able to constantly make your results more correct as your data becomes more complete, achieving complete correctness once you have seen all of the data.
Bringing it All Together: Cloud Dataflow
Cloud Dataflow is Google’s public offering of the combination of MapReduce, FlumeJava, and MillWheel — as a fully-managed cloud service for batch and stream data processing. The open source Cloud Dataflow SDK allows you to express your data processing pipeline using FlumeJava with extensions for windowing and triggers to allow you to deal with unbounded data and event time skew. If you run your Cloud Dataflow program in batch mode, it is converted to MapReduce operations and run on Google’s MapReduce framework. If you run the same program in streaming mode, it is executed on the MillWheel stream processing engine. For example, you could process log data in real-time via PubSub, or in batch mode via log files stored in Cloud Storage or S3 — without any additional work by the programmer. Cloud Dataflow eliminates the headaches required to build and maintain a Lambda Architecture system by providing a single platform for handling both batch and streaming data.
It is worth noting that if you care about event time correctness, Dataflow is pretty much the only game in town as of this writing. Note that you can run a Dataflow program on Apache Spark or Apache Flink to achieve event time correctness using these alternative processing engines. However, both Spark and Flink require a distributed file system to be deployed underneath them for handling intermediate data and typically run on top of an existing Hadoop installation, increasing the operational burden of deploying these systems.
Conclusion
Cloud Dataflow is a managed service combining MapReduce, FlumeJava, and MillWheel. This article provided a high-level overview of the pieces that make up the Dataflow environment and how they work together to provide a data processing framework that can handle both batch and stream processing with strong correctness guarantees. Dataflow programs also have built-in primitives for handling event time skew and provide strong correctness guarantees that do not exist in alternative stream processing systems like Apache Spark.