Kubernetes was built to run distributed systems over a cluster of machines. The very nature of distributed systems makes networking a central and necessary component of Kubernetes deployment, and understanding the Kubernetes networking model will allow you to correctly run, monitor and troubleshoot your applications running on Kubernetes.
Networking is a vast space with a lot of mature technologies. For people unfamiliar with the landscape, this can be uncomfortable because most people have existing preconceived notions about networking, and there are a lot of both new and old concepts to understand and fit together into a coherent whole. A non-exhaustive list might include technologies like network namespaces, virtual interfaces, IP forwarding, and network address translation. This guide intends to demystify Kubernetes networking by discussing each of Kubernetes dependent technologies along with descriptions on how those technologies are used to enable the Kubernetes networking model.
This guide is fairly long and divided in several sections. We start by discussing some basic Kubernetes terminology to ensure terms are being used correctly throughout the guide, then discuss the Kubernetes networking model and the design and implementation decisions that it imposes. This is followed by the longest and most interesting part of this guide: an in-depth discussion on how traffic is routed within Kubernetes using several different use cases.
If any networking terminology is unfamiliar to you, there is a glossary of networking terms appended to this guide.
1 Kubernetes Basics
Kubernetes is built from a few core concepts that are combined into greater and greater functionality. This section lists each of these concepts and provides a brief overview to help facilitate the discussion. There is much more to Kubernetes than what is listed here, but this section should serve as a primer and allow the reader to follow along in later sections. If you are already familiar with Kubernetes, feel free to skip over this section.
1.1 Kubernetes API server
In Kubernetes, everything is an API call served by the Kubernetes API
server (kube-apiserver). The API server is a gateway to an
etcd datastore that maintains the
desired state of your application cluster. To update the state of
a Kubernetes cluster, you make API calls to the API server describing your
desired state.
1.2 Controllers
Controllers are the core abstraction used to build Kubernetes. Once you’ve declared the desired state of your cluster using the API server, controllers ensure that the cluster’s current state matches the desired state by continuously watching the state of the API server and reacting to any changes. Controllers operate using a simple loop that continuously checks the current state of the cluster against the desired state of the cluster. If there are any differences, controllers perform tasks to make the current state match the desired state. In pseudo-code:
while true:
X = currentState()
Y = desiredState()
if X == Y:
return # Do nothing
else:
do(tasks to get to Y)
For example, when you create a new Pod using the API server, the
Kubernetes scheduler (a controller) notices the change and makes
a decision about where to place the Pod in the cluster. It then writes
that state change using the API server (backed by etcd). The kubelet (a
controller) then notices that new change and sets up the required
networking functionality to make the Pod reachable within the cluster.
Here, two separate controllers react to two separate state changes to make
the reality of the cluster match the intention of the user.
1.3 Pods
A Pod is the atom of Kubernetes — the smallest deployable object for building applications. A single Pod represents a running workload in your cluster and encapsulates one or more Docker containers, any required storage, and a unique IP address. Containers that make up a pod are designed to be co-located and scheduled on the same machine.
1.4 Nodes
Nodes are the machines running the Kubernetes cluster. These can be bare metal, virtual machines, or anything else. The word hosts is often used interchangeably with Nodes. I will try and use the term Nodes with consistency but will sometimes use the word Virtual Machine to refer to Nodes depending on context.
2 The Kubernetes Networking Model
Kubernetes makes opinionated choices about how Pods are networked. In particular, Kubernetes dictates the following requirements on any networking implementation:
- all Pods can communicate with all other Pods without using network address translation (NAT).
- all Nodes can communicate with all Pods without NAT.
- the IP that a Pod sees itself as is the same IP that others see it as.
Given these constraints, we are left with four distinct networking problems to solve:
- Container-to-Container networking
- Pod-to-Pod networking
- Pod-to-Service networking
- Internet-to-Service networking
The rest of this guide will discuss each of these problems and their solutions in turn.
3 Container-to-Container Networking
Typically, we view network communication in a virtual machine as interacting directly with an Ethernet device, as in Figure 1.
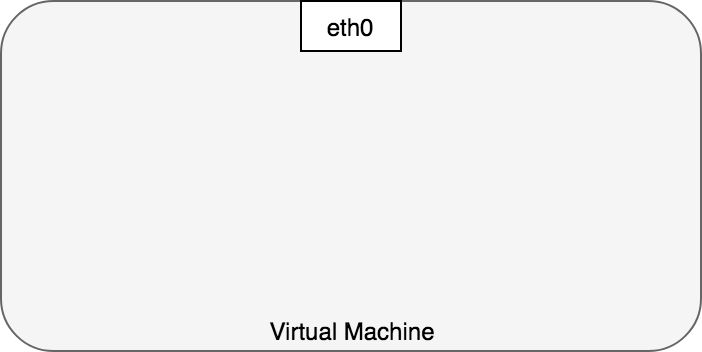
In reality, the situation is more subtle than that. In Linux, each running process communicates within a network namespace that provides a logical networking stack with its own routes, firewall rules, and network devices. In essence, a network namespace provides a brand new network stack for all the processes within the namespace.
As a Linux user, network namespaces can be created using the ip command.
For example, the following command will create a new network namespace
called ns1.
$ ip netns add ns1
When the namespace is created, a mount point for it is created under
/var/run/netns, allowing the namespace to persist even if there is no
process attached to it.
You can list available namespaces by listing all the mount points under
/var/run/netns, or by using the ip command.
$ ls /var/run/netns
ns1
$ ip netns
ns1
By default, Linux assigns every process to the root network namespace to provide access to the external world, as in Figure 2.
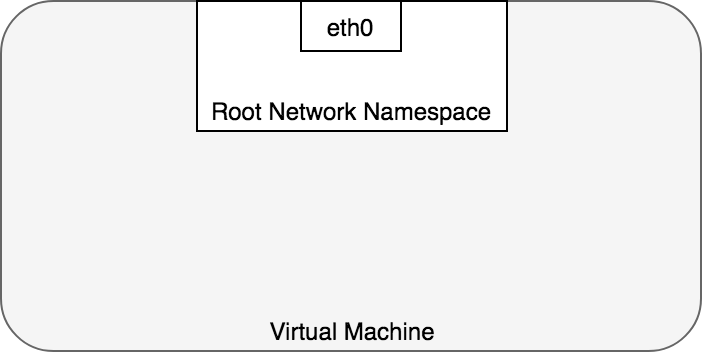
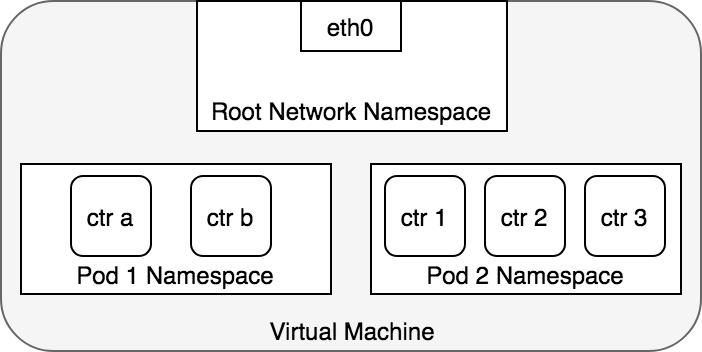
In terms of Docker constructs, a Pod is modelled as a group of Docker
containers that share a network namespace. Containers within a Pod all
have the same IP address and port space assigned through the network
namespace assigned to the Pod, and can find each other via localhost since
they reside in the same namespace. We can create a network namespace for
each Pod on a virtual machine. This is implemented, using
Docker, as a “Pod container” which holds the network namespace open while
“app containers” (the things the user specified) join that namespace with
Docker’s –net=container:ctr*) within a shared namespace.
Applications within a Pod also have access to shared volumes, which are defined as part of a Pod and are made available to be mounted into each application’s filesystem.
4 Pod-to-Pod Networking
In Kubernetes, every Pod has a real IP address and each Pod communicates with other Pods using that IP address. The task at hand is to understand how Kubernetes enables Pod-to-Pod communication using real IPs, whether the Pod is deployed on the same physical Node or different Node in the cluster. We start this discussion by considering Pods that reside on the same machine to avoid the complications of going over the internal network to communicate across Nodes.
From the Pod’s perspective, it exists in its own Ethernet namespace that needs to communicate with other network namespaces on the same Node. Thankfully, namespaces can be connected using a Linux Virtual Ethernet Device or veth pair consisting of two virtual interfaces that can be spread over multiple namespaces. To connect Pod namespaces, we can assign one side of the veth pair to the root network namespace, and the other side to the Pod’s network namespace. Each veth pair works like a patch cable, connecting the two sides and allowing traffic to flow between them. This setup can be replicated for as many Pods as we have on the machine. Figure 4 shows veth pairs connecting each Pod on a VM to the root namespace.
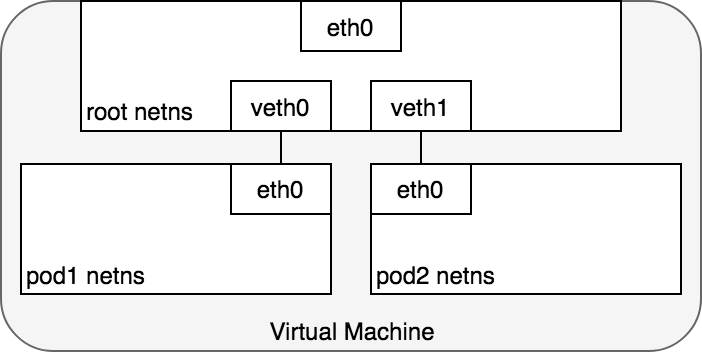
At this point, we’ve set up the Pods to each have their one network namespace so that they believe they have their own Ethernet device and IP address, and they are connected to the root namespace for the Node. Now, we want the Pods to talk to each other through the root namespace, and for this we use a network bridge.
A Linux Ethernet bridge is a virtual Layer 2 networking device used to unite two or more network segments, working transparently to connect two networks together. The bridge operates by maintaining a forwarding table between sources and destinations by examining the destination of the data packets that travel through it and deciding whether or not to pass the packets to other network segments connected to the bridge. The bridging code decides whether to bridge data or to drop it by looking at the MAC-address unique to each Ethernet device in the network.
Bridges implement the ARP protocol to discover the link-layer MAC address associated with a given IP address. When a data frame is received at the bridge, the bridge broadcasts the frame out to all connected devices (except the original sender) and the device that responds to the frame is stored in a lookup table. Future traffic with the same IP address uses the lookup table to discover the correct MAC address to forward the packet to.
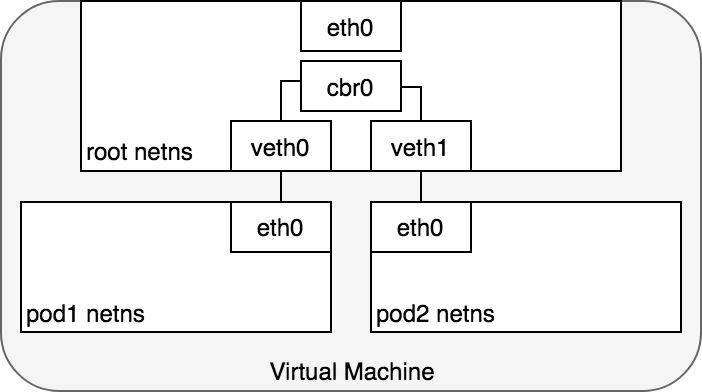
4.1 Life of a packet: Pod-to-Pod, same Node
Given the network namespaces that isolate each Pod to their own networking stack, virtual Ethernet devices that connect each namespace to the root namespace, and a bridge that connects namespaces together, we are finally ready to send traffic between Pods on the same Node. This is illustrated in Figure 6.
