At first glance, Amazon’s First-In-First-Out (FIFO) message queues provide an excellent feature set for business-critical scenarios. With FIFO, the order in which messages are sent and received is strictly preserved. With exactly-once processing, message duplicates are not introduced into the queue, and consumers control when a message is made available for redelivery. Reading past the marketing hype, how well do FIFO queues work in the real world?
This article takes a deep dive into SQS FIFO queues to test the claims of message ordering and exactly-once processing, paying particular care to the conditions under which these claims hold. I show how exactly-once processing can be achieved, and how that message ordering is preserved through failure conditions. I conclude with an examination of the relationship between in-order and exactly-once processing and atomic broadcast and consensus.
First-In-First-Out — Ordered Message Processing in the Real World
On the surface, the idea of messages being in order is a simple one: a message publisher sends a message to the messaging system, and message consumers read those messages back in the order they were published. If we have a single synchronous publisher, a single synchronous subscriber, and a single synchronous message delivery server — all running on a synchronous transport layer — the notion of order is simple: messages are ordered by when the publisher successfully publishes them, by some measure of time or sequence.
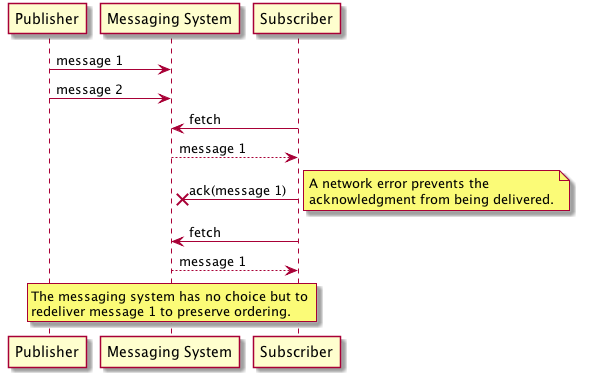
However, even in this simple case, guaranteed ordering of messages would put severe constraints on throughput. Why? At any point between the messaging system receiving a message and a subscriber consuming it, something may fail. The only way to truly guarantee the order of messages would be for the messaging system to deliver the messages one at a time to the subscriber, waiting to deliver the next message until the messaging system knows the subscriber has received and processed the current message via an acknowledgement. In the following figure, the messaging system delivers the first ordered message to the consumer. To preserve strict ordering, the system has no choice but to delay delivering any additional messages until the first ordered message has been successfully acknowledge as processed.
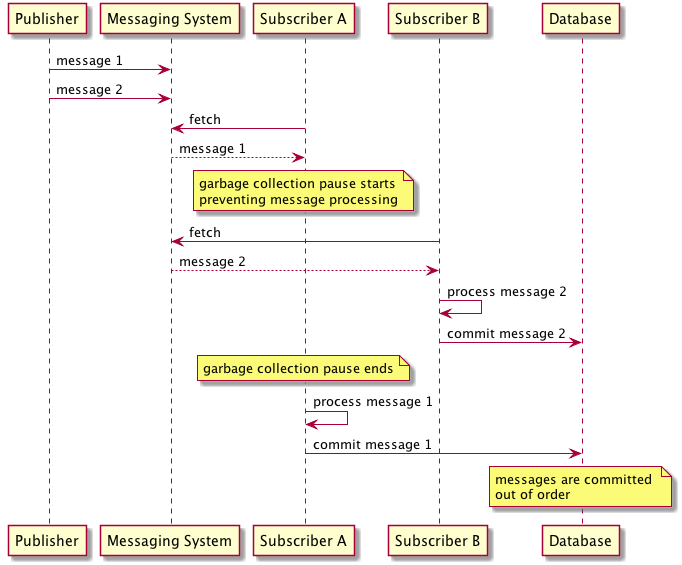
This simple scenario also highlights how the throughput of ordered message processing is restricted to one single-threaded receiver — the messaging system cannot deliver messages to concurrent consumers without violating ordering guarantees. In the following figure, two consumers try to read messages from a messaging system that does not wait for acknowledgement before delivering the next message. In this example, messages are delivered in order to two subscribers. However, the first subscriber encounters an unlucky garbage collection pause causing it to delay processing. The end result is that the two messages are processed and committed out of order.
