Before the Internet became a global network connecting millions of devices, it was a simple research experiment connecting a handful of institutions. In the beginning, the number of unique internet addresses could be measured in the tens. As the network expanded that number quickly grew into the hundreds and thousands and it became difficult to remember and type in IP addresses for each of these hosts.
To manage the growing number of network hosts, a simple text file, called
HOSTS.txt recorded each host and their IP address. To add your name to the
hosts file, you needed to send an e-mail describing the changes you wanted to
apply. The authority for the HOSTS.txt file would apply these changes once or
twice a week and anyone who wanted to grab the updated list would periodically
FTP to the canonical source, grab the latest file, and update their own list of
hosts. Naturally, as this small network expanded into, and was eventually
replaced by, the Internet, this solution became untenable – there were just too
many hosts to keep track of, keep consistent, and to serve from a single
canonical file using FTP and manual updates. HOSTS.txt did not scale.
The Domain Name System (DNS) was developed to scale the HOSTS.txt model to the
global Internet. The goals for the system were to allow for local administration
of portions of the data set while also making changes and updates to local data
available to the global Internet. The result is a globally distributed
hierarchical database that maps domain names to Internet hosts throughout the
world.
The Domain Namespace
The DNS distributed database is an inverted tree indexed by domain names. Taken together, the entire tree is called the domain namespace and represents the entire set of Internet domain names. Like a file system, the tree begins at a root node, inner nodes in the tree help organize hosts into domains, and leaf nodes provide information on a single host. Each node in the tree has a text label describing its portion of a fully qualified domain name. The full domain name for any node is the sequence of labels on the path from that node up to the root of the tree, with a dot separating the text labels along the path. The only restriction to node labels is that siblings in the tree have unique names to guarantee that a domain name uniquely identifies a single node in the tree.
An example will help illustrate the concept.
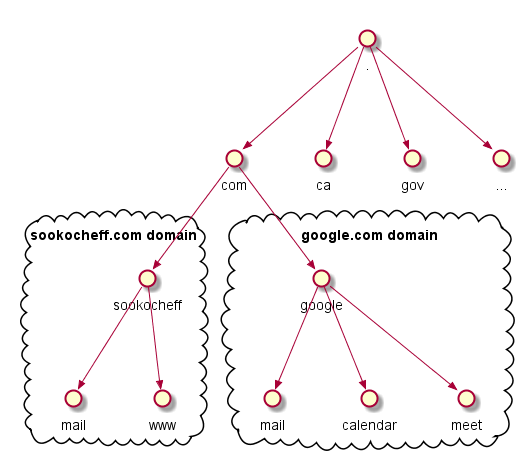
Remember that domain names are just indexes into the DNS database. For leaf
nodes, the data at the node represents an individual host on the network with
information like the network addresses, mail-routing information, or hardware
information. Nodes inside the tree can represent both a domain and a particular
host. In our example above, the sookocheff.com node represents both the sookocheff
domain and it represents the hosts that serve the sookocheff.com site you are
currently looking at.
Resource Records and Zone Files
The data indexed by a domain name is called a resource record. There are several types of records for different types of data. For example, there are unique resource records for mail routing and for or host address information. Each record type specifies is own syntax and semantic rules to follow.
The collection of resource records stored by a host are stored in zone files. Every domain that a host knows about is stored in a zone file, and it is these zone files that get distributed across the Internet to form the global distributed DNS database. A zone file is a simple text file that contains the mappings between domain names and IP addresses. DNS nameservers use this zone file to find out which IP address should be contacted when a user requests a particular domain name.
The zone file contains different classes of DNS records. For our purposes, we
will focus on the IN record class that defines the set of DNS records for the
Internet. All resource records use the following format, regardless of class or
type.
| host label | ttl | record class | record type | record data | |
|---|---|---|---|---|---|
| Example | example.com. | 60 | IN | A | 104.255.228.125 |
- Host Label. A host label defines the hostname of a record and whether the $ORIGIN hostname will be appended to the label. Fully qualified hostnames terminated by a period will not append the origin.
- TTL. TTL is the amount of time in seconds that a DNS record will be cached by an outside DNS server or resolver.
- Record Class. There are three classes of DNS records: IN (Internet), CH (Chaosnet), and HS (Hesiod). The IN class is used by the Internet, the other classes are used for alternate networks we won’t discuss here.
- Record Type. Defines the syntax and semantics for this record.
- Record Data. The actual data for the record, such as an IP address, hostname, or other information. Different record types will contain different types of record data.
A and AAAA Records
A and AAAA both map a domain to an IP address, with the A record used to
map a host to an IPv4 IP address, and an AAAA record used to map a host to an
IPv6 address.
The general format of these records is this:
sookocheff IN A IPv4_address
sookocheff IN AAAA IPv6_address
CNAME Records
CNAME records define an alias for an A or AAAA record. For instance, we
could have an A name record defining the “sookocheff” host and then use the “www”
as an alias for this host:
sookocheff IN A 111.111.111.111
www IN CNAME sookocheff
MX Records
MX records are used to define the mail exchanges used by the domain to route
email messages addressed to this domain to the appropriate mail server. Unlike
many other record types, mail records generally don’t map a host to something,
because they apply to the entire zone. As such, MX records are usually defined
with no host name at the beginning:
IN MX 10 mail.sookocheff.com.