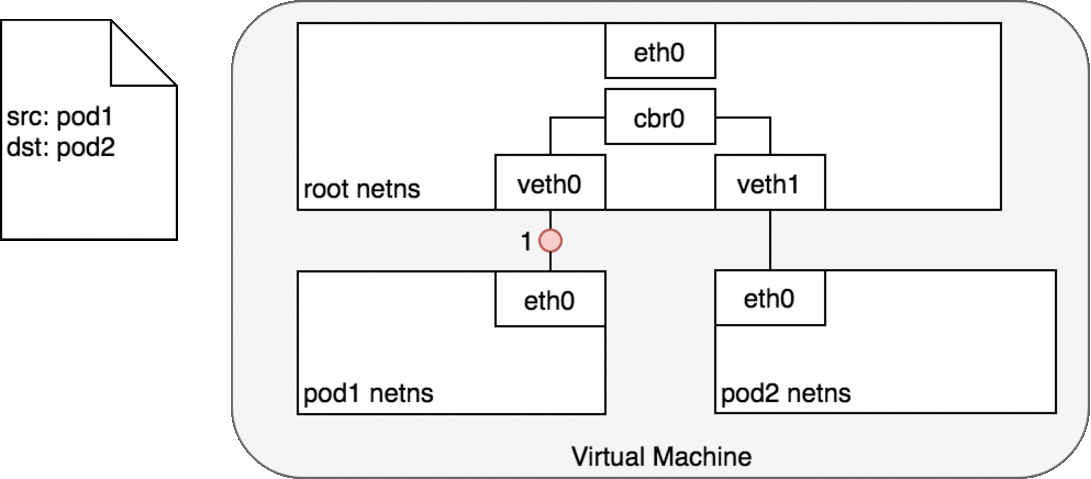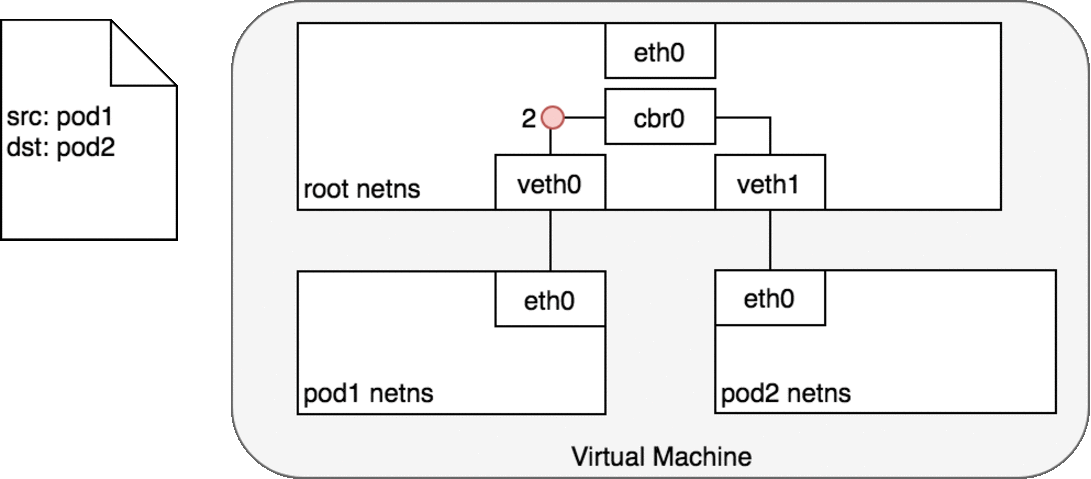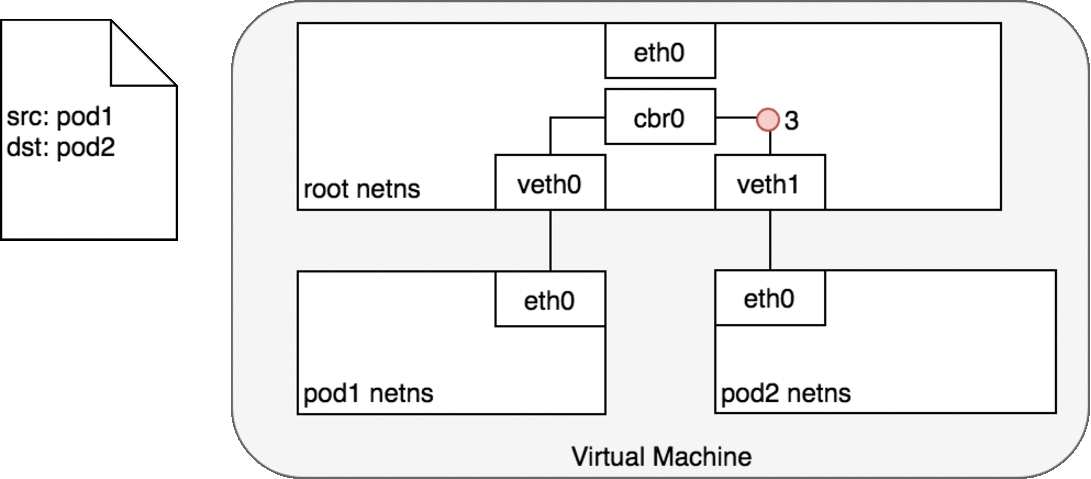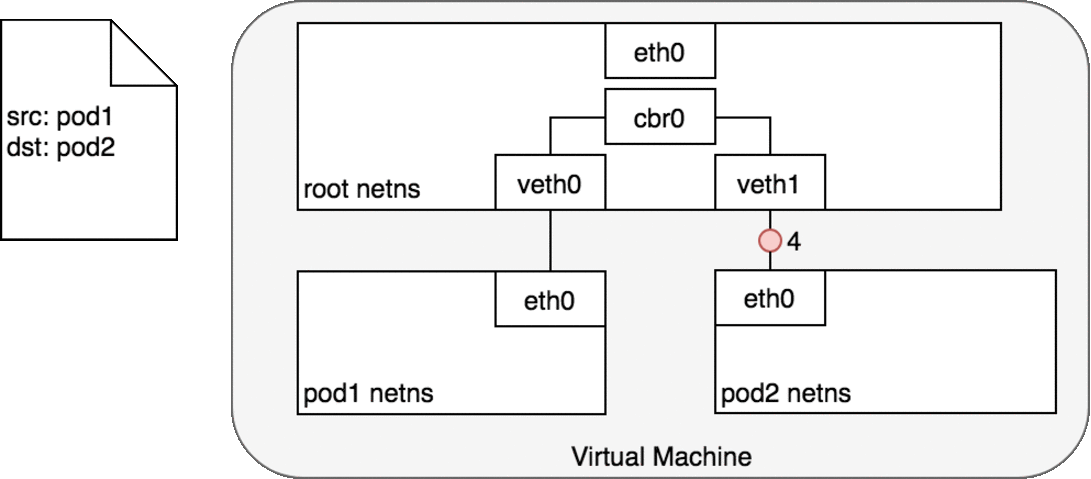
In Figure 6, Pod 1 sends a packet to its own Ethernet device eth0 which
is available as the default device for the Pod. For Pod 1, eth0 is
connected via a virtual Ethernet device to the root namespace, veth0
(1). The bridge cbr0 is configured with veth0 a network segment
attached to it. Once the packet reaches the bridge, the bridge resolves
the correct network segment to send the packet to — veth1 using the ARP
protocol (3). When the packet reaches the virtual device veth1, it is
forwarded directly to Pod 2’s namespace and the eth0 device within that
namespace (4). Throughout this traffic flow, each Pod is communicating
only with eth0 on localhost and the traffic is routed to the correct
Pod. The development experience for using the network is the default
behaviour that a developer would expect.
Kubernetes’ networking model dictates that Pods must be reachable by their IP address across Nodes. That is, the IP address of a Pod is always visible to other Pods in the network, and each Pod views its own IP address as the same as how other Pods see it. We now turn to the problem of routing traffic between Pods on different Nodes.
4.2 Life of a packet: Pod-to-Pod, across Nodes
Having worked out how to route packets between Pods on the same Node, we move on to routing traffic between Pods on different Nodes. The Kubernetes networking model requires that Pod IPs are reachable across the network, but it doesn’t specify how that must be done. In practice, this is network specific, but some patterns have been established to make this easier.
Generally, every Node in your cluster is assigned a CIDR block specifying the IP addresses available to Pods running on that Node. Once traffic destined for the CIDR block reaches the Node it is the Node’s responsibility to forward traffic to the correct Pod. Figure 7 illustrates the flow of traffic between two Nodes assuming that the network can route traffic in a CIDR block to the correct Node.
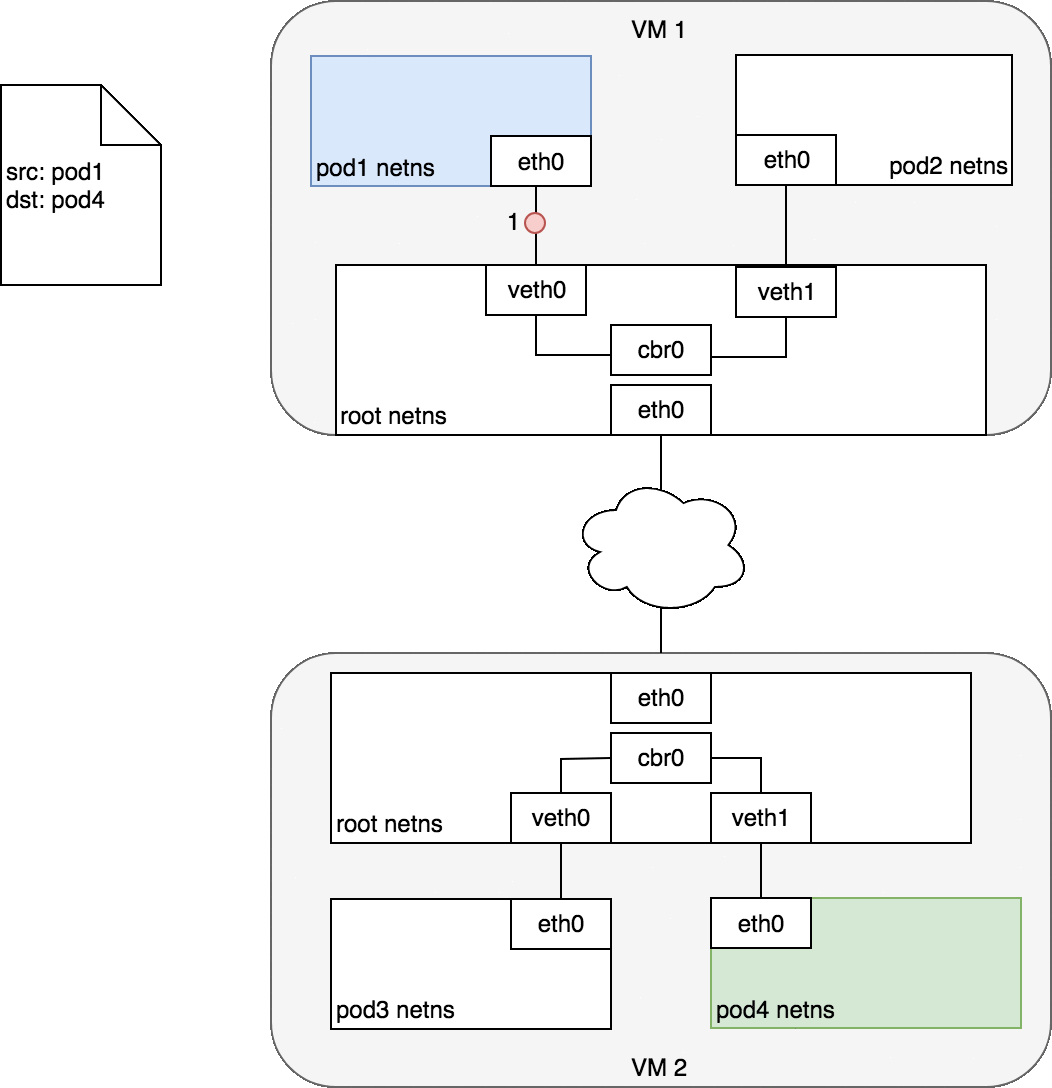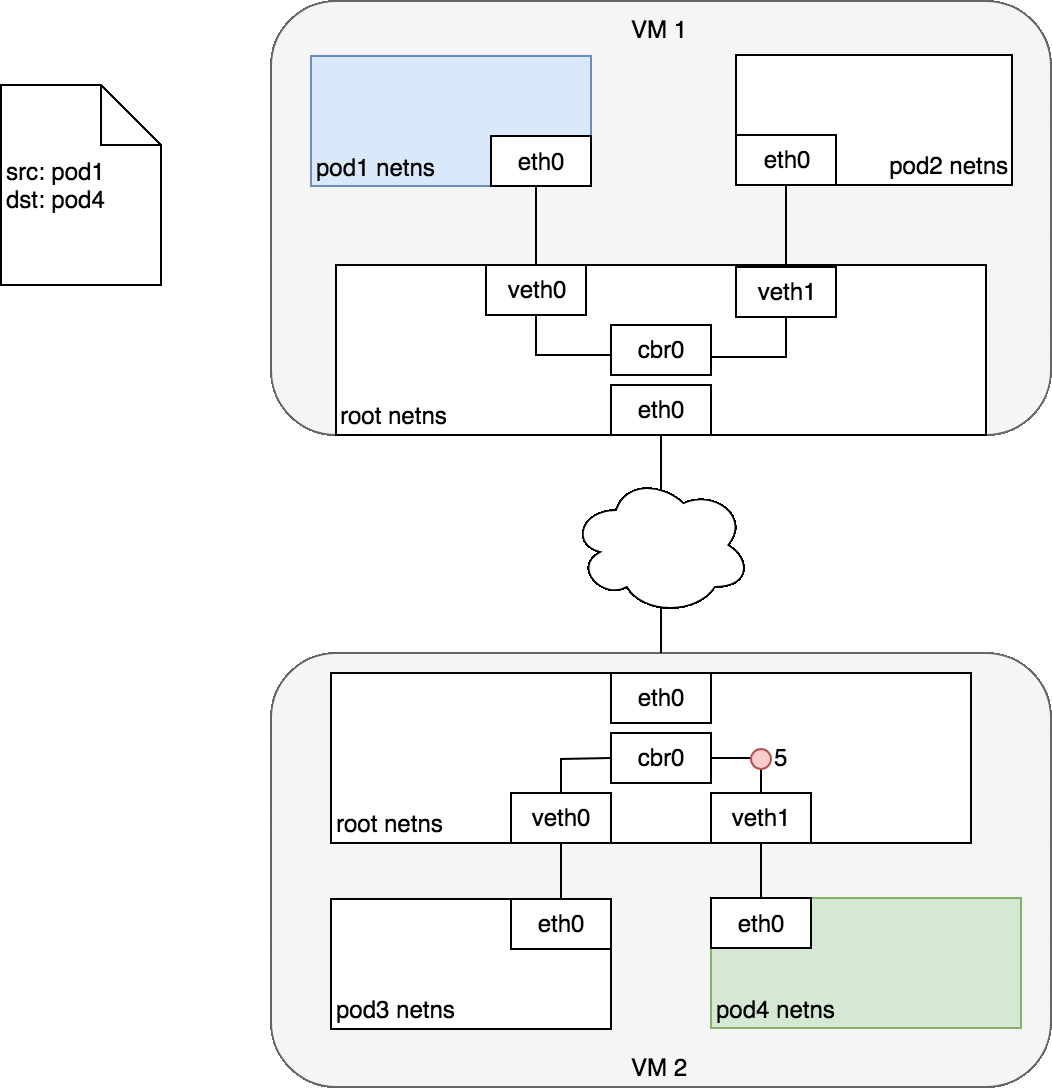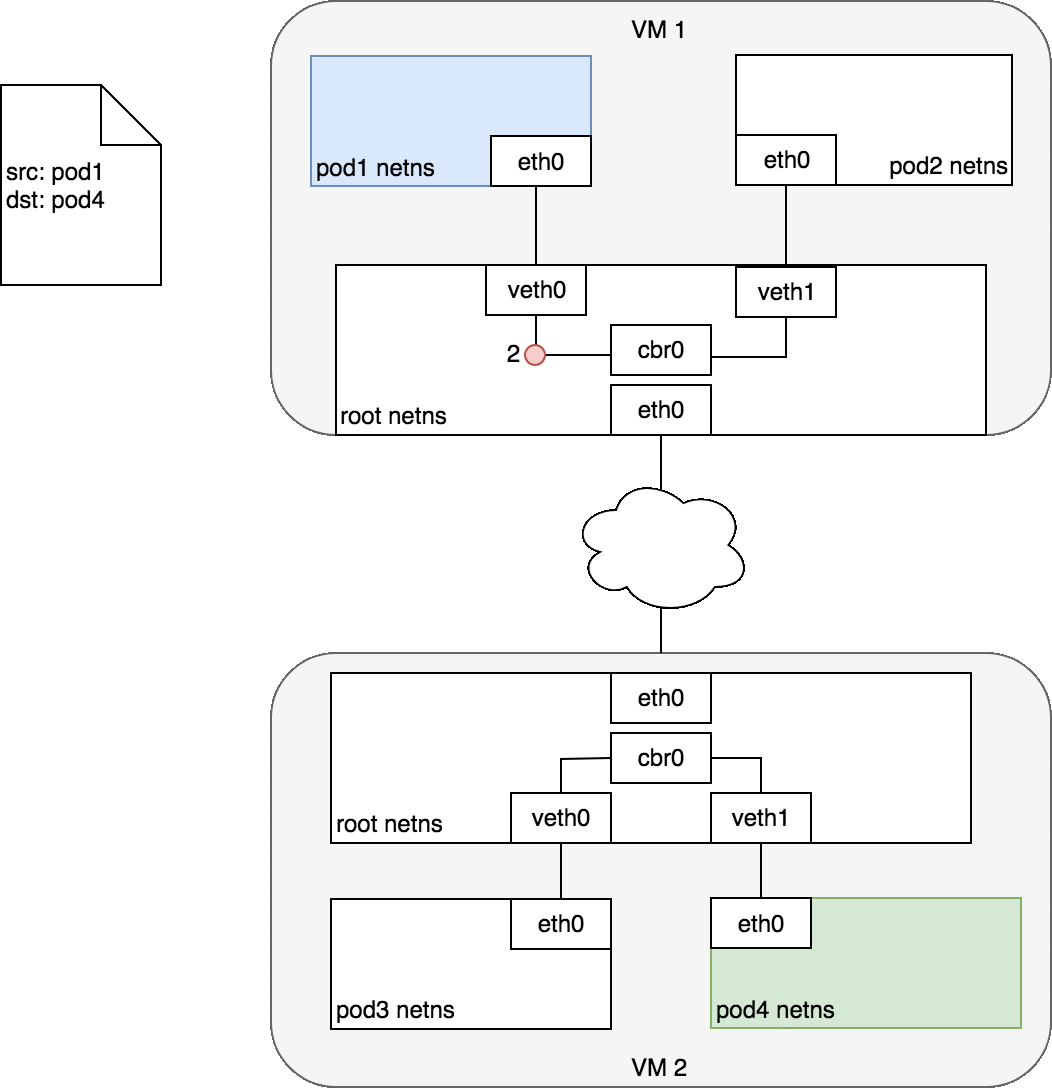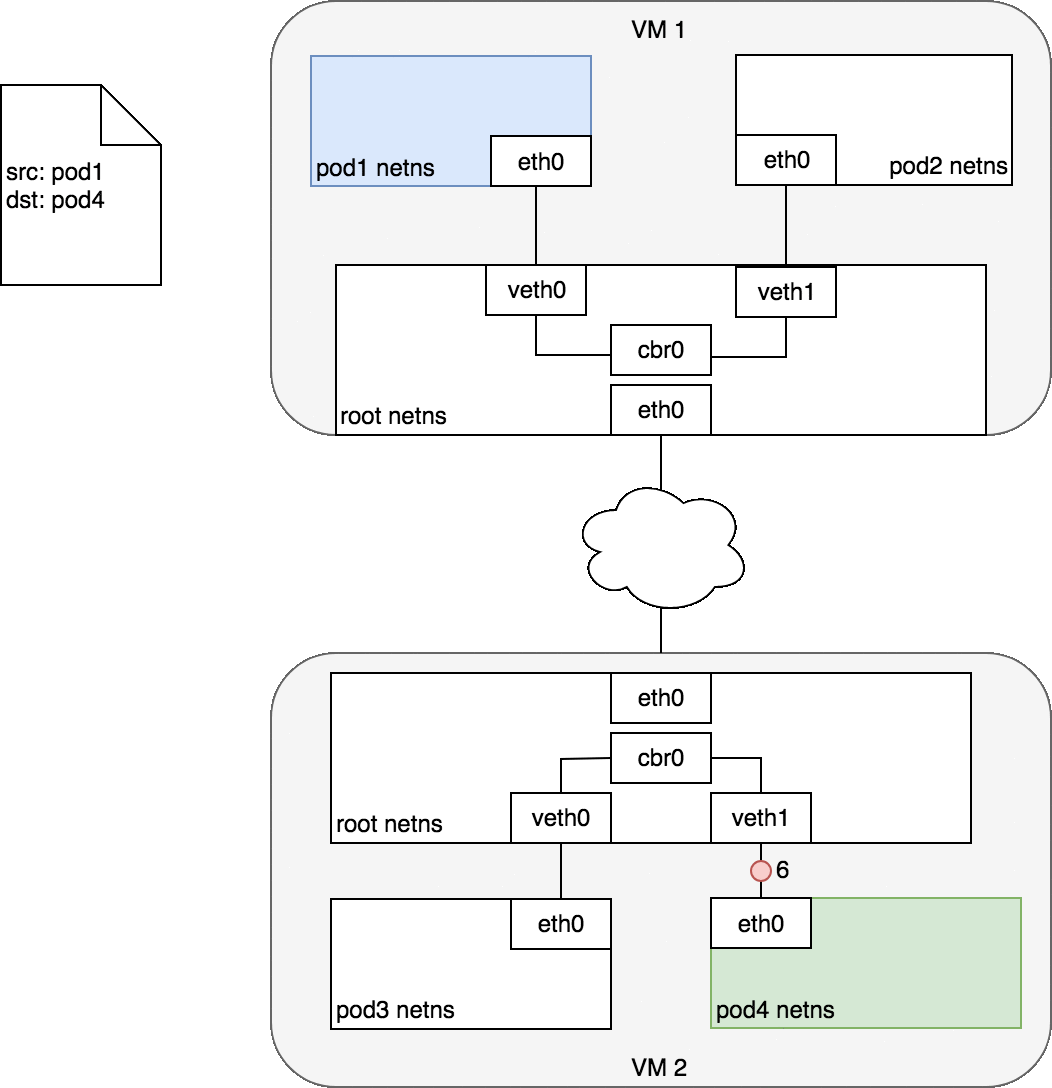
Figure 7 begins with the same request as in Figure 6, except this time,
the destination Pod (highlighted in green) is on a different Node from the
source Pod (higlighted in blue). The packet begins by being sent through
Pod 1’s Ethernet device which is paired with the virtual Ethernet device
in the root namespace (1). Ultimately, the packet ends up at the root
namespace’s network bridge (2). ARP will fail at the bridge because there
is no device connected to the bridge with the correct MAC address for the
packet. On failure, the bridge sends the packet out the default route
— the root namespace’s eth0 device. At this point the route leaves the
Node and enters the network (3). We assume for now that the network can
route the packet to the correct Node based on the CIDR block assigned to
the Node (4). The packet enters the root namespace of the destination Node
(eth0 on VM 2), where it is routed through the bridge to the correct
virtual Ethernet device (5). Finally, the route completes by flowing
through the virtual Ethernet device’s pair residing within Pod 4’s
namespace (6). Generally speaking, each Node knows how to deliver packets
to Pods that are running within it. Once a packet reaches a destination
Node, packets flow the same way they do for routing traffic between Pods
on the same Node.
We conveniently side-stepped how to configure the network to route traffic for Pod IPs to the correct Node that is responsible for those IPs. This is network specific, but looking at a specific example will provide some insight into the issues involved. For example, with AWS, Amazon maintains a container networking plugin for Kubernetes that allows Node to Node networking to operate within an Amazon VPC environment using a Container Networking Interface (CNI) plugin.
The Container Networking Interface (CNI) provides a common API for connecting containers to the outside network. As developers, we want to know that a Pod can communicate with the network using IP addresses, and we want the mechanism for this action to be transparent. The CNI plugin developed by AWS tries to meet these needs while providing a secure and manageable environment through the existing VPC, IAM, and Security Group functionality provided by AWS. The solution to this is using elastic network interfaces.
In EC2, each instance is bound to an elastic network interface (ENI) and
all ENIs are connected within a VPC — ENIs are able to reach each other
without additional effort. By default, each EC2 instance is deployed with
a single ENI, but you are free to create multiple ENIs and deploy them to
EC2 instances as you see fit. The AWS CNI plugin for Kubernetes leverages
this flexibility by creating a new ENI for each Pod deployed to a Node.
Because ENIs within a VPC are already connected within the existing AWS
infrastructure, this allows each Pod’s IP address to be natively
