A short tagline from the book Learning eBPF describes eBPF as
a revolutionary kernel technology that allows developers to write custom code that can be loaded into the kernel dynamically, changing the way the kernel behaves.
The key word in this phrase is dynamically. eBPF allows you to write custom code that changes the way the kernel behaves without having to implement a kernel module or integrate your code directly into the kernel.
In these discussions, it is helpful to distinguish between the kernel and the userspace. Userspace programs run in a layer on top of the kernel that cannot access hardware directly. To perform work, userspace applications make requests to the kernel using the system call (syscall) interface. For example, a userspace program may use a system call implemented by the kernel to read and write files, or send and receive network traffic.
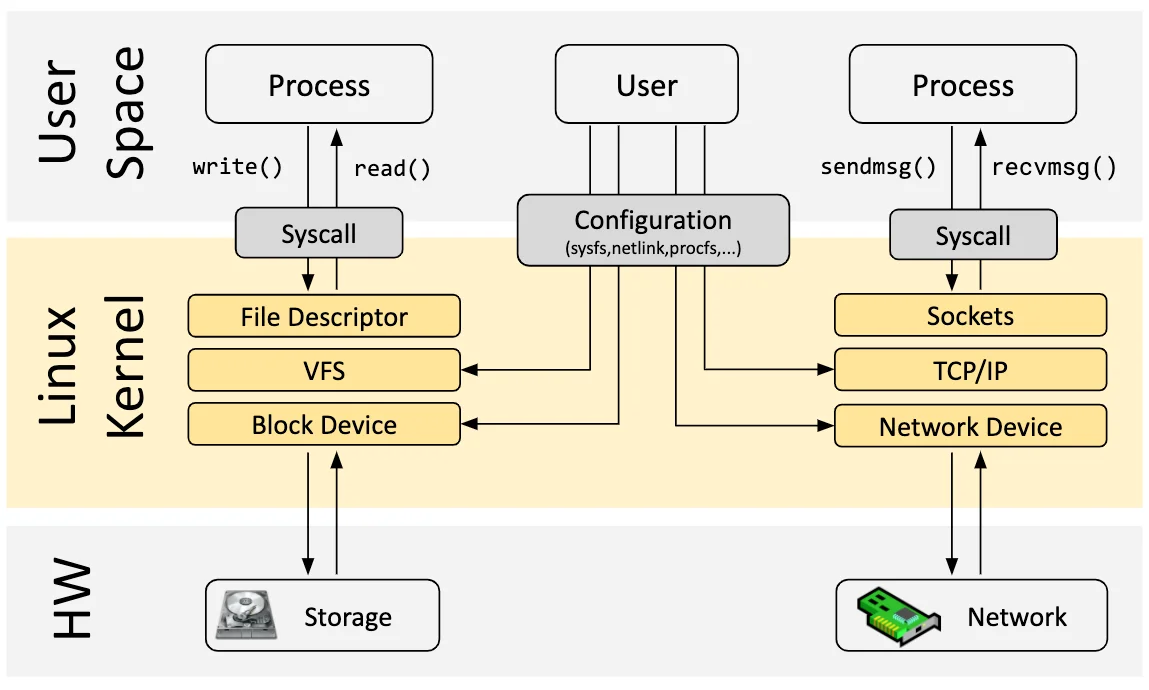
A userspace program may make hundreds of system calls to perform even
simple operations. Many of these system calls are hidden from the
developer through libraries and SDKs. For example, on my test machine
using the echo utility to print the statement “Hello World” results in
32 system calls.
$ strace -c echo "Hello World"
Hello World
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
0.00 0.000000 0 1 read
0.00 0.000000 0 1 write
0.00 0.000000 0 1 open
0.00 0.000000 0 5 close
0.00 0.000000 0 4 fstat
0.00 0.000000 0 6 mmap
0.00 0.000000 0 4 mprotect
0.00 0.000000 0 1 munmap
0.00 0.000000 0 4 brk
0.00 0.000000 0 1 1 access
0.00 0.000000 0 1 execve
0.00 0.000000 0 1 arch_prctl
0.00 0.000000 0 2 openat
------ ----------- ----------- --------- --------- ----------------
100.00 0.000000 32 1 total
Even simple applications rely heavily on the kernel, which means that if we can understand and observe the system calls that an application makes we can learn a lot about applications as well. eBPF allows just this functionality — intercepting the system calls an application makes and running custom code using the data in those calls.
Before eBPF, this level of integration with the Linux kernel required adding new functionality to the kernel itself. Either through contributing making edits to the around 30 million lines of code in the kernel or writing a kernel module that can be loaded into the kernel during the compilation process.
eBPF offers a new approach to modifying kernel behaviour by allowing programs to be loaded into and removed from the kernel dynamically. Once an eBPF program is loaded, it can be attached to system call events. Whenever the relevant system call event occurs, the eBPF program is ran. For example, if you attach an eBPF program to the system call for opening files, it will be triggered whenever any process tries to open a file.