Also note that there is an extra number in the record (10). This is the
preference number that helps computers decide which server to send mail to if
there are multiple mail servers defined. Lower numbers have a higher priority.
NS Records
This record type defines the name servers that are used for this zone.
You may be wondering, “if a namserver manages the zone file, why do we need to specify a nameserver in the zone file?”. To answer this, we need to think about what makes DNS so successful – it’s distributed database with multiple levels of caching. Fefining nameservers within the zone file is necessary because the zone file may be served from a cached or slave copy of the file on another name server. In this case, you need to reference the master nameserver in the zone file in cases where your cache is old or out of date.
Like the MX records, these are zone-wide parameters, so they do not specify
hosts. NS records look like:
IN NS ns1.sookocheff.com.
IN NS ns2.sookocheff.com.
An Example Zone File
The following file provides a full example of a zone file
$ORIGIN sookocheff.com.
@ 3600 SOA ns1.p30.dynect.net. (
zone-admin.dyndns.com. ; address of responsible party
2016072701 ; serial number
3600 ; refresh period
600 ; retry period
604800 ; expire time
1800 ) ; minimum ttl
86400 NS ns1.p30.dynect.net.
86400 NS ns2.p30.dynect.net.
86400 NS ns3.p30.dynect.net.
86400 NS ns4.p30.dynect.net.
3600 MX 10 mail.example.com.
3600 MX 20 vpn.example.com.
3600 MX 30 mail.example.com.
60 A 204.13.248.106
3600 TXT "v=spf1 includespf.dynect.net ~all"
mail 14400 A 204.13.248.106
vpn 60 A 216.146.45.240
webapp 60 A 216.146.46.10
webapp 60 A 216.146.46.11
www 43200 CNAME example.com.
In a zone file, $ORIGIN indicates a node in the DNS domain namespace tree. Any
labels below the origin will append the origin hostname to assemble a fully
qualified hostname. Any label within a record that uses a fully qualified domain
terminating with an ending period will not append the origin hostname. For
example, by stating $ORIGIN sookocheff.com., any record where the host label field is
not followed by a period will have sookocheff.com. will be appended to them.
This means that the label mail will be interpreted as mail.sookocheff.com..
The @ symbol is a special label that is simply a short-hand for $ORIGIN.
During resolution, the @ symbol will be replaced by example.com..
The $ORIGIN is followed by the zone’s Start Of Authority (SOA) record. A
Start Of Authority record is required for each zone. It starts with the primary
nameserver of the zone, and is followed by a block of metadata including the
e-mail address of the party responsible for administering the domain’s zone
file, the current serial number of the zone which should be modified whenever
data in the zone file changes, and various timing elements for caching, refresh,
and retry.
After the SOA portion of the zone file come the resource records this
nameserver knows about defined using the resource types listed in the previous
section.
Nameservers and Zones
Each domain namespace is served by a program called a nameserver. Nameservers generally have complete information about some part of the domain namespace, called a zone. The nameserver with this complete information is called the authority for that zone.
The difference between a namespace and a zone is subtle but important. Whereas a
domain is the strict labeling of a portion of the namespace, each domain can be
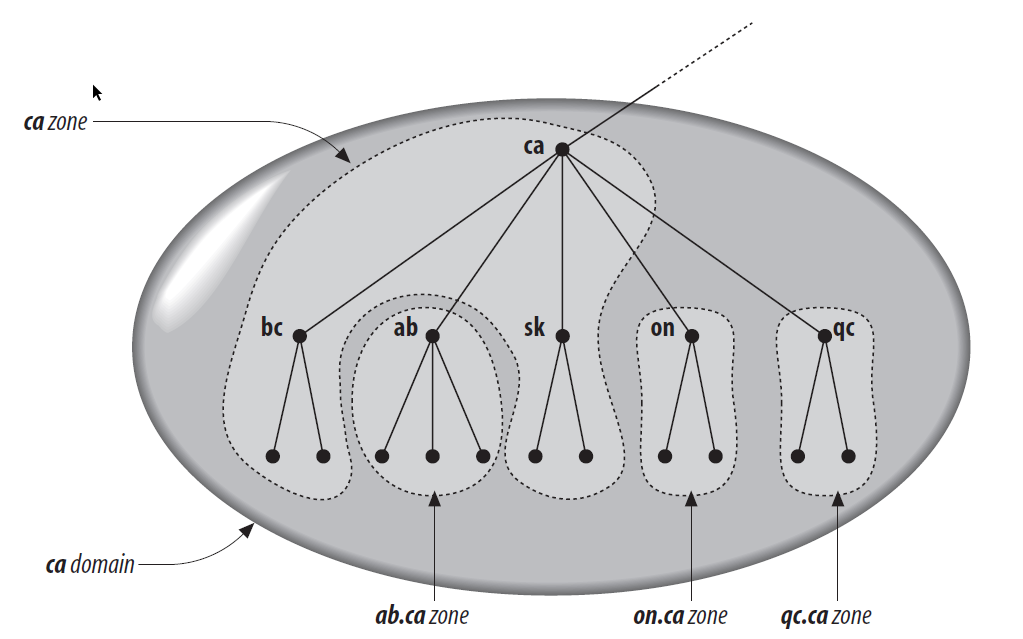
broken up into smaller units called zones by delegation. For example, the .ca
domain for Canada can be broken up into different zones for each province:
gc.ca, ab.ca, on.ca, and so on. Each of these provincial zones can be
administered by the provinces using authoratitive nameservers, while the .ca
zone would contain the delegation information pointing to the nameservers of
each of the delegated provincial zones. The .ca zone does not have to
delegate. In some cases, the top-level zone may be the authoritative nameserver
for some of the lower-level zones. The following figure, from the 5th Edition of
DNS and BIND shows an
example division of the .ca domain into multiple zones where some of the zones
are delegated to provinces and others are handled by the root .ca zone.