addressable within the VPC. When the CNI plugin is deployed to the
cluster, each Node (EC2 instance) creates multiple elastic network
interfaces and allocates IP addresses to those instances, forming a CIDR
block for each Node. When Pods are deployed, a small binary deployed to
the Kubernetes cluster as a DaemonSet receives any requests to add a Pod
to the network from the Nodes local kubelet process. This binary picks
an available IP address from the Node’s available pool of ENIs and assigns
it to the Pod by wiring the virtual Ethernet device and bridge within the
Linux kernel as described when networking Pods within the same Node. With
this in place, Pod traffic is routeable across Nodes within the cluster.
5 Pod-to-Service Networking
We’ve shown how to route traffic between Pods and their associated IP addresses. This works great until we need to deal with change. Pod IP addresses are not durable and will appear and disappear in response to scaling up or down, application crashes, or Node reboots. Each of these events can make the Pod IP address change without warning. Services were built into Kubernetes to address this problem.
A Kubernetes Service manages the state of a set of Pods, allowing you to track a set of Pod IP addresses that are dynamically changing over time. Services act as an abstraction over Pods and assign a single virtual IP address to a group of Pod IP addresses. Any traffic addressed to the virtual IP of the Service will be routed to the set of Pods that are associated with the virtual IP. This allows the set of Pods associated with a Service to change at any time — clients only need to know the Service’s virtual IP, which does not change.
When creating a new Kubernetes Service, a new virtual IP (also known as a cluster IP) is created on your behalf. Anywhere within the cluster, traffic addressed to the virtual IP will be load-balanced to the set of backing Pods associated with the Service. In effect, Kubernetes automatically creates and maintains a distributed in-cluster load balancer that distributes traffic to a Service’s associated healthy Pods. Let’s take a closer look at how this works.
5.1 netfilter and iptables
To perform load balancing within the cluster, Kubernetes relies on the
networking framework built in to Linux — netfilter. Netfilter is
a framework provided by Linux that allows various networking-related
operations to be implemented in the form of customized handlers. Netfilter
offers various functions and operations for packet filtering, network
address translation, and port translation, which provide the functionality
required for directing packets through a network, as well as for providing
the ability to prohibit packets from reaching sensitive locations within
a computer network.
iptables is a user-space program providing a table-based system for
defining rules for manipulating and transforming packets using the
netfilter framework. In Kubernetes, iptables rules are configured by the
kube-proxy controller that watches the Kubernetes API server for changes.
When a change to a Service or Pod updates the virtual IP address of the
Service or the IP address of a Pod, iptables rules are updated to
correctly route traffic directed at a Service to a backing Pod. The
iptables rules watch for traffic destined for a Service’s virtual IP and,
on a match, a random Pod IP address is selected from the set of available
Pods and the iptables rule changes the packet’s destination IP address
from the Service’s virtual IP to the IP of the selected Pod. As Pods come
up or down, the iptables ruleset is updated to reflect the changing state
of the cluster. Put another way, iptables has done load-balancing on the
machine to take traffic directed to a service’s IP to an actual pod’s IP.
On the return path, the IP address is coming from the destination Pod. In this case iptables again rewrites the IP header to replace the Pod IP with the Service’s IP so that the Pod believes it has been communicating solely with the Service’s IP the entire time.
5.2 IPVS
The latest release (1.11) of Kubernetes includes a second option for in-cluster load balancing: IPVS. IPVS (IP Virtual Server) is also built on top of netfilter and implements transport-layer load balancing as part of the Linux kernel. IPVS is incorporated into the LVS (Linux Virtual Server), where it runs on a host and acts as a load balancer in front of a cluster of real servers. IPVS can direct requests for TCP- and UDP-based services to the real servers, and make services of the real servers appear as virtual services on a single IP address. This makes IPVS a natural fit for Kubernetes Services.
When declaring a Kubernetes Service, you can specify whether or not you want in-cluster load balancing to be done using iptables or IPVS. IPVS is specifically designed for load balancing and uses more efficient data structures (hash tables), allowing for almost unlimited scale compared to iptables. When creating a Service load balanced with IPVS, three things happen: a dummy IPVS interface is created on the Node, the Service’s IP address is bound to the dummy IPVS interface, and IPVS servers are created for each Service IP address.