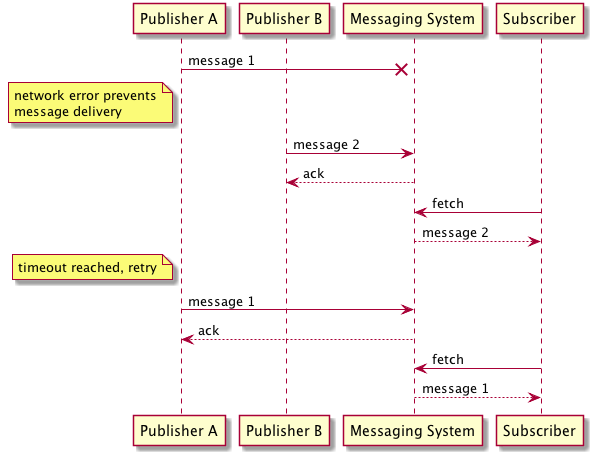
What about the case where we have multiple publishers? Either the publishers themselves have to coordinate to assign order to each message, or the messaging system has to attach a notion of order to every incoming message. In either case, any timestamp assigned to a message must be acquired from the same source to avoid clock drift, and any sequence number must be obtained from a single data source with ACID transactional guarantees. Both of these scenarios limit publish throughput to a single publisher at a time. The following figure highlights a race condition that can occur with multiple publishers that do not coordinate on message order.
Together, these restrictions on publisher and subscriber behaviour imply that FIFO is only really meaningful when you have one single-threaded publisher and one single-threaded receiver. On the publisher side, if there are a bunch of threads or processes writing into a queue, you can’t really assign a meaning of order: the messages show up in the queue depending on when the publishers get scheduled. On the subscriber side, if there are a bunch of threads or processes reading from a queue, messages need to be processed one-at-a-time to ensure correct ordering.
With Amazon’s FIFO implementation, ordering is applied on a per group basis, allowing you to control how restrictive the single-threaded publisher and consumer requirement is. In practice, this means you have three options for controlling ordering behaviour:
- Publish all the messages in the queue to same group so that they are all delivered in order. This is equivalent to not using a message group and limits throughput to a single publisher and single active subscriber across your queue.
- Use a set of message groups for your application. For example, if you are tracking data from several different customers, use a message group per customer. The records for each customer will be delivered in order.
- Publish every message to a unique group. In this case, there will be no ordering at all.
It is important to remember that within each message group, you are still limited to a single-threaded publisher and single-threaded receiver due to the limitations described above. You will therefore need to design your application so that all publishes for each group are from a single-threaded publisher. If you use multiple publishers, they must coordinate publishes to avoid out-of-order messages.
In conclusion, SQS’s implementation of FIFO queues support ordering guarantees at limited throughput per message group. In practice, this means certain design restrictions for both message publishers and message consumers. When publishing, you have to design your application to only have one publisher per message group. If your application is designed to be horizontally scalable and fronted by a load-balancer, this may not be as simple as it sounds. As an example, if you design your application to group messages by a user identifier, you must ensure that all messages being published for that identifier are being published by the same application instance using some form of sticky-routing, or by coordinating publishes between instances using a transactional storage system. When subscribing to messages, the situation is simpler because SQS will only deliver messages to subscribers in order. In practice, this means you can have multiple subscribers consuming from a group but only one consumer will be actively consuming messages from a message group at a time while others remain idle.
Exactly-Once — Nothing in Life is Guaranteed
With FIFO queues, the meaning of “exactly-once” is that the queues work in conjunction with the publisher APIs to avoid introducing duplicate messages. Any duplicate messages published to a FIFO queue will be dropped by the messaging system and not delivered to consumers. In the following example, the publisher successfully sends a message to a FIFO queue, which persists the message for delivery to consumers. Unfortunately, the acknowledgement is lost and the publisher has no way of knowing that the message was successfully persisted. After the publisher hits a timeout while waiting for the acknowledgement, it retries sending. Since SQS has already seen this message, it drops it, preventing the introduction of duplicates into the queue.