There are two types of nameservers in DNS: master (*or primary) servers that read zone data from a datafile on the host, and slave (or secondary) servers that read zone data from master or other slave servers. Whenever slave servers start-up, and periodically afterwards, they contact their master server to fetch updated data for their zone. The master server and any secondaries are all considered authoritative for a zone. The data on the servers are simply the resource records that describe the zone stored in a zone file. These records describe all the hosts in the zone and record any delegation points that direct to subdomains.
Resolvers
DNS resolvers are the clients that query for DNS information from a nameserver. These programs run on a host to query a DNS nameserver, interpret the response, and return the information to the programs that request it. In DNS, the resolver implements the recursive query algorithm that traverses the inverted namespace tree until it finds the result for a query (or an error).
Resolvers are only useful when doing DNS resolution, which we cover next.
Resolution: Putting it all Together
As we’ve discussed, the domain namespace is structured as an inverted tree. This structure allows a nameserver to use a single piece of information — the location of the root nameservers — to find any other domain in the tree.
The root nameservers are the authoritative nameservers for all top-level domains. That is, given a query about any domain name, the root nameservers can provide the names and addresses of the authoritative nameservers for the top-level domains. In turn, the top-level nameservers can provide the list of authoritative nameservers for the second-level domains, and so on. In this recursive fashion, every time a nameserver is queried, it will either return the data for the domains it is authoritative for, or it will return information that is closer to the correct answer.
The following diagram from Amazon’s Route 53 documentation gives an overview of how recursive and authoritative DNS services work together to route an end user to your website or application.
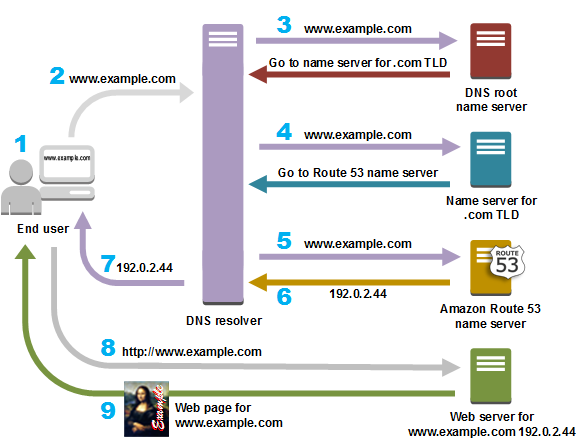
- A user opens a web browser, enters www.example.com in the address bar, and presses Enter.
- The request for www.example.com is routed to a DNS resolver, which is typically managed by the user’s Internet service provider (ISP), such as a cable Internet provider, a DSL broadband provider, or a corporate network.
- The DNS resolver for the ISP forwards the request for www.example.com to a DNS root name server. The root name server responds with the authoritative namerservers for the .com top-level domain (TLD)aut
- The DNS resolver for the ISP forwards the request for www.example.com again, this time to one of the TLD name servers for .com domains. The name server for .com domains responds to the request with the names of the nameservers that are associated with the example.com domain. In this example, those nameservers are implemented using Amazon Route 53.
- The DNS resolver for the ISP chooses an Amazon Route 53 name server and forwards the request for www.example.com to that name server.
- The Amazon Route 53 name server looks in the example.com hosted zone datafile for the www.example.com record, gets the associated value, such as the IP address for a web server, 192.0.2.44, and returns the IP address to the DNS resolver.
- The DNS resolver for the ISP finally has the IP address that the user needs. The resolver returns that value to the web browser. The DNS resolver also caches (stores) the IP address for example.com so that it can respond more quickly the next time someone browses to example.com.
- The web browser sends a request to the IP address that it got from the DNS resolver.
- The web server or other resource at 192.0.2.44 returns the web page for www.example.com to the web browser, and the web browser displays the page.
The example resolution we’ve used to convert the www.example.com domain into
the 192.0.2.44 IP address is fairly convoluted. To improve access speeds,
namservers typically cache query results to help speed up successive queries.
References
This article provides an introduction to DNS. If you want to learn more, there are several great resources to choose from: