Workiva’s original product — supporting the mundane task of filing documents with the SEC — was so innovative that within its first 5 years it was being used by more than 65 percent of the Fortune 500 and generating more than $100 million in annual revenue. During that explosion in growth, the software development team focused solely on supporting and expanding the existing software stack. However, after several years of growth and expansion maintaining and extending that single code base became unsustainable.
Action needed to be taken to support the stability of the product, and engineering management made the difficult decision to break up the existing code base and develop all new features as services. Workiva, from this point forward, would adopt a service-oriented (microservice) architecture. At roughly the same point in time, I joined Workiva and started working on the Messaging Platform, with the mandate of providing the common platform for communication between Workiva’s fledgling set of services.
Fast forward a few years, and Workiva has a (mostly) stable Messaging Platform supporting tens of millions of messages per day. I want to take a few minutes now to reflect on the decisions that we made building a Messaging Platform to support a microservice architecture. I will talk about what we built, why we built it, the lessons we learned, the mistakes that were made, and the things I would change if we could do it all over again.
Interfaces and Protocols — Consistent Messaging for Microservices
A Messaging Platform is only useful as a building block for application developers. If internal developers can’t build an app using messaging, we might as well not exist. To be useful, we needed a solution that goes beyond simply moving bytes between components, we needed something that supports the full set of needs for developing a service: a consistent type system that works across languages, a way to consistently describe service interfaces, working transport mechanisms that move bytes between systems, standardized protocols for serializing and deserializing data, and separation of business logic and message processing from everything else.
Combining all of these requirements lead us to leverage Apache Thrift as a starting point for building out our offering. Thrift is a software library and compiler originally developed at Facebook for defining RPC service interfaces.
Thrift allows developers to define datatypes and service interfaces in a single language-neutral file and generate all the necessary code to build RPC clients and servers.
– Thrift: Scalable Cross-Language Services Implementation
To build a service with Thrift, server developers write their API using Thrift’s interface definition language, or IDL. The IDL describes the available API calls that this server exposes, along with any data types the service expects. The IDL is compiled using the Thrift compiler to generate server and client stubs implementing the interface defined in the IDL.
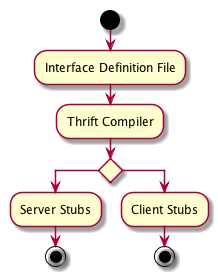
Given the compiled stub code, we can make RPC calls between clients and servers by specifying the protocol and transport to use during a call, and hooking in any of our custom business logic required to publish messages as a client, or to process messages as a server.
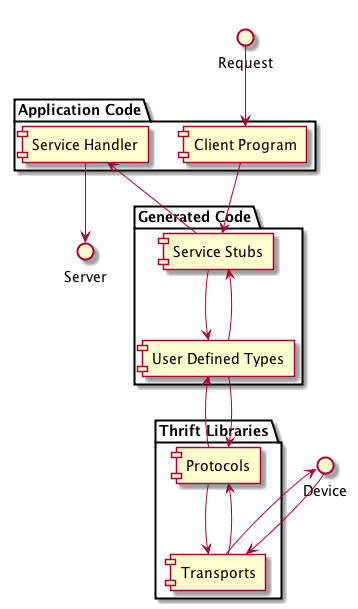
In the preceding figure, a request is started by the client program, which is written by the client application developer to implement the client stub generated by the Thrift compiler. The client program creates and uses any data types defined by the service interface. The request is then serialized using a Thrift protocol, and sent to an underlying device using a Thrift transport.
As a server, the process is reversed. The Thrift transport layer reads the bytes of the message off the underlying device, deserializes those bytes using the configured Thrift protocol, and uses the generated code to pass the deserialized message, with the correct data types, to the server for processing.
Thrift is composed of several distinct layers that work together to provide a full software stack for making RPC calls. We’ve found this separation of concerns to be the largest benefit of adopting Thrift as the basis for Workiva’s Messaging Platform. Specifically, the Thrift type system and protocols provide a language neutral set of types that work across programming languages, and we as the Messaging Platform are free to evolve the set of available Thrift transports to support different messaging scenarios without having each team make changes to their application or services.
