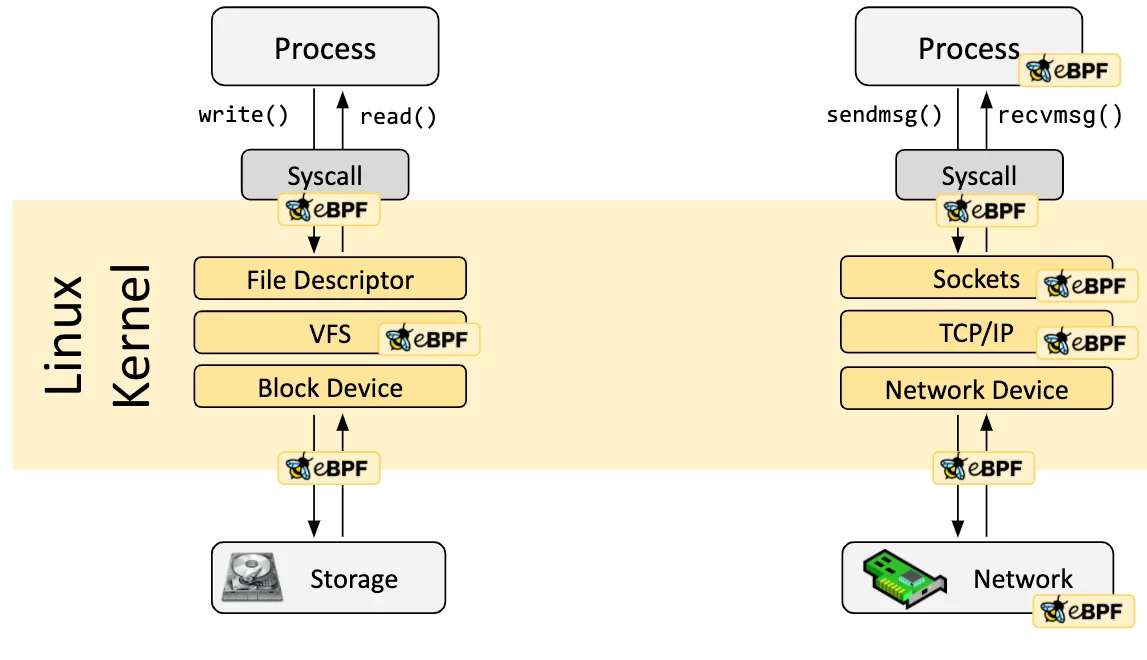
eBPF is a relatively new extension of the Linux kernel that can run sandboxed programs in a privileged context. It is used to safely and efficiently extend the capabilities of the kernel at runtime without requiring changes to kernel source code or the loading of kernel modules.
Because of eBPFs tight integration with the networking stack at the kernel level, it is seeing adoption in networking applications. This includes Kubernetes networking through eBPF implementations of the Kubnernetes networking stack like Cilium.
This post compares the traditional Kubernetes networking implementation using iptables with an implementation using eBPF.
The Kubernetes Networking Model using iptables
The default Kubernetes networking model is implemented using kube-proxy and iptables.
During cluster operation, the kube-proxy agent on a node will respond
to Kubernetes Pods scheduling events by writing entries in iptables
that direct traffic destined for the Pod to the correct network namespace
and container. You can view these entries by logging into any Kubernetes
node and issuing the following command: iptables -t nat -nvL. For
example, the following output lists an iptables rule for the kube-dns
deployment. It forwards all traffic received to the
KUBE-SEP-M6FB4YQ7BMUNVVRR iptables chain.
$ iptables -t nat -nvL
Chain KUBE-SVC-FXR4M2CWOGAZGGYD (1 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-SEP-M6FB4YQ7BMUNVVRR all -- * * 0.0.0.0/0 0.0.0.0/0 /* kube-system/kube-dns-upstream:dns */ statistic mode random probability 0.33333333349 ```
The actual set of rules for writing and resolving iptables entries is
quite
complex,
but the end result is that for each Service deployed to Kubernetes,
corresponding iptables entries are written to correctly route traffic
to the Pods and containers backing the Service.
iptables is widely supported and is the default operating model for a new Kubernetes cluster. Unfortunately, it runs into a few problems:
- iptables updates are made by recreating and updating all rules in a single transaction.
- iptables is implemented as a chain of rules in a linked list, so all operations are O(n).
- iptables implements access control as a sequential list of rules (also O(n)).
- Every time you have a new IP or port to match, rules need to be added and the chain changed.
- Has high consumption of resources on Kubernetes.
In short, under heavy traffic conditions or in systems with frequent change events, performance degrades and becomes unpredictable when using iptables. Fundamentally, the sequential nature of rule evaluation, and the requirement for all rules to be updated in a single consistent transaction, lead to significant performance penalties at scale. For example, Huawei found that having to replace the entire list of iptables rules for a cluster with 20,000 services could take up to five hours!