In the future, expect IPVS to become the default method of in-cluster load-balancing. This change only affects in-cluster load-balancing and throughout the rest of this guide you can safely replace iptables with IPVS for in-cluster load balancing without affecting the rest of the discussion. Let’s now look at the life of a packet through an in-cluster load-balanced Service
5.3 Life of a packet: Pod to Service
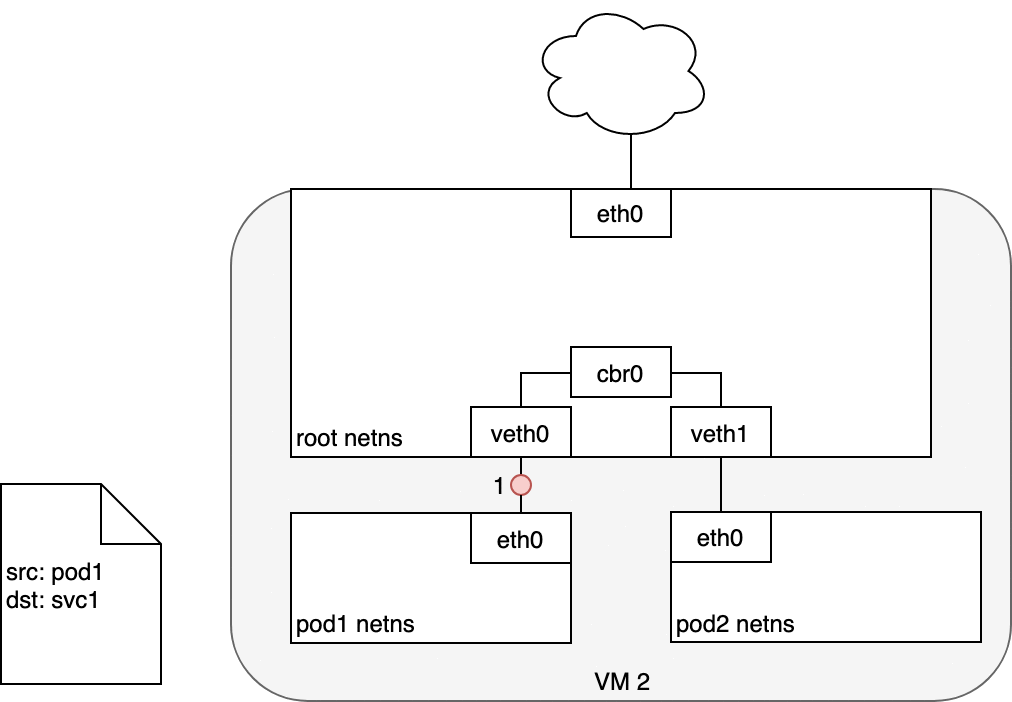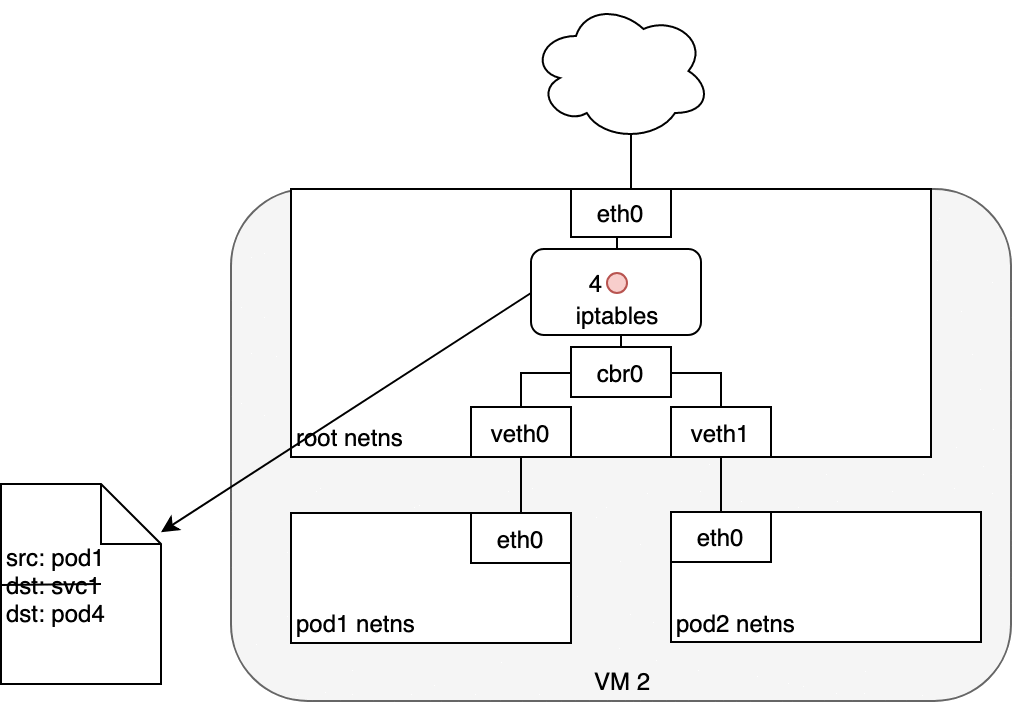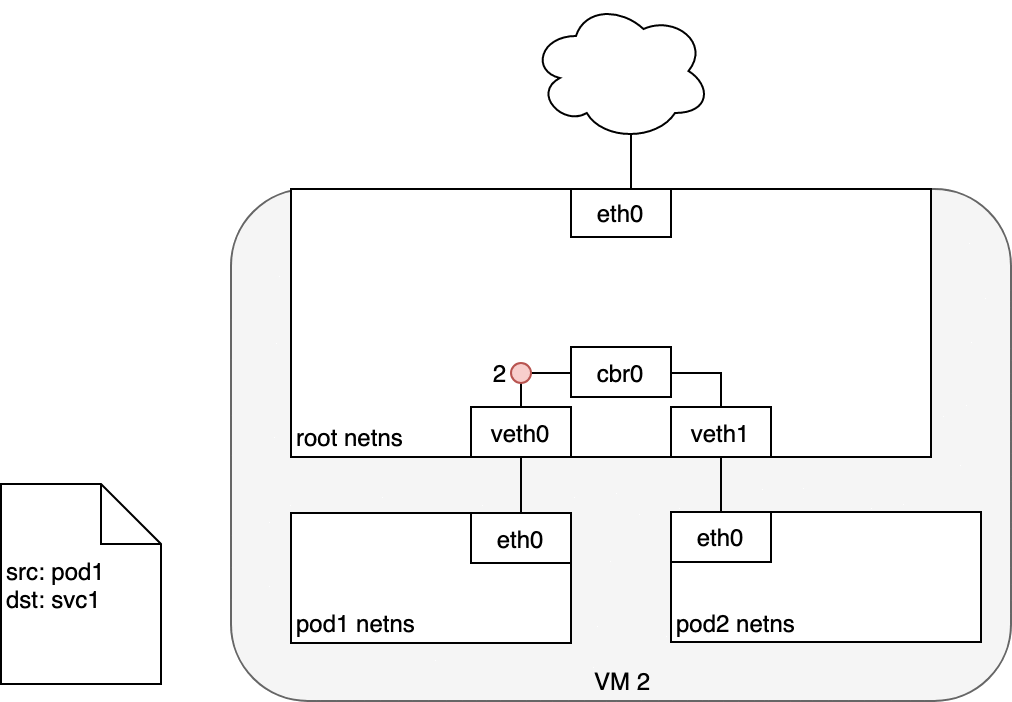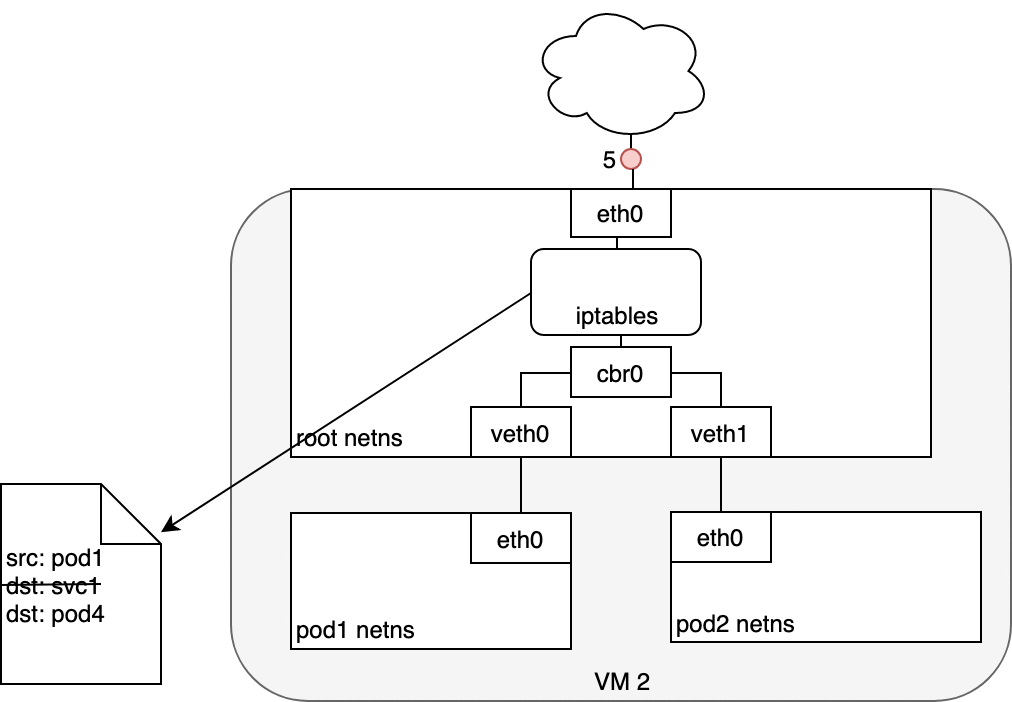
When routing a packet between a Pod and Service, the journey begins in the
same way as before. The packet first leaves the Pod through the eth0
interface attached to the Pod’s network namespace (1). Then it travels
through the virtual Ethernet device to the bridge (2). The ARP protocol
running on the bridge does not know about the Service and so it transfers
the packet out through the default route — eth0 (3). Here, something
different happens. Before being accepted at eth0, the packet is filtered
through iptables. After receiving the packet, iptables uses the rules
installed on the Node by kube-proxy in response to Service or Pod events
to rewrite the destination of the packet from the Service IP to a specific
Pod IP (4). The packet is now destined to reach Pod 4 rather than the
Service’s virtual IP. The Linux kernel’s conntrack utility is leveraged
by iptables to remember the Pod choice that was made so future traffic
is routed to the same Pod (barring any scaling events). In essence,
iptables has done in-cluster load balancing directly on the Node. Traffic
then flows to the Pod using the Pod-to-Pod routing we’ve already examined
(5).