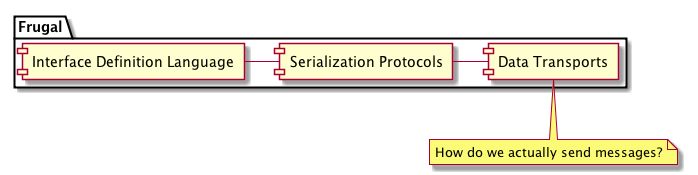
Unfortunately, Thrift doesn’t get everything right. Particularly, Thrift has some performance issues due to using head-of-line blocking — where a single, slow request will block any following requests — and Thrift has limited concurrency support. Even more important for our purposes as a Messaging Platform, Thrift does not support asynchronous (publish/subscribe) messaging patterns. With this limitation in mind, we leveraged the ideas of Thrift to build Frugal, which extends the core ideas of Thrift to support asynchronous messaging, with the added benefit of being able to address some of Thrift’s performance concerns along the way.
Frugal is an extension of Thrift and uses the Thrift library to provide access to existing cross-language data serialization. Frugal extends Thrift by adding support for request headers, request multiplexing, thread safety, and code-generated publish/subscribe APIs to support asynchronous messaging. Frugal is intended to act as a superset of Thrift, meaning it implements the same functionality as Thrift with some additional features.
With Frugal, we developed a consistent, cross-language messaging framework that could support both RPC and asynchronous messaging. With this in place, we began tackling the next problem in developing a Messaging Platform. Given a consistent client-server framework for generating and responding to messages, how do we send them?
Asynchronous Messaging — Connecting Distributed Systems
When developing a single application from a single codebase, integration is easy — simply make a procedure call. However, once you start to outgrow that single codebase and adopt a service architecture, integration can become a complex problem involving many interacting components.
For example, imagine a simple system divided between two services: a billing service and a shipping service. These two services need to be integrated so that an update to a user’s name in the shipping service triggers a corresponding update in the billing service. The shipping service could update the billing service’s data directly by modifying a shared database, but this approach requires the shipping service to know far too much about the internal processes of the billing service. Instead, the billing service can encapsulate the update operation behind an interface in the form of a remote procedure call, or RPC.
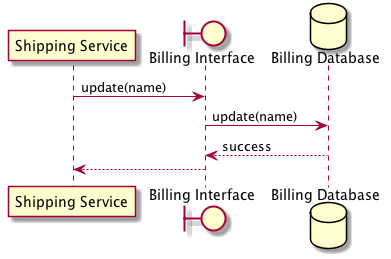
The RPC applies the software development principle of encapsulation to the integration of entire systems. If one system needs to modify or retrieve some data that is owned by another, it asks that system directly through its interface, allowing each system to maintain the integrity of the data it owns.
Remote procedure calls map nicely with how programmers already work because the programming interface of a remote procedure call is the same as that of local procedure call — if you need to do something, call this method or function. Unfortunately, this is more of a disadvantage than an advantage in distributed systems; there are big performance and reliability differences between making a remote procedure call over a network and making an in-memory procedure call to a library.
The complexity of the remote procedure call may be hidden from the programmer by the RPC interface, but it is there nonetheless. Building your system using such an RPC interface can lead programmers to make false assumptions about the underlying system. In the worst case this leads to designing brittle systems with little to no error-handling for network errors or latency issues.
In distributed environments these types of “hidden” costs are non-negotiable and cannot be ignored. In contrast, asynchronous messaging is fundamentally a solution to the problems of using remote procedure calls to develop distributed systems. By using asynchronous messaging, we can transfer packets of data frequently, and asynchronously, to integrate disparate applications in a loosely coupled way.
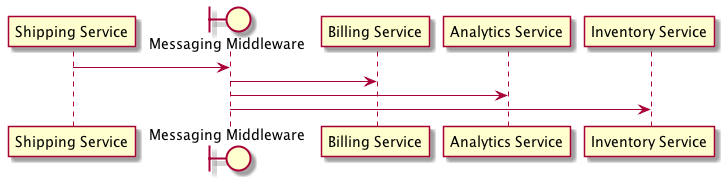
The asynchronous nature of messaging forces developers to form a clearer mental model of distributed systems, which encourages design of components with high cohesion and low coupling. Low coupling allows messages to be transformed in transit, broadcast to multiple receivers, or routed to particular destinations, without the sender or receiver knowing.
The knowledge gap between sender and receiver is an advantage in loosely coupled systems — one of the most difficult aspects of integrating applications is handling communication and coordination between humans, and by removing the “need to know” from the process, messaging works with human nature, rather than against it. This allows each application to keep their own conceptual model of the data being published and consumed, without coordinating with other services.
When developing Workiva’s Messaging Platform, we took the lessons of distributed systems design to heart and adopted a “messaging first” attitude with the assumption that asynchronous messaging was the best way to build systems. Working within this assumption, we set out choosing a messaging solution from among the many possible choices. After much consideration we settled on NATS as a simple, high-performance messaging system. We then set out to write the Frugal transport to connect clients and servers through NATS.