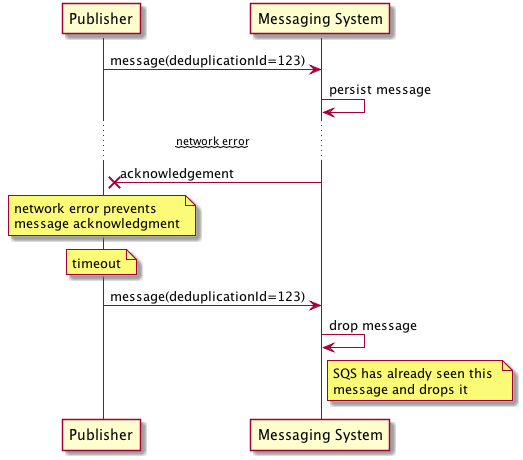
SQS implements message deduplication by remembering which deduplication id values it’s seen. To be precise, it remembers the values it has seen for the last five minutes, which means that if you send a pair of duplicate messages more than five minutes apart, both might get through, resulting in duplicates.
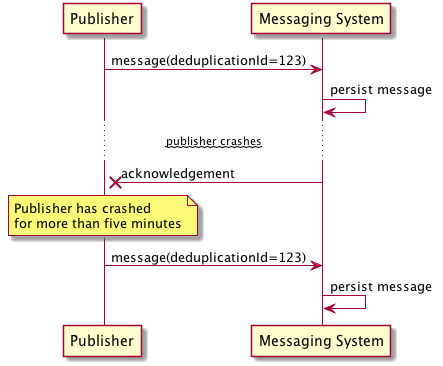
In an ideal scenario, the five minute window would be a complete non-issue. Unfortunately, if you are relying on SQS’s exactly-once guarantee for critical use cases you will need to account for the possibility of this error and design your application accordingly.
On the message consumer side, FIFO queues do not guarantee exactly once delivery, because in simple fact, exactly once delivery at the transport level is provably impossible. Even if you could ensure exactly-once delivery at the transport level, it probably isn’t what you want anyways — if a subscriber receives a message from the transport, there is still a chance that it can crash before processing it, in which case you definitely want the messaging system to deliver the message again.
Instead, FIFO queues offer exactly-once processing by guaranteeing that once a message has successfully been acknowledged as processed that it won’t be delivered again. To understand more completely how this works, let’s walk through the details of how you go about consuming messages from SQS.
When a consumer receives and processes a message from a queue, the message remains in the queue — SQS doesn’t automatically delete the message. Because SQS has no knowledge of the consuming system, it has no guarantee that the consuming system has processed the message — the connection can break, the consumer can crash, or processing can fail. Instead, SQS requires that the consumer delete the message from the queue after receiving and processing it by issuing an explicit acknowledgement. To prevent other consumers from processing a message that has been delivered but not acknowledged, each message has a visibility timeout that specifies the period of time during which SQS prevents other consuming components from receiving and processing the message.
The following diagram from the AWS documentation describes the lifecycle of an SQS message, from creation to deletion.
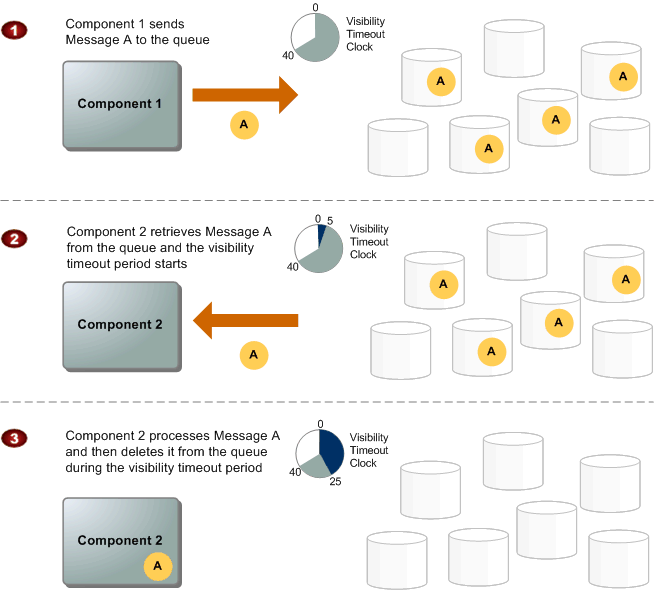
FIFO queues add an additional restriction to this diagram: during the visibility timeout period, consumers are blocked from reading messages from any message group that has unacknowledged messages in flight. If all the messages in a queue have the same group id, the whole message queue is blocked.