5.4 Life of a packet: Service to Pod
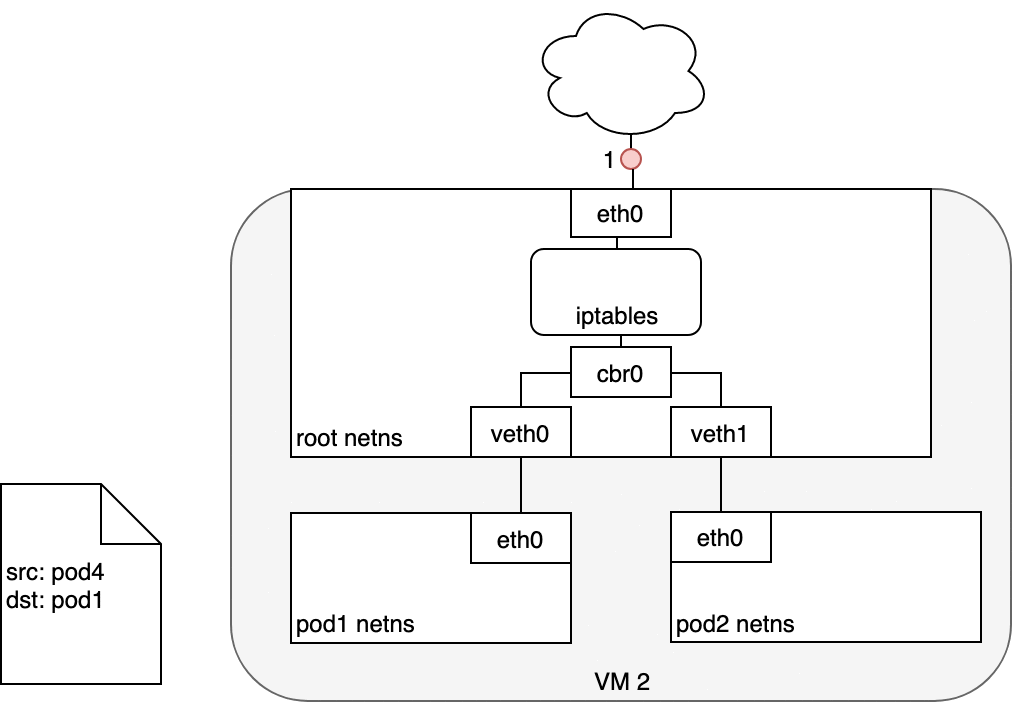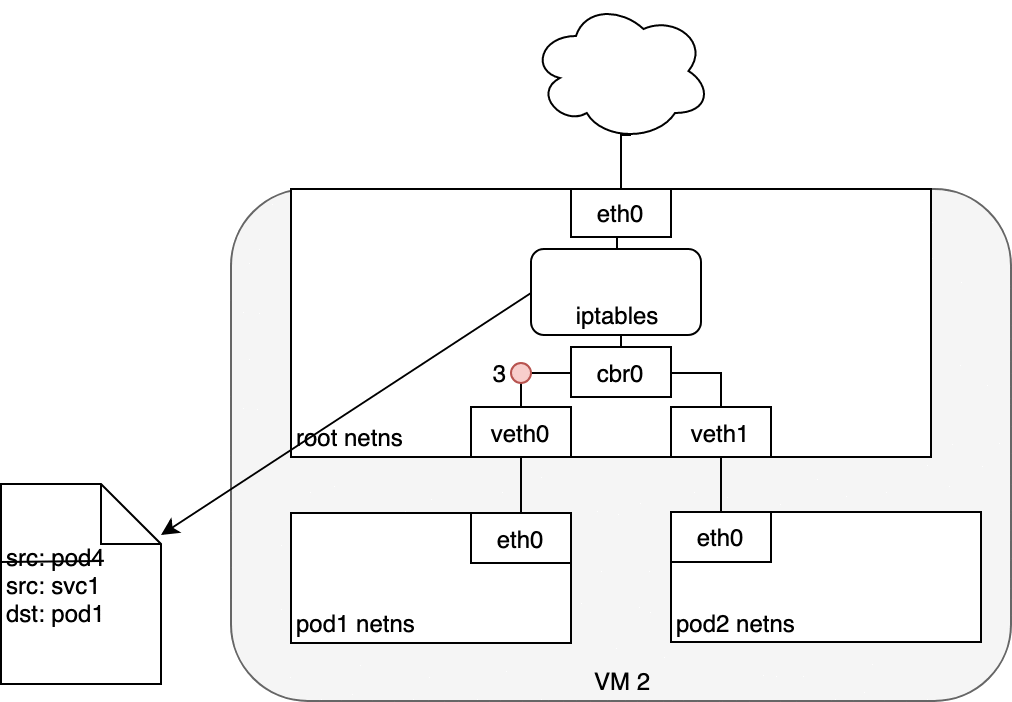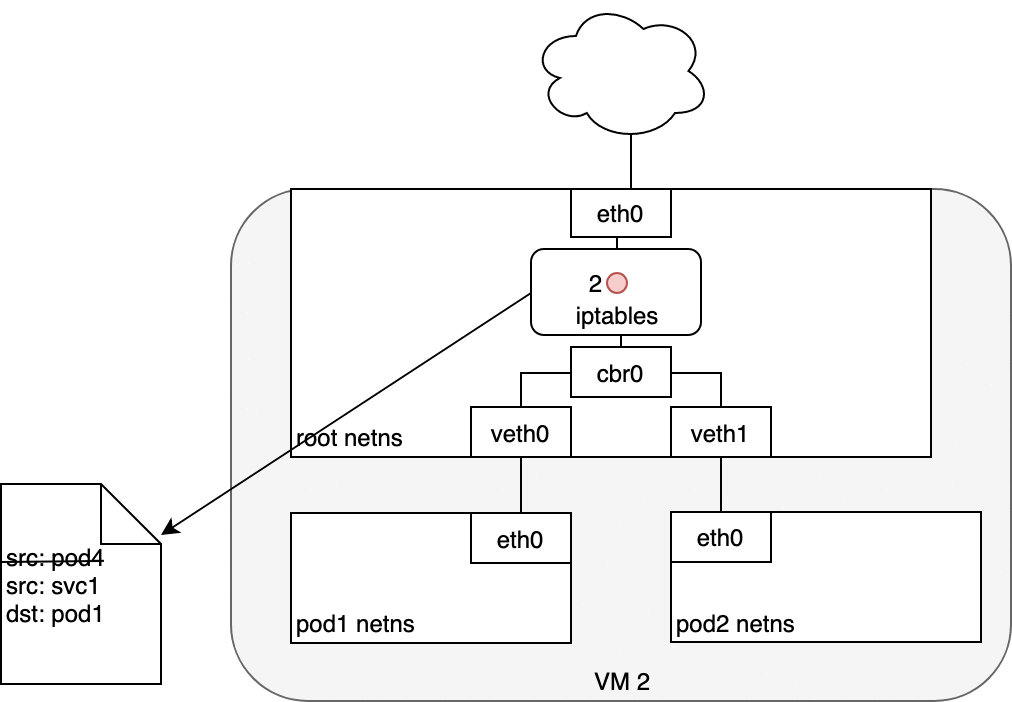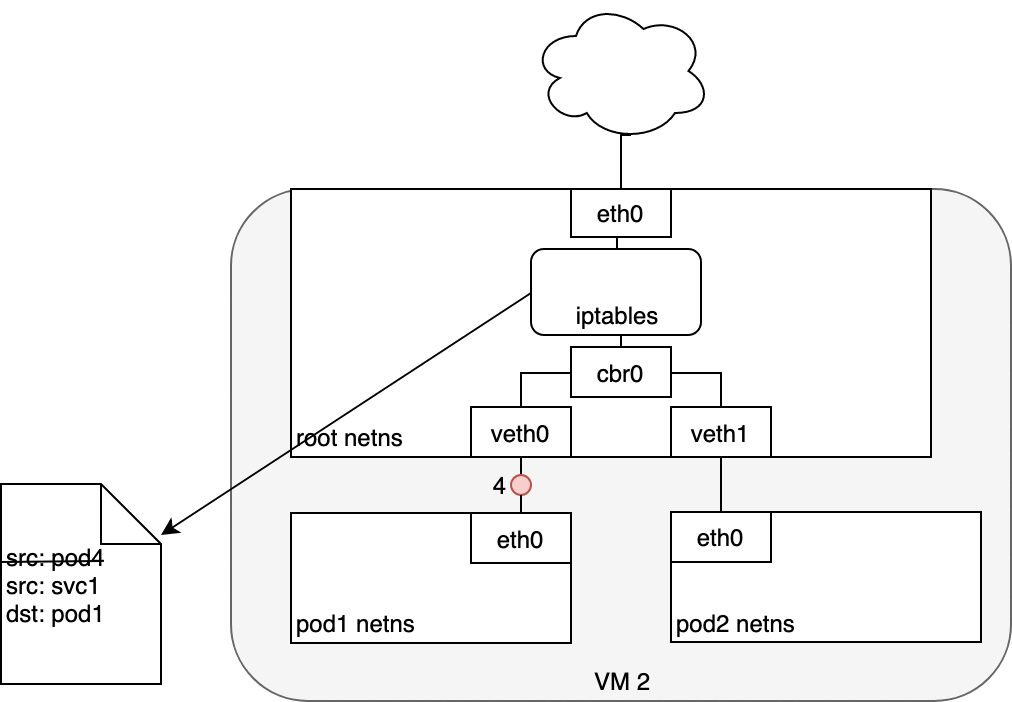
The Pod that receives this packet will respond, identifying the source IP
as its own and the destination IP as the Pod that originally sent the
packet (1). Upon entry into the Node, the packet flows through iptables,
which uses conntrack to remember the choice it previously made and
rewrite the source of the packet to be the Service’s IP instead of the
Pod’s IP (2). From here, the packet flows through the bridge to the
virtual Ethernet device paired with the Pod’s namespace (3), and to the
Pod’s Ethernet device as we’ve seen before (4).
5.5 Using DNS
Kubernetes can optionally use DNS to avoid having to hard-code a Service’s
cluster IP address into your application. Kubernetes DNS runs as a regular
Kubernetes Service that is scheduled on the cluster. It configures the
kubelets running on each Node so that containers use the DNS Service’s
IP to resolve DNS names. Every Service defined in the cluster (including
the DNS server itself) is assigned a DNS name. DNS records resolve DNS
names to the cluster IP of the Service or the IP of a POD, depending on
your needs. SRV records are used to specify particular named ports for
running Services.
A DNS Pod consists of three separate containers:
kubedns: watches the Kubernetes master for changes in Services and Endpoints, and maintains in-memory lookup structures to serve DNS requests.dnsmasq: adds DNS caching to improve performance.sidecar: provides a single health check endpoint to perform healthchecks fordnsmasqandkubedns.
The DNS Pod itself is exposed as a Kubernetes Service with a static
cluster IP that is passed to each running container at startup so that
each container can resolve DNS entries. DNS entries are resolved through
the kubedns system that maintains in-memory DNS representations. etcd
is the backend storage system for cluster state, and kubedns uses
a library that converts etcd key-value stores to DNS entires to rebuild
the state of the in-memory DNS lookup structure when necessary.
CoreDNS works similarly to kubedns but is built with a plugin
architecture that makes it more flexible. As of Kubernetes 1.11, CoreDNS
is the default DNS implementation for Kubernetes.
6 Internet-to-Service Networking
So far we have looked at how traffic is routed within a Kubernetes cluster. This is all fine and good but unfortunately walling off your application from the outside world will not help meet any sales targets — at some point you will want to expose your service to external traffic. This need highlights two related concerns: (1) getting traffic from a Kubernetes Service out to the Internet, and (2) getting traffic from the Internet to your Kubernetes Service. This section deals with each of these concerns in turn.
6.1 Egress — Routing traffic to the Internet
Routing traffic from a Node to the public Internet is network specific and really depends on how your network is configured to publish traffic. To make this section more concrete I will use an AWS VPC to discuss any specific details.
In AWS, a Kubernetes cluster runs within a VPC, where every Node is assigned a private IP address that is accessible from within the Kubernetes cluster. To make traffic accessible from outside the cluster, you attach an Internet gateway to your VPC. The Internet gateway serves two purposes: providing a target in your VPC route tables for traffic that can be routed to the Internet, and performing network address translation (NAT) for any instances that have been assigned public IP addresses. The NAT translation is responsible for changing the Node’s internal IP address that is private to the cluster to an external IP address that is available in the public Internet.
With an Internet gateway in place, VMs are free to route traffic to the Internet. Unfortunately, there is a small problem. Pods have their own IP address that is not the same as the IP address of the Node that hosts the Pod, and the NAT translation at the Internet gateway only works with VM IP addresses because it does not have any knowledge about what Pods are running on which VMs — the gateway is not container aware. Let’s look at how Kubernetes solves this problem using iptables (again).
6.1.1 Life of a packet: Node to Internet
In the following diagram, the packet originates at the Pod’s namespace (1) and travels through the veth pair connected to the root namespace (2). Once in the root namespace, the packet moves from the bridge to the default device since the IP on the packet does not match any network segment connected to the bridge. Before reaching the root namespace’s Ethernet device (3), iptables mangles the packet (3). In this case, the source IP address of the packet is a Pod, and if we keep the source as a Pod the Internet gateway will reject it because the gateway NAT only understands IP addresses that are connected to VMs. The solution is to have iptables perform a source NAT — changing the packet source — so that the packet appears to be coming from the VM and not the Pod. With the correct source IP in place, the packet can now leave the VM (4) and reach the Internet gateway (5). The Internet gateway will do another NAT rewriting the source IP from a VM internal IP to an external IP. Finally, the packet will reach the public Internet (6). On the way back, the packet follows the same path and any source IP mangling is undone so that each layer of the system receives the IP address that it understands: VM-internal at the Node or VM level, and a Pod IP within a Pod’s namespace.
