Dealing with storage is a core challenge when running complex applications on Kubernetes. While many applications operate just fine using a cloud database or blob storage, some applications have performance or design requirements requiring local storage.
Note: For performance benchmarks see [Benchmarking AWS CSI Drivers](<{{ relref “/post/kubernetes/benchmarking-aws-csi-drivers” }}).
When this is the case, developers and cluster operators rely on Container Storage Interface (CSI) implementations to provide local storage for Pods. When running on the AWS cloud, no less than four CSI providers are available for us to use: Elastic Block Storage, Elastic File System, FSx for Lustre, and AWS File Cache. This article compares these four different local storage options to help you choose the right option for your application.
This article assumes you are familiar with the general concept of Kubernetes volumes. The Container Storage Interface (CSI) and related drivers are the standard for exposing arbitrary block and file storage systems to Kubernetes Pods under the Volume abstraction. The CSI allows third-party storage providers to write and deploy plugins exposing new storage systems in Kubernetes without ever having to touch the core Kubernetes code.
Local Ephemeral Volumes
Every Node in a Kubernetes cluster is backed by the locally
attached root file system. By default, this storage medium is made
available to Pods as ephemeral storage with no long-term guarantee about
durability. Pods use this local storage for scratch space, caching, and
for logs. The kubelet agent running on the Node also uses this kind of
storage to hold node-level logs, container images, and the writable
layers of running containers.
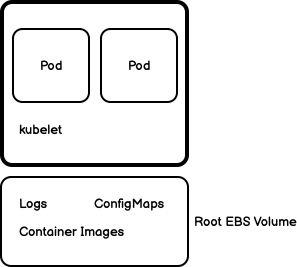
Pods can leverage this local storage for a few use cases: ConfigMaps, Secrets, access to the Kubernetes Downward API or as generic scratch space. Since this article is dealing with local storage, we will only cover the generic scratch space here.
A Pod can request access to local storage from the Node it is running on
by declaring a volume of type emptyDir and mounting that to the
container.
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
sizeLimit: 500Mi
An emptyDir volume is first created when a Pod is assigned to a node, and
exists as long as that Pod is running on that node. As the name says, the
emptyDir volume is initially empty. All containers in the Pod can read
and write the same files in the emptyDir volume, though that volume can
be mounted at the same or different paths in each container. When a Pod
is removed from a node for any reason, the data in the emptyDir is
deleted permanently.
emptyDir problems are great for use as a generic storage mechanism for
emptyDir storage will be available across container (not Pod) restarts
and helps guard against crashes. Pods. You can use them for
check-pointing long-running calculations, or for holding files in
a short-lived disk or memory-based cache. It’s worth noting that for
simple uses cases, emptyDir may be all you need for your workload.
The main drawback of using emptyDir is that the storage you are asking
for is shared between the uses cases kubelet has on the host node and
all other Pods on that node. If the storage is filled up from another
source (such as log files or container images), the emptyDir may run
out of capacity and your Pod’s request for local storage will be denied.
Persistent Volumes
Ephemeral storage can pose significant challenges for complex
applications. One of these challenges arises when a container experiences
a crash or is intentionally stopped. In such cases, the container’s state
is not preserved, resulting in the loss of all files created or modified
during its runtime. In the event of a crash, the kubelet component
restarts the container, but it does so with a clean slate, devoid of any
previously existing data.
Persistent volumes are implemented on Kubernetes using container storage interface (CSI) drivers. As of writing, there are four different CSI drivers available that provide different characteristics.
Elastic Block Storage
The first storage driver we will look at is Elastic Block Storage via aws-ebs-csi-driver. The EBS CSI driver is likely the first choice for most workloads requiring persistent storage.
Volumes provisioned using EBS are mounted to the local node and made available for exclusive use by the Pod.
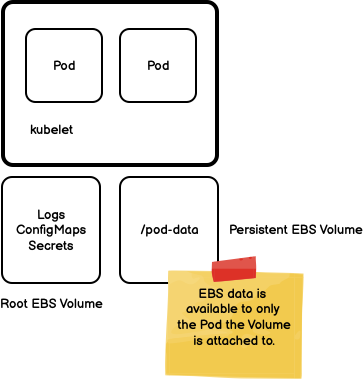
The data stored in an EBS volume persists across Pod restarts. By combining EBS volumes with StatefulSets, you can create applications with data that persists across Pod restarts.
For example, a stateful service like Kafka can be deployed on Kubernetes using persistent volumes as in the following diagram. Here, each Kafka Pod writes data to their local persistent volume claim. Whenever the Pod restarts, the local volume is re-attached to the Pod and any data that was written to the local volume is available once again.
For example, the following diagram from Google’s Kafka deployment guid shows how each Kafka node has access to its own persistent EBS volume.

Cost
EBS has different cost characteristics depending on the type of volume being provisioned and the I/O demands of your workload. Generally speaking the more storage and the more high demanding I/O, the higher the cost.
Notably, EBS is the cheapest option of the available CIS drivers on the AWS cloud.
Performance
EBS has different performance characteristics depending on the EBS volume type and capacity provisioned.
io2 volumes can achieve up to 64,000 IOPS and 1,000 MB/s of throughput
per volume. Whereas gp3 volumes achieve 3,000 IOPS and 125 MB/s for
normal use cases. The exact performance characteristics can be tuned
based on the needs of your application.
Durability
Durability guarantees range from 99.8 - 99.9% durability for gp3
volumes up to 99.999% durability for io2 volumes.
Size Constraints
1 GB up to 16 TB per volume.
Limitations
The biggest limitation of EBS volumes is that the volume is only accessible to a single Pod — multiple Pods cannot read/write from the same volume.
EBS volumes can also be treated as ephemeral storage that does not
persist when a Pod is deleted. By specifying a volume of type ephemeral
the Kubernetes control plane will delete the volume after the Pod that
owns it is deleted.
apiVersion: v1
kind: Pod
metadata:
name: ebs-ephemeral
spec:
containers:
- name: app
image: centos
command: ["/bin/sh"]
args: ["-c", "while true; do echo $(date -u) >> /data/out; sleep 5; done"]
volumeMounts:
- name: scratch-volume
mountPath: /data
volumes:
- name: scratch-volume
ephemeral:
volumeClaimTemplate:
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "ebs-default-storage"
Elastic File System Volumes
The next choice for storage driver is Elastic File System via aws-ebs-csi-driver. The EBS CSI driver is likely the first choice for most workloads requiring persistent storage.
Volumes provisioned using EFS are mounted to the local node as a network file system (NFS). As an NFS, any number of Pods can be mounted to the same storage path and have access to the same shared data. This makes a new class of applications available for Kubernetes where multiple Pods can access the same shared file system.
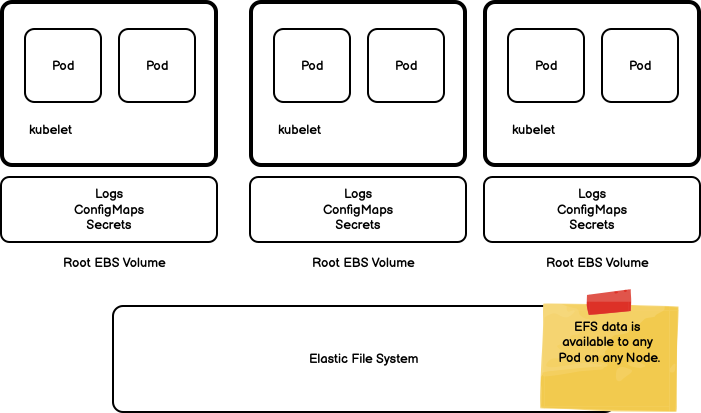
This configuration allows you to create a quasi-statefulset: Pods can be dynamically scaled horizontally but still have access to persistent stable storage.
Cost
EFS charges for both storage and access to data. Storage is calculated per GB and access is charged per available throughput, which depends on your workload.
Generally speaking EFS will be more expensive than EBS.
Performance
EFS in general purpose mode supports up to 55,000 IOPS. Overall throughput is dependent on how much throughput you purchase for your workload. Getting the right level of throughput is as much art as it is science and will hopefully be the subject of another post here.
Generally speaking though, EFS will be less performant than EBS for similar workloads.
Durability
EFS provides 99.999999999 percent (11 9s) durability and up to 99.99 percent (4 9s) of availability. Similar to Amazon S3.
Size Constraints
None. EFS will scale up to the size of your storage needs.
Limitations
Since Amazon EFS is an elastic file system, it doesn’t really enforce any file system capacity. The actual storage capacity value in a persistent volume and persistent volume claim is not used when creating the file system.
Amazon FSx for Lustre
Lustre is an open-source, parallel file system that is best known in the high-performance computing environment. Lustre is best suited for use cases where the size of the data exceeds the capacity of a single server or storage device.
A basic installation of the Lustre file system is shown below.
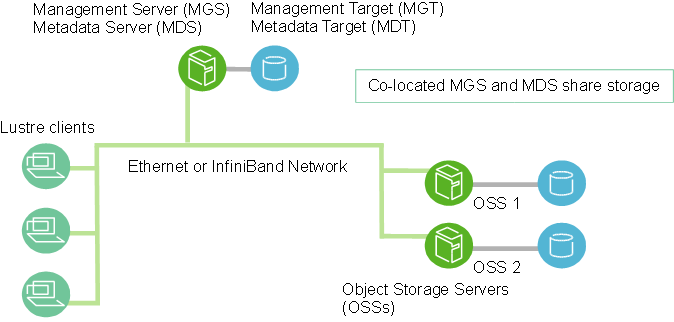
- Management Server (MGS)
- The MGS stores configuration information for all the Lustre file systems in a cluster and provides this information to other Lustre components. Each Lustre target contacts the MGS to provide information, and Lustre clients contact the MGS to retrieve information.
- Metadata Servers (MDS)
- The MDS makes metadata stored in one or more MDTs available to Lustre clients. Each MDS manages the names and directories in the Lustre file system(s) and provides network request handling for one or more local MDTs.
- Metadata Targets (MDT)
- Each filesystem has at least one MDT, which holds the root directory. The MDT stores metadata (such as filenames, directories, permissions and file layout) on storage attached to an MDS. Each file system has one MDT. An MDT on a shared storage target can be available to multiple MDSs, although only one can access it at a time. If an active MDS fails, a second MDS node can serve the MDT and make it available to clients. This is referred to as MDS failover.
- Object Storage Servers (OSS)
- The OSS provides file I/O service and network request handling for one or more local OSTs. Typically, an OSS serves between two and eight OSTs, up to 16 TiB each. A typical configuration is an MDT on a dedicated node, two or more OSTs on each OSS node, and a client on each of the compute nodes.
- Object Storage Target (OST):
- User file data is stored in one or more objects, each object on a separate OST in a Lustre file system. The number of objects per file is configurable by the user and can be tuned to optimize performance for a given workload.
- Lustre clients:
- Lustre clients are computational, visualization or desktop nodes that are running Lustre client software, allowing them to mount the Lustre file system.
Although the Lustre architecture is fairly complicated, AWS can manage it on our behalf, and we can focus on using it as storage for our Kubernetes service.
Cost
Amazon FSx for Lustre charges for both storage and access to data. At the highest performance level, AWS charges $0.60 per GB per month. In contrast, EBS charges $0.125 per GB per month making Lustre significantly more expensive.
Performance
AWS FSx for Lustre charges different rates depending on the amount of throughput provisioned for your workload. The throughput ranges from a low end of 125 MB per second up to 1 GB per second.
All Lustre clusters provide millions of IOPS.
Durability
Lustre can operate in two modes, depending on your use case. Persistent mode stores data on replicated disks. If a file server becomes unavailable it is replaced automatically and within minutes. In the meantime, client requests for data on that server transparently retry and eventually succeed after the file server is replaced. With persistent file systems, data is replicated on disks and any failed disks are automatically replaced behind the scenes, transparently, leading to high durability.
Scratch mode is intended for data that does not need to persist, and you are okay with losing. Operating Lustre in scratch mode provides worse durability and availability with AWS advertising 99.8% availability and durability for 10 TB of data.
Size Constraints
None. Lustre can scale indefinitely with your workload.
Amazon File Cache
Amazon File Cache is a caching solution that integrates with S3 storage. S3 doesn’t have native caching capabilities. After pairing File Cache with an S3 bucket, Amazon File Cache loads data from on-premises or cloud storage services into the cache automatically the first time data is accessed by the workload. File Cache transparently presents data from your Amazon S3 buckets as a unified set of files and directories and allows you to write results back to your datasets.
Amazon File Cache is built on Lustre, and provides scale-out performance that increases linearly with an Amazon File Cache’s size. Effectively, Amazon File Cache is a Lustre cluster with additional automation to serve the file caching use cases. Clients that need to access the cache install the Lustre client and use that client to access cached data. AWS handles expiration of least recently used data on your behalf.
Cost
Amazon File Cache is the most expensive storage option at $1.330 per GB per month.
Performance
Because File Cache is based on Lustre, performance characteristics are similar to Lustre.
Durability
File Cache is meant to cache data, and not be the source of truth. Since it is based on Lustre, we can likely compare durability to Lustre in scratch mode which provides 99.8% availability and durability for 10 TB of data.
Size Constraints
There is no effective limit for Amazon File Cache size.
Recommendations
There are now four different CSI options available for storage on a Kubernetes cluster running in AWS.
For most use cases, EBS is the best storage option. It is fast, and it is the cheapest option. It also supports both ephemeral and persistent volumes. The only caveat with EBS is that the data is only available in the local Pod that the EBS volume is attached to. Data cannot be shared between Pods.
If you must have data available to multiple Pods, EFS is the next logical choice. EFS can scale to any level and provides extreme durability and availability guarantees. The only thing it doesn’t provide is high-performance for certain workloads. If you require a high performance option (make sure to test!), you should reach for FSx for Lustre or File Cache.
FSx for Lustre is suited for high-performance computing workloads. This includes sharing file data used for doing data science or machine learning with client machines. File Cache tunes Lustre to the more specific use case of caching frequently used S3 data in a performant manner. This caching functionality comes at a cost, but relieves application developers of the burden of managing Lustre as a cache.
| Name | CSI Driver Name | Persistence | Access Modes | Cost (less is better) | Performance (more is better) | Durability (more is better) |
|---|---|---|---|---|---|---|
| Elastic Block Storage | ebs.csi.aws.com | Persistent or Ephemeral | Single Pod | 💰 | ⚡⚡⚡⚡ | 🪨🪨🪨 |
| Elastic File System | efs.csi.aws.com | Persistent | Multiple Pods | 💰💰 | ⚡ | 🪨🪨🪨🪨 |
| FSx for Lustre | fsx.csi.aws.com | Persistent | Multiple Pods | 💰💰💰 | ⚡⚡ | 🪨 |
| File Cache System | filecache.csi.aws.com | Persistent | Multiple Pods | 💰💰💰💰 | ⚡⚡ | 🪨 |