Now, suppose a subscriber receives a batch of messages and begins processing them, committing the result to a database. Unfortunately, halfway through processing the subscriber halts because of a garbage collection pause, failing to delete the messages it has processed before the visibility timeout expires. In that case, the messages would be made available to other consumers, which might end up reading and processing duplicates.
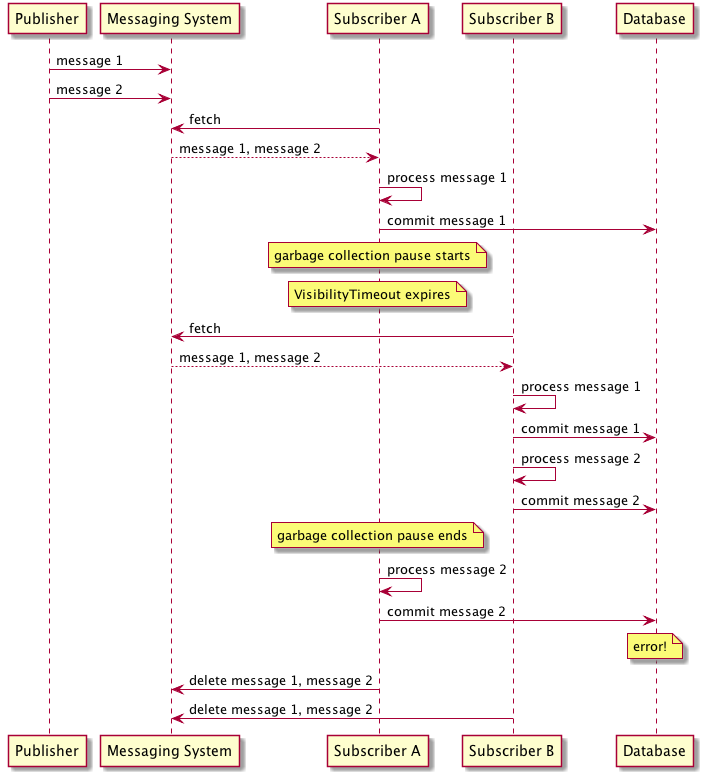
The problem is even worse than that: even with a single consumer, if you process a message and then fail to delete the message from SQS within the visibility timeout, the message will be delivered twice. One solution to guard against this would be for the consuming system to read messages from SQS into their own durable storage for future processing. After confirming that a copy of the message has been durably committed, the consumer can delete the message from SQS. This concept is similar to how many database systems use a write-ahead-log to durably store commits. This scenario is depicted in the figure that follows: after each message is committed to the database, it is deleted from the SQS queue, while in parallel a message processor running as a background thread handles processing the message.