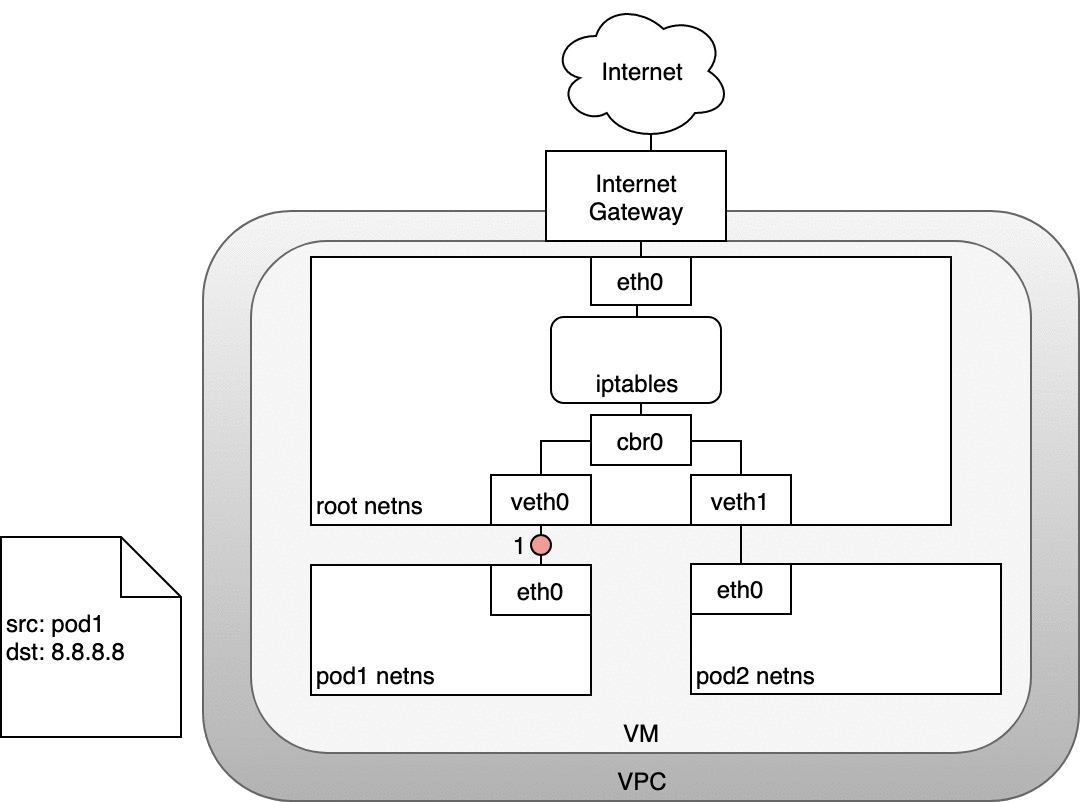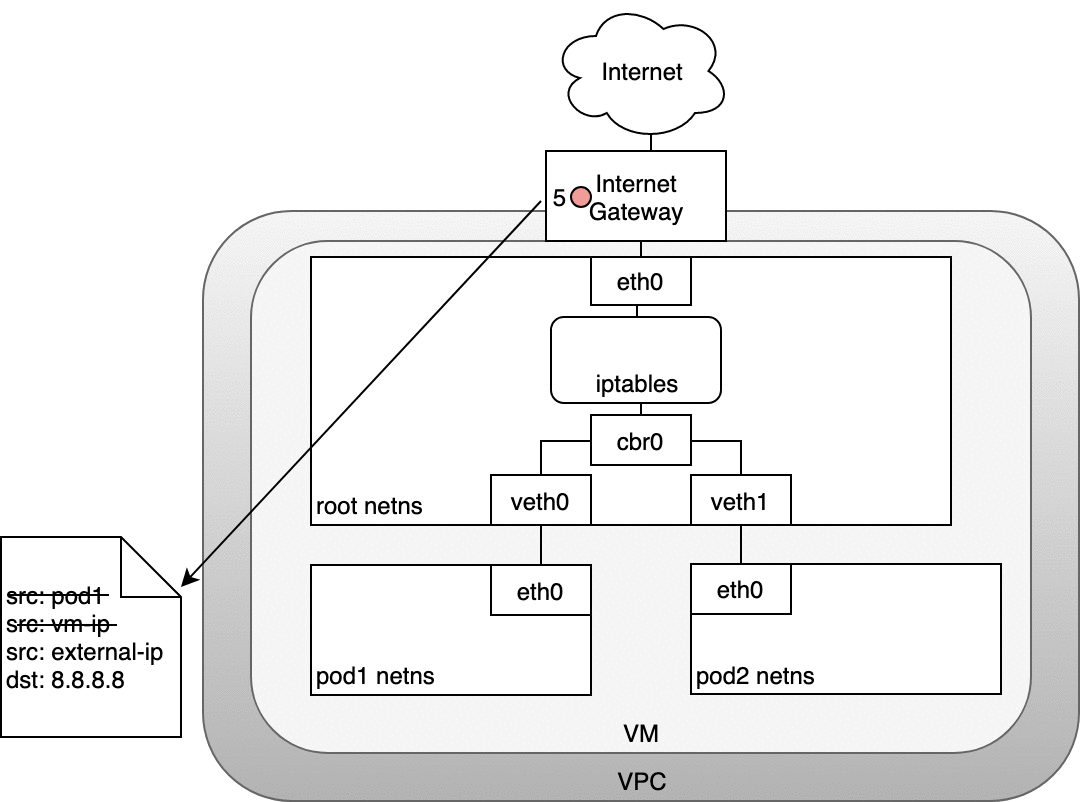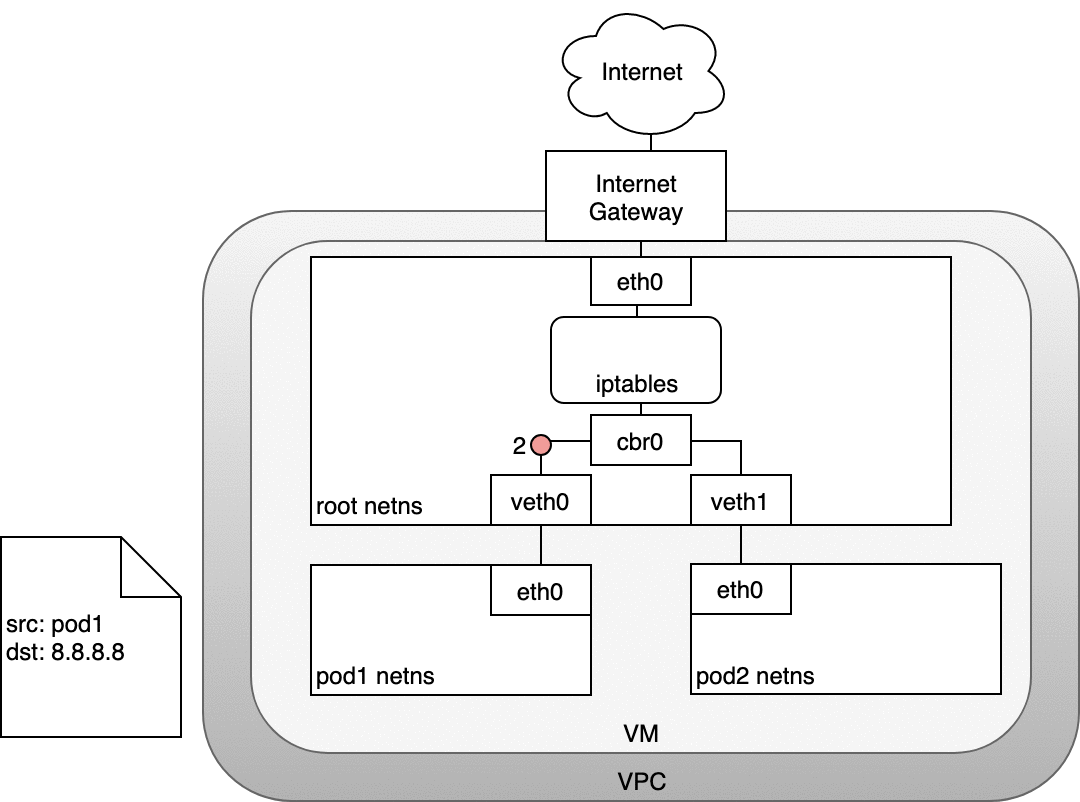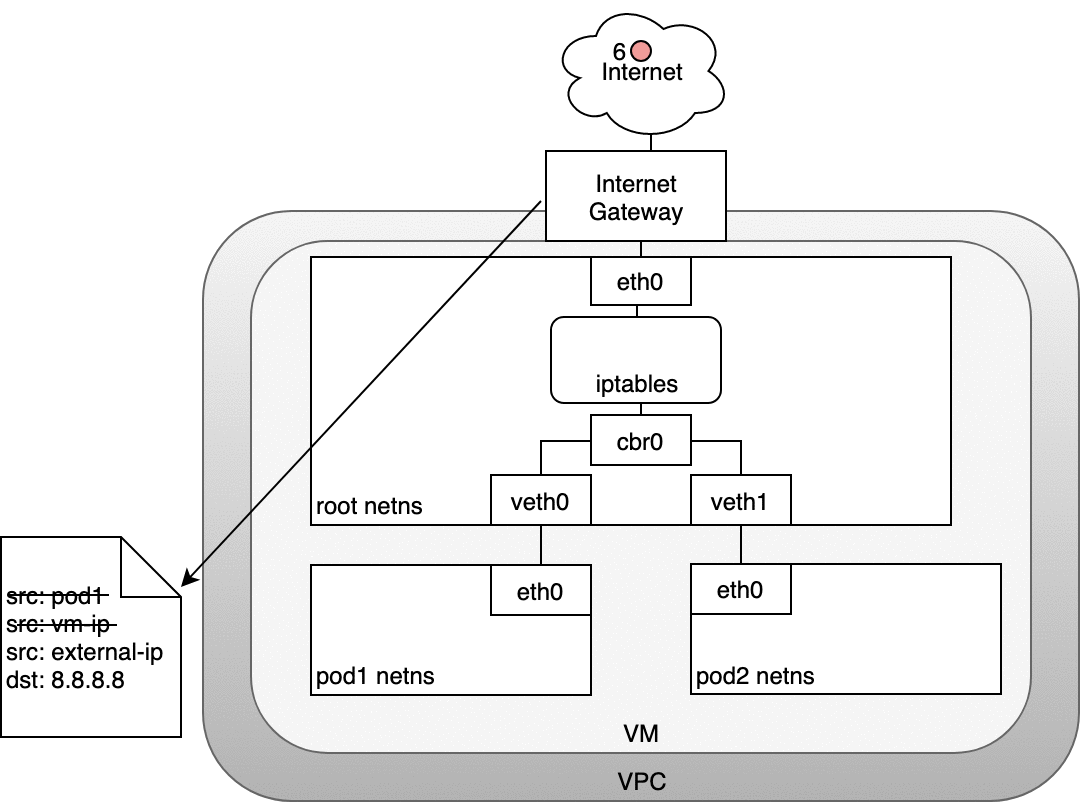
6.2 Ingress — Routing Internet traffic to Kubernetes
Ingress — getting traffic into your cluster — is a surprisingly tricky problem to solve. Again, this is specific to the network you are running, but in general, Ingress is divided into two solutions that work on different parts of the network stack: (1) a Service LoadBalancer and (2) an Ingress controller.
6.2.1 Layer 4 Ingress: LoadBalancer
When you create a Kubernetes Service you can optionally specify a LoadBalancer to go with it. The implementation of the LoadBalancer is provided by a cloud controller that knows how to create a load balancer for your service. Once your Service is created, it will advertise the IP address for the load balancer. As an end user, you can start directing traffic to the load balancer to begin communicating with your Service.
With AWS, load balancers are aware of Nodes within their Target Group and will balance traffic throughout all of the Nodes in the cluster. Once traffic reaches a Node, the iptables rules previously installed throughout the cluster for your Service will ensure that traffic reaches the Pods for the Service you are interested in.
6.2.2 Life of a packet: LoadBalancer to Service
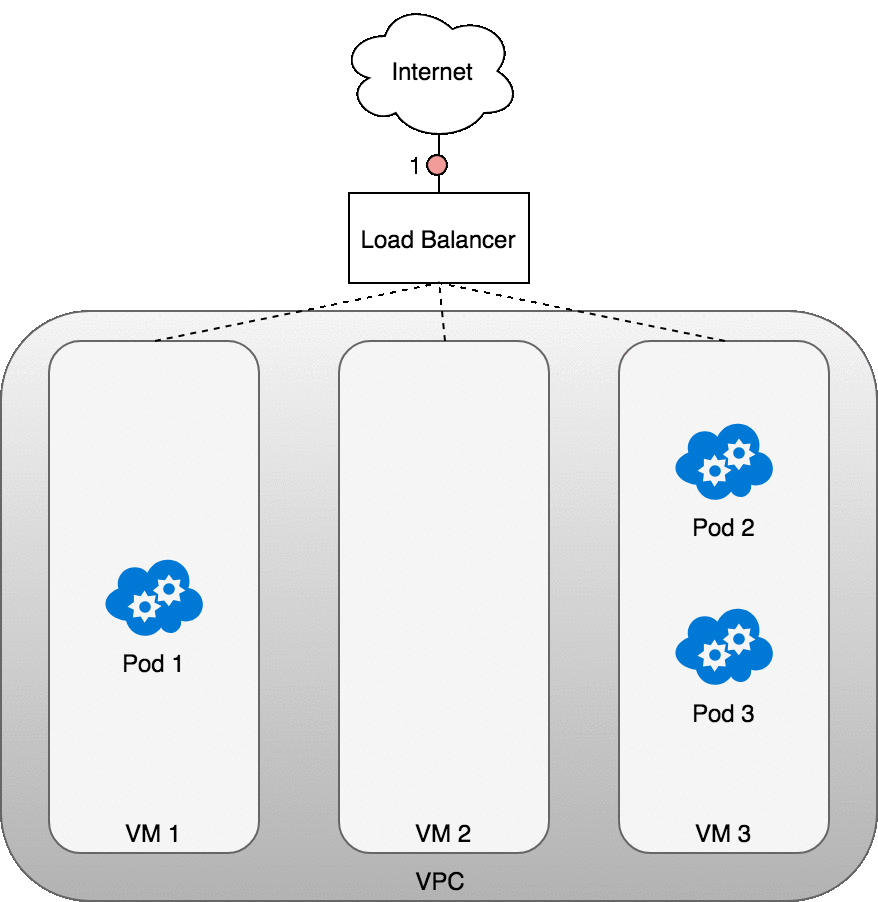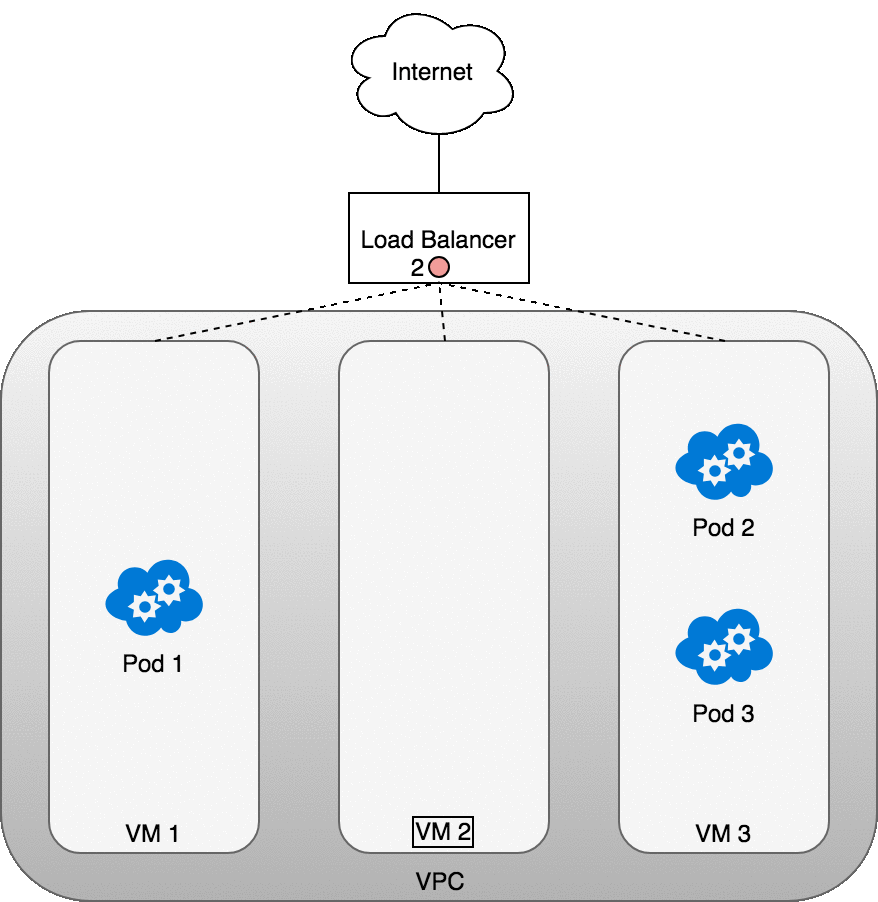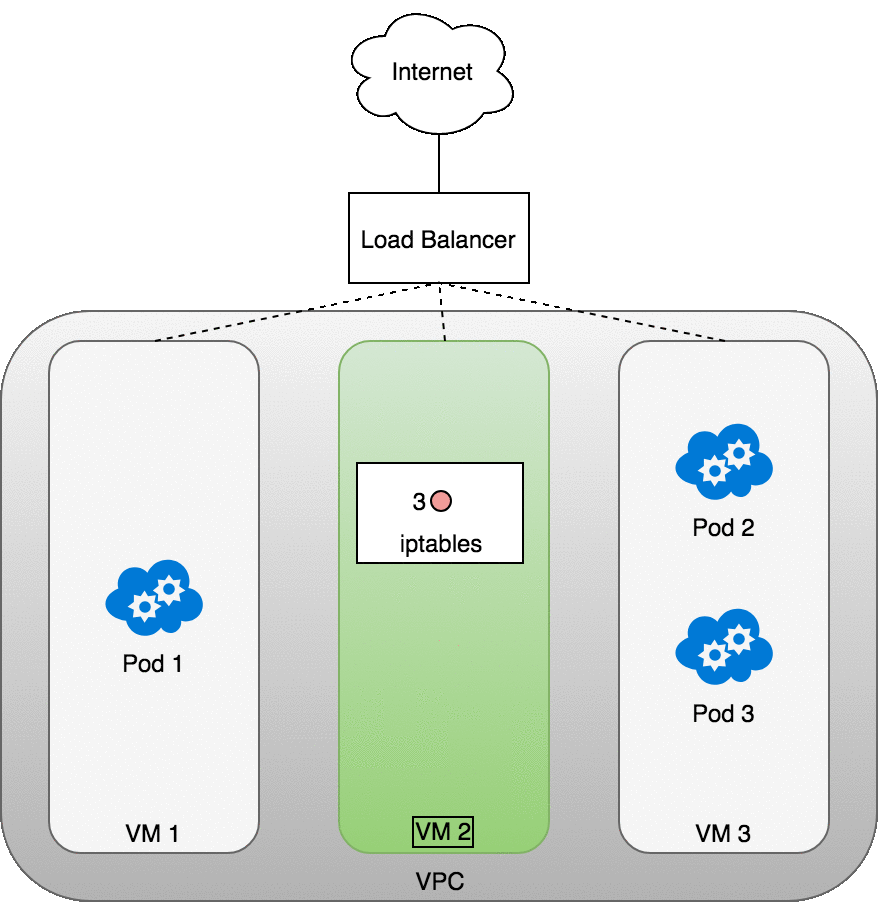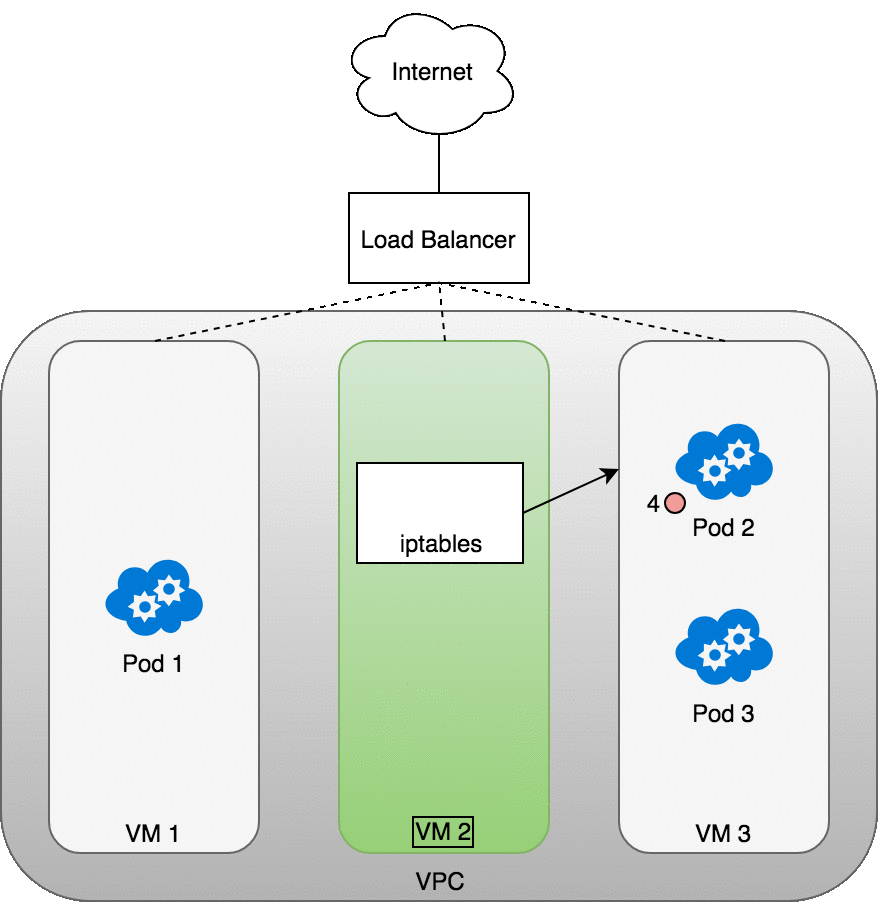
Let’s look at how this works in practice. Once you deploy your service,
a new load balancer will be created for you by the cloud provider you are
working with (1). Because the load balancer is not container aware, once
traffic reaches the load-balancer it is distributed throughout the VMs
that make up your cluster (2). iptables rules on each VM will direct
incoming traffic from the load balancer to the correct Pod (3) — these are
the same IP tables rules that were put in place during Service creation
and discussed earlier. The response from the Pod to the client will return
with the Pod’s IP, but the client needs to have the load balancer’s IP
address. iptables and conntrack is used to rewrite the IPs correctly on
the return path, as we saw earlier.
The following diagram shows a network load balancer in front of three VMs that host your Pods. Incoming traffic (1) is directed at the load balancer for your Service. Once the load balancer receives the packet (2) it picks a VM at random. In this case, we’ve chosen pathologically the VM with no Pod running: VM 2 (3). Here, the iptables rules running on the VM will direct the packet to the correct Pod using the internal load balancing rules installed into the cluster using kube-proxy. iptables does the correct NAT and forwards the packet on to the correct Pod (4).
6.2.3 Layer 7 Ingress: Ingress Controller
Layer 7 network Ingress operates on the HTTP/HTTPS protocol range of the
network stack and is built on top of Services. The first step to enabling
Ingress is to open a port on your Service using the NodePort Service
type in Kubernetes. If you set the Service’s type field to NodePort, the
Kubernetes master will allocate a port from a range you specify, and each
Node will proxy that port (the same port number on every Node) into your
Service. That is, any traffic directed to the Node’s port will be
forwarded on to the service using iptables rules. This Service to Pod
routing follows the same internal cluster load-balancing pattern we’ve
already discussed when routing traffic from Services to Pods.
To expose a Node’s port to the Internet you use an Ingress object. An Ingress is a higher-level HTTP load balancer that maps HTTP requests to Kubernetes Services. The Ingress method will be different depending on how it is implemented by the Kubernetes cloud provider controller. HTTP load balancers, like Layer 4 network load balancers, only understand Node IPs (not Pod IPs) so traffic routing similarly leverages the internal load-balancing provided by the iptables rules installed on each Node by kube-proxy.
Within an AWS environment, the ALB Ingress Controller provides Kubernetes Ingress using Amazon’s Layer 7 Application Load Balancer. The following diagram details the AWS components this controller creates. It also demonstrates the route Ingress traffic takes from the ALB to the Kubernetes cluster.
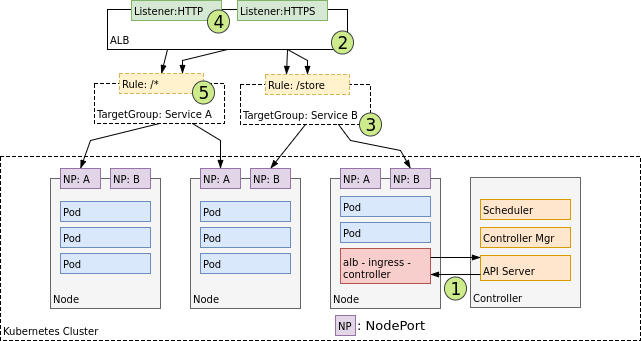
Upon creation, (1) an Ingress Controller watches for Ingress events from the Kubernetes API server. When it finds Ingress resources that satisfy its requirements, it begins the creation of AWS resources. AWS uses an Application Load Balancer (ALB) (2) for Ingress resources. Load balancers work in conjunction with Target Groups that are used to route requests to one or more registered Nodes. (3) Target Groups are created in AWS for each unique Kubernetes Service described by the Ingress resource. (4) A Listener is an ALB process that checks for connection requests using the protocol and port that you configure. Listeners are created by the Ingress controller for every port detailed in your Ingress resource annotations. Lastly, Target Group Rules are created for each path specified in your Ingress resource. This ensures traffic to a specific path is routed to the correct Kubernetes Service (5).