We thought our solution was pretty good. Frugal would ensure a standardized set of interfaces and protocols, and NATS would provide high performance request-reply and publish-subscribe messaging.
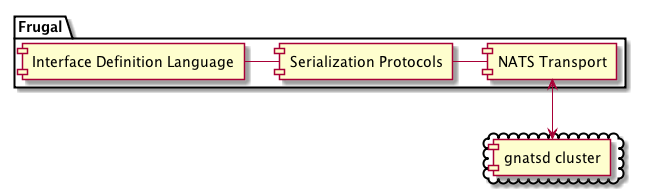
After releasing Frugal and the NATS infrastructure to support high performance messaging, we spent some time responding to support requests, fixing bugs, and, generally speaking, maintaining the system. Throughout this time, we kept hearing two requests from users:
- How can I send a message to a particular backend instance?
- How can I send large messages?
These two requests seemed reasonable, but each of them where difficult to implement using our existing platform.
Consistent Message Routing - Maintaining State Across Message Calls
The first request we received was to consistently route messages from a user to a single backend instance. In this case, the backend service was caching data from a user session and the performance impact of routing a user’s message to a different backend instance with each request was high enough to warrant discussing a consistent routing strategy that works over NATS.
With NATS, messages are routed to all interested consumers (one-to-many), or to a set of competing consumers (one-to-one) that listen to a topic. In this scenario, for a server to consistently receive messages from a single user session both the client and the server would need to agree on the message topic used to send messages to. In theory this works fine, in practice this didn’t work very well.
At Workiva, we operate services using a container-based auto scaling environment where we don’t necessarily know how many backend instances will be available to service requests at any point in time. This makes it difficult for clients and servers to agree on a consistent message topic. Consistent client-side hashing can help with this, but still presents some difficulty in configuring the correct topics as new backend services come online.
Handling Large Payloads
The second request we received was to handle large payloads through the Messaging Platform. NATS, like all messaging middleware, restricts the size of the message payload so that it can offer realistic guarantees on performance and scalability. We assumed that teams using the Messaging Platform would also take such limits into consideration and not rely on large payload support through messaging. Unfortunately, this become enough of a problem for teams using messaging that we needed to come up with an alternative.
Large payload support can be handled in two ways. First, you could use a message sequence to divide a large message into a series of smaller messages. In our environment this is difficult to achieve without first having a consistent routing mechanism to ensure that the same backend process receives all messages in a sequence. Second, you could use a claim check to store large messages in persistent storage and transmit only the message’s location over the wire. This solution works well, but adds a large amount of additional latency to requests. This is especially problematic for use cases where the majority of traffic is less than the messaging payload limit and only a few outliers are greater — the latency encountered for those outliers makes the messaging system unsuitable for real-time requests.
As much as we didn’t want to admit it, looking at these two problems forced us to re-evaluate our initial assumptions about the service we were offering. Although we still believed asynchronous messaging was the best way to design a distributed system, there were certain use cases that asynchronous messaging didn’t serve well.
Back to Basics — HTTP RPC
Simple HTTP requests easily support large payloads, and through cookies and load-balancing they support static routing too. It seemed like we could easily solve both our users’ problems by exposing HTTP as a transport option for Frugal serialized messages. So we did just that by adding HTTP as a Frugal transport option as part of the Messaging Platform.
With HTTP, we could leverage the existing infrastructure supporting the web to solve both our problems: most load balancers support some form of session persistence through IP address affinity or session cookies, and HTTP has no explicit payload limit. By supporting HTTP as a transport option, teams were able to choose the routing strategy and payload limit that made sense for their service. The downside to HTTP is that it does not easily support one-to-many messaging and cannot be used for publish-subscribe use cases.
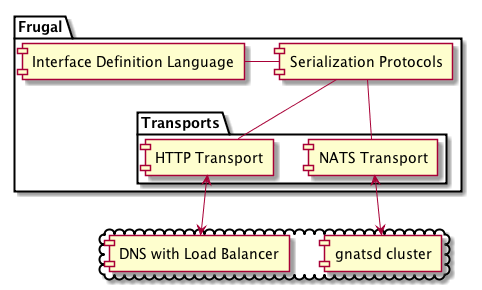
After releasing the HTTP transport, we found client teams quickly adopting it, which resulted in many variations of the question “why use NATS if HTTP works for me?”. We tried to answer this question by encouraging teams to use asynchronous messaging to avoid coupling services, to handle scale-out, and, generally speaking, to encourage robust distributed system design. But we found time and time again that what teams really wanted was RPC. It is familiar, easy to use, and they don’t have to deal with that pesky payload limit. Eventually, we adopted the stance that teams should use HTTP whenever they want to do RPC calls, and use NATS for asynchronous messaging. This recommendation provided a clear distinction between the two transport options, and allowed us to leverage the strengths of both HTTP and NATS, rather than trying to hide their weaknesses.