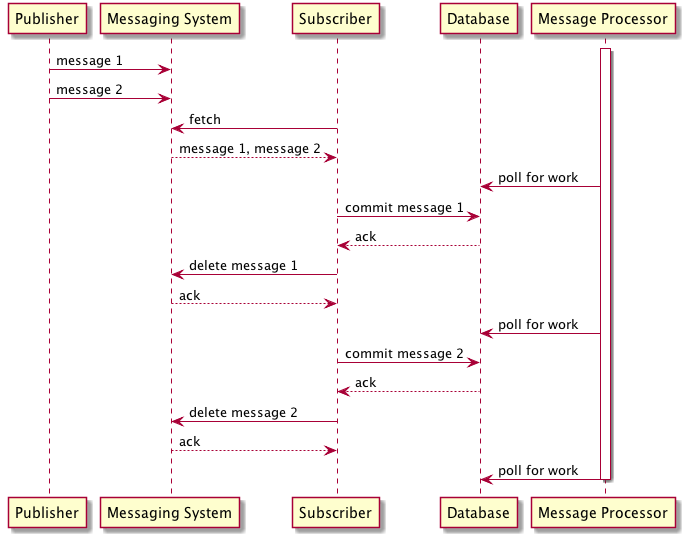
To summarize, FIFO SQS queues offer exactly once processing only if 1) publishers never publish duplicate messages wider than five minutes apart and 2) consumers never fail to delete messages they have processed from the queue. In practice, this means that consumers need to read messages from the queue one at a time, storing a copy of the message durably before deleting it from the queue. If your system cannot be designed to handle these two cases, you will not be able to use FIFO queues for exactly once processing.
Why is this so hard? FIFO and Total Order Broadcast
If you follow Amazon’s marketing of FIFO queues, they suggest that using FIFO queues provides exactly-once and in-order processing of messaging. But, as we have seen, this is only true under a limited set of conditions. For publishers, we saw that the only way to guarantee ordered message delivery is to restrict throughput to a single publisher per message group. For consumers, we saw that the only way to guarantee exactly-once and in order processing is to process messages one at a time by coordinating message processing through a transactional datastore. You also need to somehow guarantee that duplicate publishes never happen at wider than five minute intervals, or that consumers check existing processed data and drop duplicates during processing.
Naturally, introducing a single publisher and coordinated consumers will reduce message throughput. By using FIFO queues, you can guarantee in-order message processing at the expense of reduced throughput, but will still need to handle duplicate messages in the degenerate case.
These restrictions sound imposing — and they are — but they are also a requirement to implement in-order and exactly once messaging, not a limitation of Amazon’s FIFO implementation. If you pursue this topic further, you will see that FIFO message queues are closely related to the problem of Atomic Broadcast, also known as Total Order Broadcast. Total order broadcast is usually described as a protocol for exchanging messages between nodes. Informally, it requires that two safety properties always be satisfied:
- Reliable delivery — If a message is delivered to one node, it is delivered to all nodes; no messages are lost.
- Totally ordered delivery - Messages are delivered to every node in the same order.
FIFO is actually a slightly stronger guarantee than total order broadcast, since total order broadcast does not care about what order messages are delivered — any order will do, as long as it is the same everywhere. Once you consider FIFO messaging as a variation of total order broadcast, you will find a number of interesting results. Particularly, Chandra and Toueg have proven that total ordered broadcast is equivalent to consensus. Intuitively, you can achieve total ordered broadcast by executing multiple sequential rounds of a consensus algorithm — the result of each round of consensus is a single “message” in the ordered broadcast.
But what does this all have to do with FIFO queues? It means that if your application requires an in order and exactly-once message queue, it has been proven that your application requires multiple sequential rounds of consensus. This seems like an easy problem to solve, yet there are a whole host of issues that surface when the only communication channel between nodes is an asynchronous and unreliable network. The practical implication of this result is that any first-in-first-out and exactly-once message queue will have limited throughput. This result is a proof, not an implementation detail.
Saying No to FIFO
Given the inherent restrictions on in-order and exactly-once messaging described here, it is hard to recommend using FIFO queues outside of a few select use cases. My personal recommendation is that FIFO queues would be useful in situations where you have an existing legacy business process outside of your control that you need to integrate with. Such a system would periodically dump data into a FIFO queue for your system to process. In such a scenario, the limited throughput of FIFO queues would not be a factor, and any failures in the business process could potentially be retried.
On the other hand, if you are building two applications that need in-order and exactly-once messaging to function, what you probably want is just to use the same database or commit log. In the rush to design microservice architectures what is often overlooked is the inherent difficulty in coordinating distributed systems. When in-order and exactly-once messaging looks like a good solution to your problem, consider using the same datastore as an alternative that is usually simpler, more performant, and less error prone.