The following diagram shows how eBPF is integrated into the kernel.
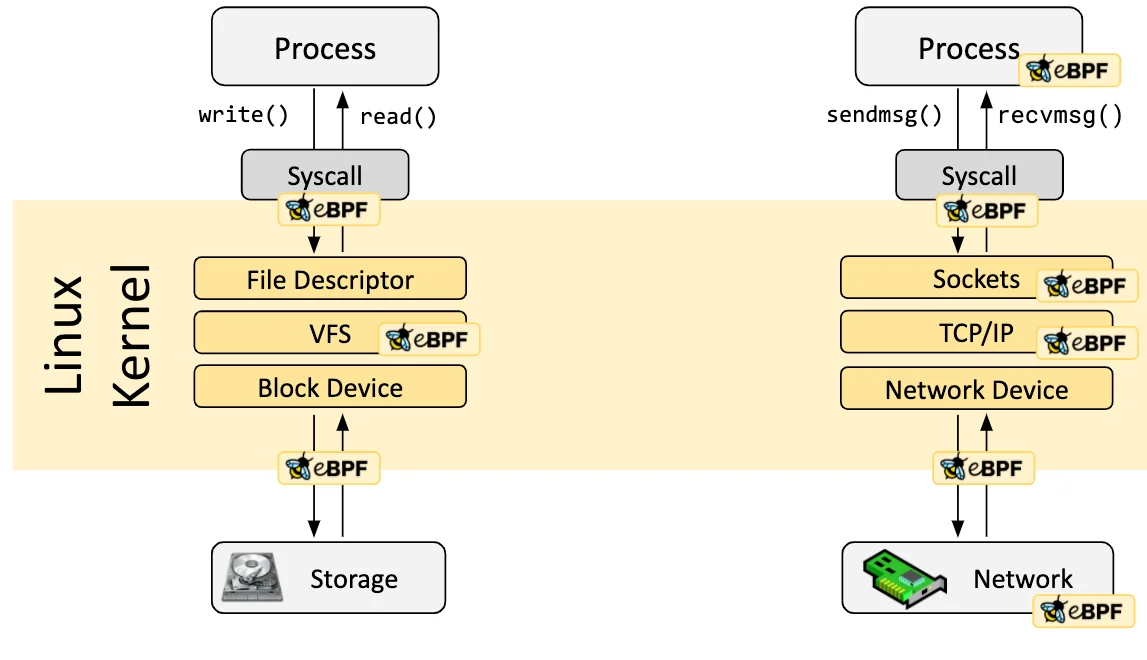
eBPF programs are event-driven and are run when the kernel or an application passes a certain hook point. Pre-defined hooks include system calls, function entry and exit events, kernel tracepoints, or networking events.
Safety and Verification
When loading an eBPF program into the kernel, a verification step ensures that the eBPF program is safe to run.
Verification handles any concerns that an eBPF program can crash the kernel and bring down the entire system. Several aspects of the program are validated:
- The program has the correct privileges to execute.
- No uninitialized variables or incorrect memory access occurs.
- The program is small enough to fit within system constrains.
- The program always runs to completion. An eBPF program is only accepted if the verifier can ensure that any loops contain an exit condition which is guaranteed to become true.
- The program must have a finite complexity. The verifier will evaluate all possible execution paths and must be capable of completing the analysis within the limits of the configured upper complexity limit.
Performance
Once an eBPF program has been verified safe, it goes through a just-in-time (JIT) compilation process translating the eBPF bytecode into machine specific instructions that optimize execution speed. This makes eBPF programs run as efficiently as natively compiled kernel code or as code loaded as a kernel module.
In addition, since eBPF programs sit on the data path of the kernel, there is no cost in transitioning between kernel and userspace to handle each event.
Summary
The main purpose of the Linux kernel is to abstract the hardware or virtual hardware and provide a consistent API (system calls) allowing for applications to run and share the resources. In order to achieve this, a wide set of subsystems and layers are maintained to distribute these responsibilities. Each subsystem typically allows for some level of configuration to account for different needs of users. If a desired behaviour cannot be configured, a kernel change is required, historically, leaving two options: directly implementing the feature in the kernel, or writing a kernel module.
With eBPF, a new option is available that allows for reprogramming the behaviour of the Linux kernel without requiring changes to kernel source code or loading a kernel module. This reprogramming is made safe through verification, and performant through just-in-time compilation, unlocking new ways to dynamically inspect and observe applications and the system the run on, unlocking some key benefits that were not previously possible:
- Programmability: eBPF allows users to dynamically inject custom code into the kernel without the need to modify or recompile the kernel itself.
- Observability: eBPF enables users to collect detailed information about a wide variety of kernel and user-space events
- Security: eBPF programs go through a verification process before they are allowed to run in the kernel, reducing the risk of introducing malicious code.
- Performance: eBPF programs are designed to have minimal impact on system performance. They are executed in a restricted environment to ensure safety, and the just-in-time (JIT) compilation helps in optimizing performance.