6.2.4 Life of a packet: Ingress to Service
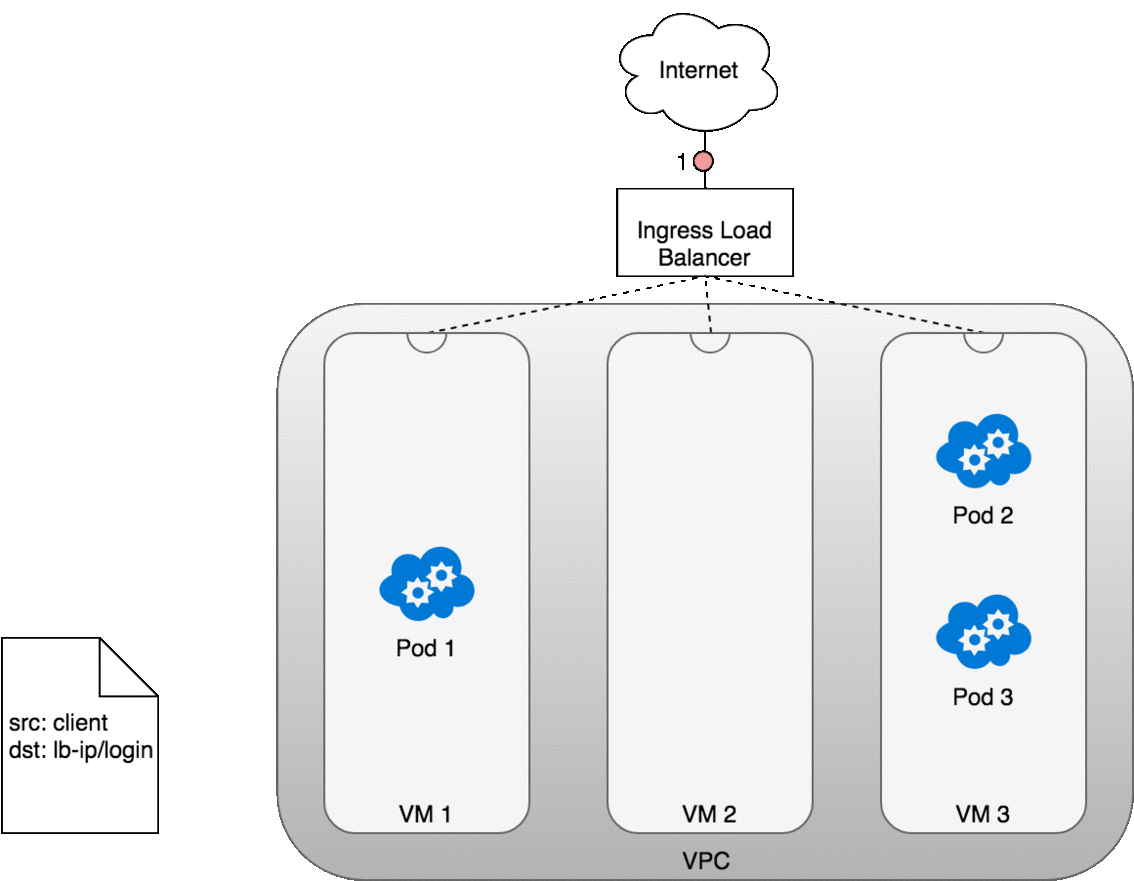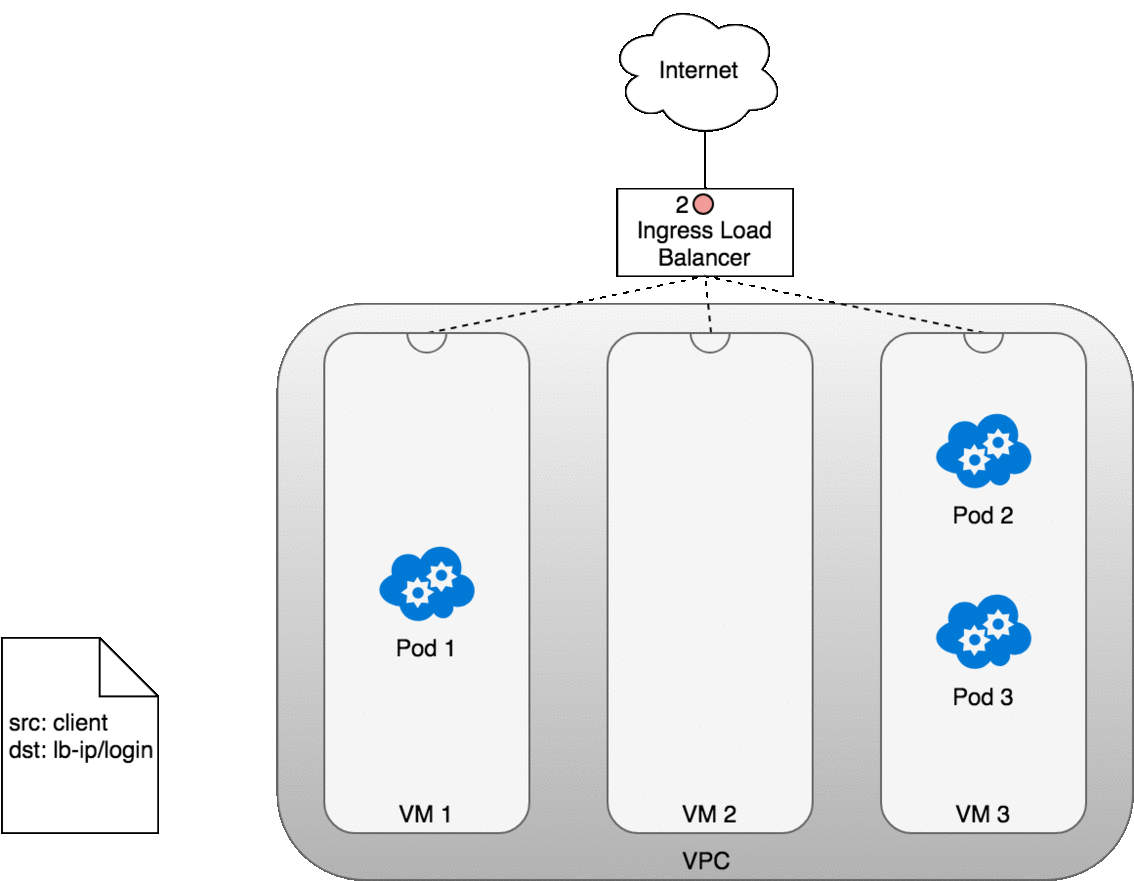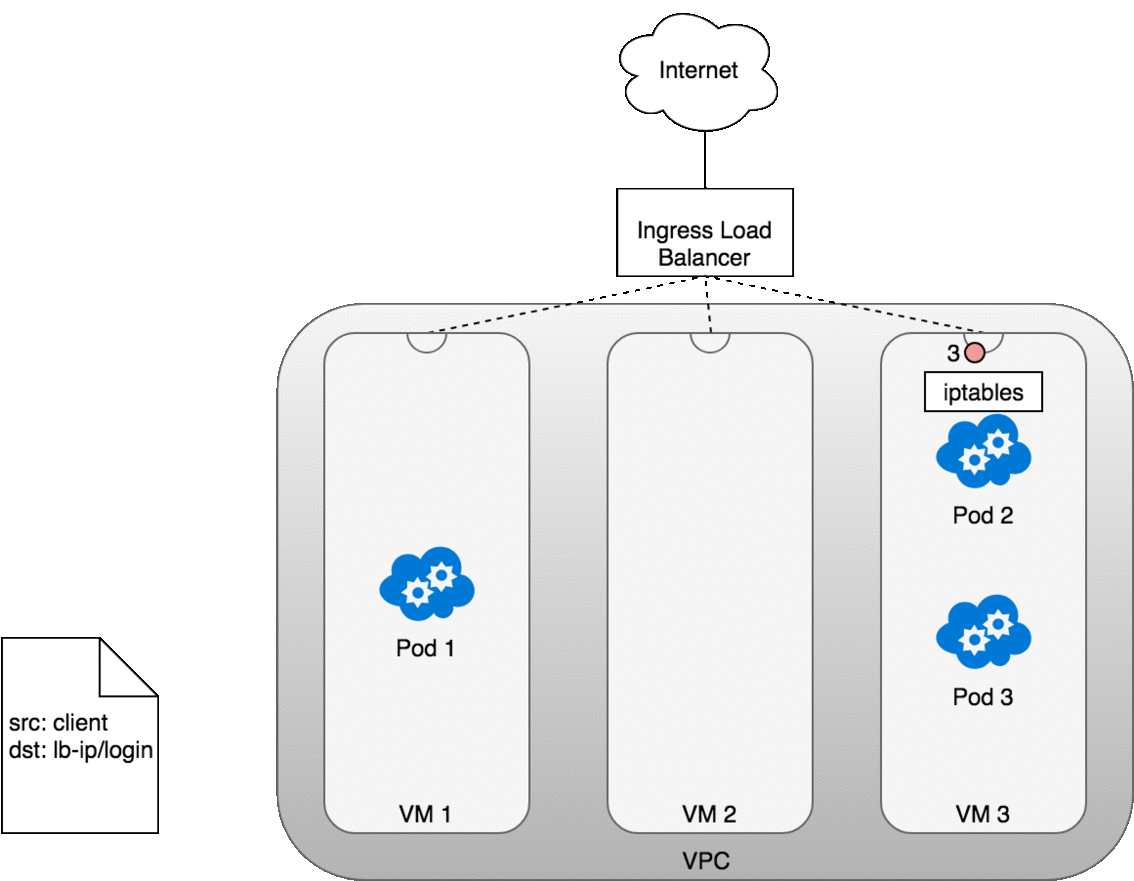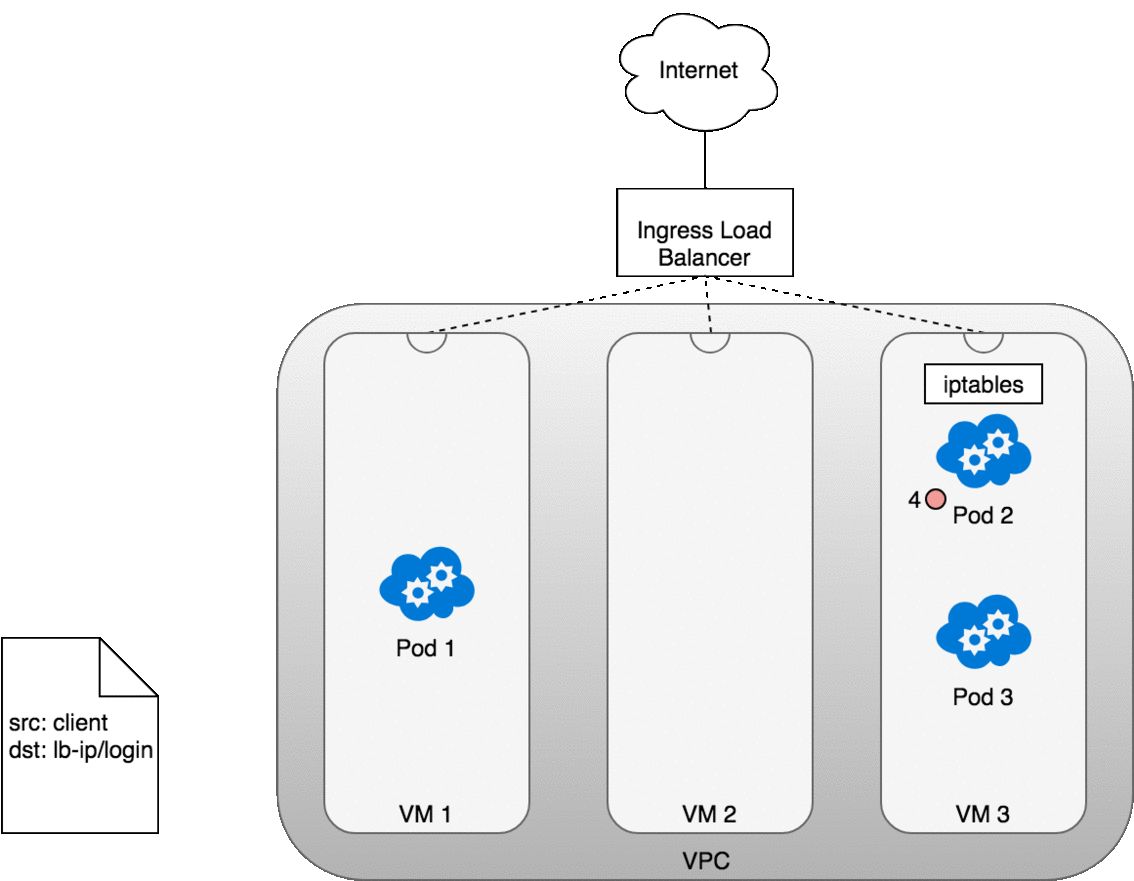
The life of a packet flowing through an Ingress is very similar to that of a LoadBalancer. The key differences are that an Ingress is aware of the URL’s path (allowing and can route traffic to services based on their path), and that the initial connection between the Ingress and the Node is through the port exposed on the Node for each service.
Let’s look at how this works in practice. Once you deploy your service,
a new Ingress load balancer will be created for you by the cloud provider
you are working with (1). Because the load balancer is not container
aware, once traffic reaches the load-balancer it is distributed throughout
the VMs that make up your cluster (2) through the advertised port for your
service. iptables rules on each VM will direct incoming traffic from the
load balancer to the correct Pod (3) — as we have seen before. The
response from the Pod to the client will return with the Pod’s IP, but the
client needs to have the load balancer’s IP address. iptables and
conntrack is used to rewrite the IPs correctly on the return path, as we
saw earlier.
One benefit of Layer 7 load-balancers are that they are HTTP aware, so
they know about URLs and paths. This allows you you to segment your
Service traffic by URL path. They also typically provide the original
client’s IP address in the X-Forwarded-For header of the HTTP request.
7 Wrapping Up
This guide provides a foundation for understanding the Kubernetes networking model and how it enables common networking tasks. The field of networking is both broad and deep and it’s impossible to cover everything here. This guide should give you a starting point to dive into the topics you are interested in and want to know more about. Whenever you are stumped, leverage the Kubernetes documentation and the Kubernetes community to help you find your way.
8 Glossary
Kubernetes relies on several existing technologies to build a functioning cluster. Fully exploring each of these technologies is beyond the scope of this guide, but this section describes each of those technologies in enough detail to follow along with the discussion. You can feel free to skim this section, skip it completely, or refer to it as needed if you ever get confused or need a refresher.
Layer 2 Networking
Layer 2 is the data link layer providing Node-to-Node data transfer. It defines the protocol to establish and terminate a connection between two physically connected devices. It also defines the protocol for flow control between them.
Layer 4 Networking
The transport layer controls the reliability of a given link through flow control. In TCP/IP, this layer refers to the TCP protocol for exchanging data over an unreliable network.
Layer 7 Networking
The application layer is the layer closest to the end user, which means both the application layer and the user interact directly with the software application. This layer interacts with software applications that implement a communicating component. Typically, Layer 7 Networking refers to HTTP.
NAT — Network Address Translation
NAT or network address translation is an IP-level remapping of one address space into another. The mapping happens by modifying network address information in the IP header of packets while they are in transit across a traffic routing device.
A basic NAT is a simple mapping from one IP address to another. More commonly, NAT is used to map multiple private IP address into one publicly exposed IP address. Typically, a local network uses a private IP address space and a router on that network is given a private address in that space. The router is then connected to the Internet with a public IP address. As traffic is passed from the local network to the Internet, the source address for each packet is translated from the private address to the public address, making it seem as though the request is coming directly from the router. The router maintains connection tracking to forward replies to the correct private IP on the local network.
NAT provides an additional benefit of allowing large private networks to connect to the Internet using a single public IP address, thereby conserving the number of publicly used IP addresses.
SNAT — Source Network Address Translation
SNAT simply refers to a NAT procedure that modifies the source address of an IP packet. This is the typical behaviour for the NAT described above.