The Kubernetes Networking Model using eBPF
eBPF (extended Berkeley Packet Filter) is a technology with origins in the Linux kernel that can run sandboxed programs from safe points in the operating system kernel. It is used to efficiently extend the capabilities of the kernel without requiring changes to the kernel source code or having to load kernel modules.
eBPF is integrated within the kernel at pre-defined hook points. When the
kernel or an application passes a certain hook point, such as a system
call or network event, any registered eBPF programs are executed. Because
of this deep integration with the kernel, eBPF is well suited to take the
place of iptables to satisfy the needs of Kubernetes networking.
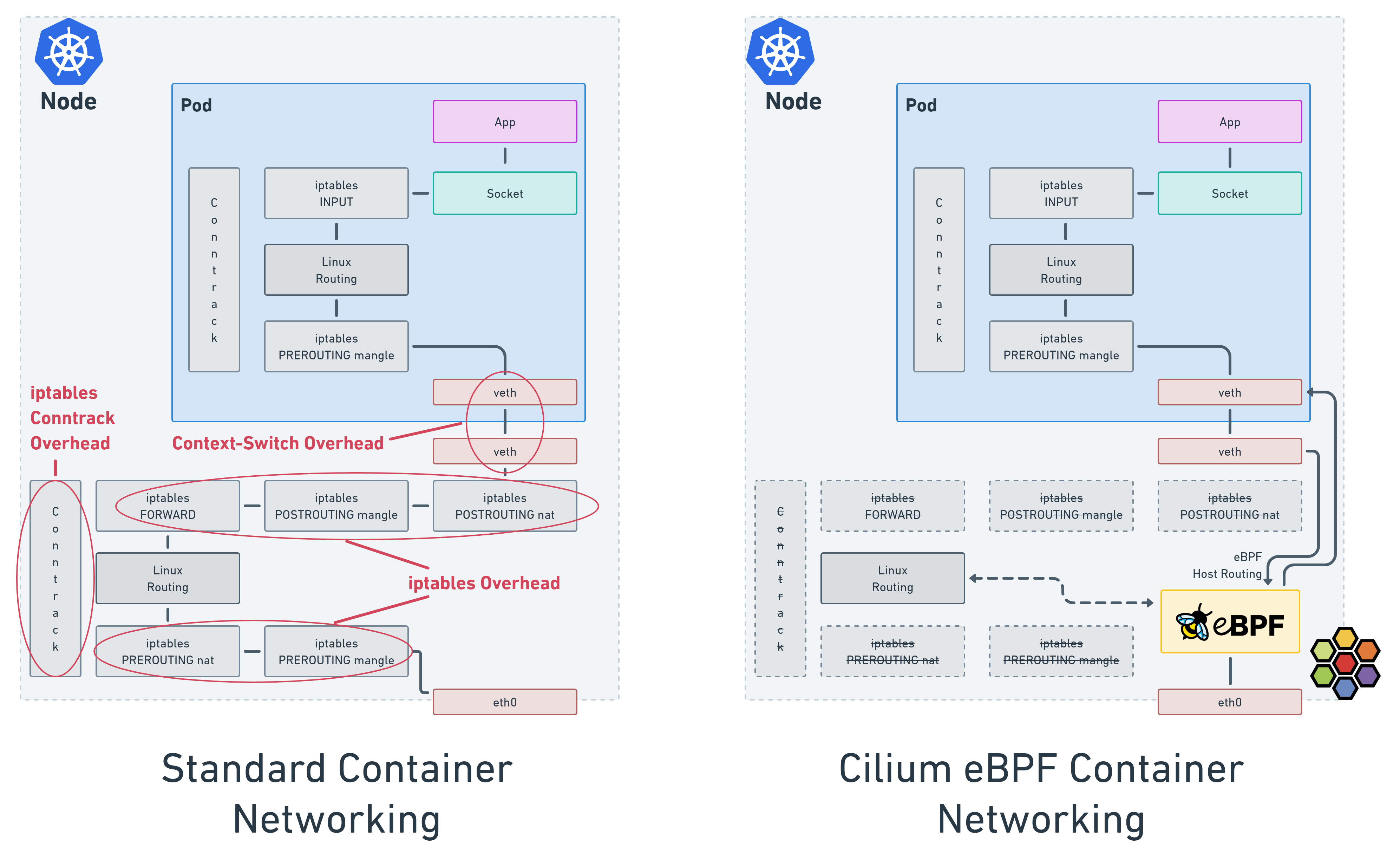
Cilium and
Calico both implement the
Kubernetes networking model using eBPF. The local agent installed on each
node reacts to Pod scheduling events by integrating with eBPF hooks in
the kernel. The end result is that eBPF replaces long, sequential
iptables entries when routing traffic to Pods with a more efficient
programmatic approach.
Performance tests for throughput, CPU usage and latency show that eBPF scales well even with 1 million rules. iptables doesn’t scale that well and even with a low number of rules like 1k or 10k shows a considerable performance hit when compared to eBPF.
eBPF has been evolving at an insane pace in recent years, unlocking what was previously outside the scope of the kernel. This is made possible by the efficient programmability that BPF provides at hook points that are deeply integrated in the Linux kernel. Tasks that previously required custom kernel development and kernel recompilation can now be achieved with efficient BPF programs within the safe boundaries of the BPF sandbox, which leads to it being a very intriguing choice for Kubernetes networking.