What’s in a Guarantee — Supporting CQRS with Guaranteed Messaging
We had deployed NATS as our messaging middleware and followed that up with HTTP support for large payloads and session affinity. We felt that with these two options teams had great support for building connected components. And they did. Teams that worked with the platform were happy with the solution we had and we continued to support their work with refinements to Frugal and the supporting development SDKs.
As the solutions built on top of messaging matured, we started to work with teams on new use cases. One of those use cases was broadcasting a log of changes to user data for synchronization of data between two services. The fundamental idea is that every change of user state would be captured as an event object. These objects can then be stored and applied to other systems to replay the sequence of events that generated the current user data. Essentially, we were looking at supporting a CQRS or Event Sourcing model for connecting services.
With Event Sourcing, we ensure that all changes to application state are stored as a sequence of events. These events can be queried through, used to reconstruct past states, or used as a convenient audit log. CQRS is a related pattern that separates the writing of data from the reading of data. Both Event Sourcing and CQRS allow you to separate how data is viewed from how data is updated, which allows you to scalably update data across multiple systems while supporting multiple independent presentation layers.
From a messaging perspective, to support this pattern we needed to adjust our platform. In particular, both Event Sourcing and CQRS typically put requirements on the messaging infrastructure to support guaranteed message delivery. In contrast, when we initially chose NATS as the primary message transport we assumed that we didn’t need to offer guaranteed delivery as long as users could retry failed message publish attempts. This assumption still holds, but it makes building a CQRS or Event Sourcing system unnecessarily difficult because each team in the pipeline needs to handle guaranteed delivery separately — by supporting guaranteed messaging as part of the messaging platform, each team does not need to handle it in their own specialized way.
With NATS, if a consuming service goes down, the message is dropped and will be lost. NATS Streaming (now called JetStream) builds upon NATS to support message persistence and at-least-once message delivery. Unfortunately, when evaluating NATS Streaming we found that it could not support our needs because it is not highly-available — if a message broker goes down all messages flowing through that message topic do not get delivered until the broker is restored.
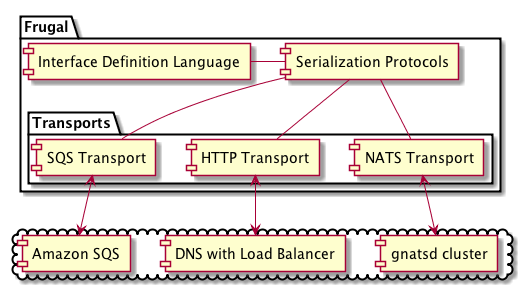
After evaluating a few other options, we eventually settled on using SQS to guarantee message delivery, with a supporting web service handling topic subscriptions. This system stores a recipient list of subscribers interested in a particular message topic in Amazon’s RDS, with a matching SQS queue for each interested subscriber. When a message is published, the message’s topic is matched against the list of interested subscribers and the messaging system delivers a copy of the message to SQS, allowing SQS to handle redundant storage and high availability of each message for each subscriber.
We recently finished the initial work of adding guaranteed messaging support to our platform, leaving us with three different transport options offering different qualities of service for different use cases.
NATS
- Low-latency publish-subscribe messaging.
- RPC between two components (using a return address).
- Not guaranteed.
HTTP
- RPC between two components.
- One-to-one communication.
- Supports large payloads.
- Supports sticky sessions.
SQS
- Guaranteed publish-subscribe messaging.
- (optional) First-in-first-out ordered messaging.
- Higher-latency.
The early decision to leverage Thrift (and develop Frugal) paid off by allowing teams to use the same service interface, serialization format, and code generation facilities to support any of the three transport options. The three transport options allow teams to build their service using the type of messaging transport that makes the most sense for their needs.
Post-Mortem
Start simple
Although I strongly believe that asynchronous messaging is the best way to connect services, that belief is not always shared, and I’m willing to concede that sometimes a simple RPC call is a better choice. So, despite the advantages of NATS, if I were to do this over again I would start with a simple HTTP transport to support connecting services. HTTP supports so many use cases and you can leverage the existing suite of infrastructure deployed throughout the web that supports HTTP: service discovery (through DNS resolution), sticky-sessions (through load-balancer cookies), and support for large payloads. After letting teams work with HTTP for a while, and learning about the benefits of using RPC to connect systems, we could have then introduced an asynchronous messaging system.