DNAT — Destination Network Address Translation
DNAT refers to a NAT procedure that modifies the destination address of an IP packet. DNAT is used to publish a service resting in a private network to a publicly addressable IP address.
Network Namespace
In networking, each machine (real or virtual) has an Ethernet device (that
we will refer to as eth0). All traffic flowing in and out of the machine
is associated with that device. In truth, Linux associates each Ethernet
device with a network namespace — a logical copy of the entire network
stack, with its own routes, firewall rules, and network devices.
Initially, all the processes share the same default network namespace from
the init process, called the root namespace. By default, a process
inherits its network namespace from its parent and so, if you don’t make
any changes, all network traffic flows through the Ethernet device
specified for the root network namespace.
veth — Virtual Ethernet Device Pairs
Computer systems typically consist of one or more networking devices — eth0, eth1, etc — that are associated with a physical network adapter which is responsible for placing packets onto the physical wire. Veth devices are virtual network devices that are always created in interconnected pairs. They can act as tunnels between network namespaces to create a bridge to a physical network device in another namespace, but can also be used as standalone network devices. You can think of a veth device as a virtual patch cable between devices — what goes in one end will come out the other.
bridge — Network Bridge
A network bridge is a device that creates a single aggregate network from multiple communication networks or network segments. Bridging connects two separate networks as if they were a single network. Bridging uses an internal data structure to record the location that each packet is sent to as a performance optimization.
CIDR — Classless Inter-Domain Routing
CIDR is a method for allocating IP addresses and performing IP routing. With CIDR, IP addresses consist of two groups: the network prefix (which identifies the whole network or subnet), and the host identifier (which specifies a particular interface of a host on that network or subnet). CIDR represents IP addresses using CIDR notation, in which an address or routing prefix is written with a suffix indicating the number of bits of the prefix, such as 192.0.2.0/24 for IPv4. An IP address is part of a CIDR block, and is said to belong to the CIDR block if the initial n bits of the address and the CIDR prefix are the same.
CNI — Container Network Interface
CNI (Container Network Interface) is a Cloud Native Computing Foundation project consisting of a specification and libraries for writing plugins to configure network interfaces in Linux containers. CNI concerns itself only with network connectivity of containers and removing allocated resources when the container is deleted.
VIP — Virtual IP Address
A virtual IP address, or VIP, is a software-defined IP address that doesn’t correspond to an actual physical network interface.
netfilter — The Packet Filtering Framework for Linux
netfilter is the packet filtering framework in Linux. The software implementing this framework is responsible for packet filtering, network address translation (NAT), and other packet mangling.
netfilter, ip_tables, connection tracking (ip_conntrack, nf_conntrack) and the NAT subsystem together build the major parts of the framework.
iptables — Packet Mangling Tool
iptables is a program that allows a Linux system administrator to configure the netfilter and the chains and rules it stores. Each rule within an IP table consists of a number of classifiers (iptables matches) and one connected action (iptables target).
conntrack — Connection Tracking
conntrack is a tool built on top of the Netfilter framework to handle connection tracking. Connection tracking allows the kernel to keep track of all logical network connections or sessions, and direct packets for each connection or session to the correct sender or receiver. NAT relies on this information to translate all related packets in the same way, and iptables can use this information to act as a stateful firewall.
IPVS — IP Virtual Server
IPVS implements transport-layer load balancing as part of the Linux kernel.
IPVS is a tool similar to iptables. It is based on the Linux kernel’s netfilter hook function, but uses a hash table as the underlying data structure. That means, when compared to iptables, IPVS redirects traffic much faster, has much better performance when syncing proxy rules, and provides more load balancing algorithms.
DNS — The Domain Name System
The Domain Name System (DNS) is a decentralized naming system for associating system names with IP addresses. It translates domain names to numerical IP addresses for locating computer services.