Given the requirements we know about now, I think we could have gone from HTTP directly to Amazon’s SQS paired with SNS for broadcasting messages to multiple subscribers. Instead, by evolving the Messaging Platform organically we are in a difficult situation of supporting three different transports for three different, but related, use cases.
“Messaging” is not one-size-fits all
When we first started out, we made the assumption that teams could use asynchronous messaging over NATS to do pretty much anything they wanted. Now that the dust has settled, we are left with the unenviable position of having to support three different transport options and having to explain to new users which transport to use for different use cases. I’m generally okay with this decision because it affords teams the most flexibility for building exactly the service for their needs.
If you take a minute to look at Amazon’s product offerings in the messaging space you can choose between SQS, SNS, Kinesis, and IoT message broker for integrating your applications. Although on the surface the products are similar, in reality their optimum use cases are different enough that it makes sense to have separate products to address each of those needs.
Unfortunately, one largely unsolved problem with running multiple transports is that it can be difficult to get the different messaging platforms to communicate with each other. We solved a portion of this problem when developing Frugal — at least all components have a common interface and common serialization format.
Optimize for change
The one constant throughout this project was change. At each stage — no matter how much time we took to evaluate our current platform against requests from our users — we inevitably would come across new requirements and new reasons for change. This is nothing new — agile methodologies have been espousing similar ideas for years. But agile, like messaging, is also not one-size-fits-all. It’s important to consider which parts of agile work for your team and for your organization. Use those what works and leave the rest.
Write things down
As a company, Workiva likes to move carefully and fully consider all options before pursuing a single path. Although this sounds “unagile”, consider our use cases: financial reporting, risk management, compliance. In each of these areas, our customers depend on the software’s correctness — any mistakes are significant mistakes, and we need to move carefully. One approach I take to balance the need to move carefully with the ability to change quickly is to write things down.
For any major (and sometimes minor) decisions, I write a Request for Discussion or RFD. The goal of writing things down is to clarify your own thoughts and expectations, and to identify gaps in your own thinking. If something is difficult to write down, it probably means you don’t understand it well enough and you need to take some time to prototype your ideas and research prior art before committing to a solution. Writing things down helps you make better decisions. A second benefit of writing things down is that team members and stakeholders can refer to decisions that have already been made. If you document major decisions and the reasons for them, you will save yourself a lot of time in the future by having some reference documentation already available.
Once a decision has been made, you still need to implement that decision as flexibly as possible to allow for change. This boils down to software engineering: design towards interfaces, favour composition over inheritance, leverage functional programming where possible, and generally write as little code as possible. By fostering strong software engineering principles your team will naturally develop flexible software that is able to change throughout its lifecycle.
Complexity is everywhere
Every solution starts out simple and gains complexity based on real-world usage. One frequently occurring example I see is comparing performance between a new system replacing an old system. The new solution for the existing problem is always more performant during initial benchmarks — not because it is better designed or implemented, but because it can ignore production battle scars, tech debt, and avoid feature creep. As the new solution adds the necessary features to reach parity with the old system (like TLS support, audit-level logging, or multi-tenancy) performance quickly degrades until it is no longer a selling point of the new solution.
In developing our platform, we started with a simple and elegant solution: Thrift over NATS. Then, we extended Thrift to support asynchronous messaging when we developed Frugal. After that, we developed our own compiler based on Thrift to more closely match our needs. Then, when NATS encountered real-world usage, we adapted the number of transports to add HTTP and SQS-based messaging. Each of these steps pushed us closer to the goal of supporting connecting disparate applications, but each of these steps also increased the complexity of the platform.
Someone has to be a product owner
Our team is composed of a set of high-functioning engineers building only internal facing products. One difficulty with this environment is that no one is officially in charge of communicating with stakeholders. Instead, one person (sometimes more than one) is generally in contact with stakeholders in an ad-hoc fashion throughout the work week. The end result is that multiple team members are collecting requirements and feedback from multiple people.
To avoid this, someone should be identified as a product owner and act as the more public “face” of the team, even for technical projects. This person has a few responsibilities: being the first point of contact with stakeholders, distilling and communicating feature requests, and helping prioritize technical work. Oftentimes, a team lead takes on this responsibility, but I would argue that the technical capability required to lead a technical team is not the same skill-set as the communication skill required to talk to stakeholders on behalf of the team. If you don’t explicitly identify this role, someone will end up filling it and it may not be the best person for the job.
I’ve been lucky enough to work with some great people during this time developing the Messaging Platform, but none of their input went in to this article. Views expressed are my own and do not represent Workiva or any Messaging Platform colleagues.