Counting n-grams is a common pre-processing step for computing sentence and word probabilities over a corpus. Thankfully, this task is embarrassingly parallel and is a natural fit for distributed processing frameworks like Cloud Dataflow. This article provides an implementation of n-gram counting using Cloud Dataflow that is able to efficiently compute n-grams in parallel over massive datasets.
The Algorithm
Cloud Dataflow uses a programming abstraction called PCollections which are
collections of data that can be operated on in parallel (Parallel Collections).
When programming for Cloud Dataflow you treat each operation as a transformation
of a parallel collection that returns another parallel collection for further
processing. This style of development is similar to the traditional Unix
philosophy of piping the output of one command to another for further
processing.
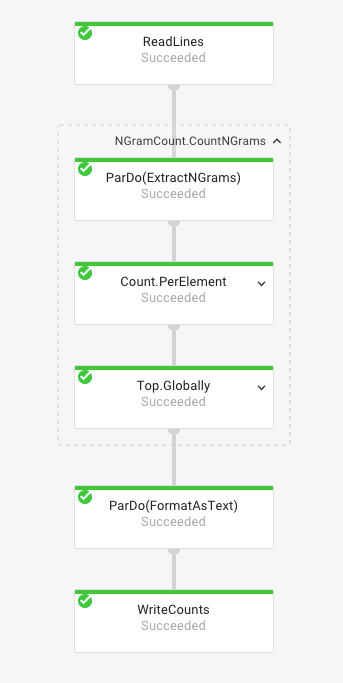
An outline of the algorithm for counting n-grams is presented in the following
figure. The first stage of our dataflow pipeline is reading all lines of our
input. We then proceed to extract n-grams from each individual line, outputting
the results as a PCollection. We then count the n-grams and take the top
n-grams in our dataset. Lastly, the results are output to a file.
As a concrete example, we can represent the same algorithm as transformations on a text file. In this example we will count the occurrence of bigrams.
I am Sam. I am Kevin.
First, the file is read as input and bigrams are extracted.
('I', 'am')
('am', 'Sam.')
('Sam.', 'I')
('I', 'am')
('am', 'Kevin.')
Next, for each element, we count the number of occurrences. This happens in two stages. First, we group all elements by key. This has the effect of combining all tuples with the same value to be on one line.
('I', 'am'), ('I', 'am')
('am', 'Sam.')
('Sam.', 'I')
('am', 'Kevin.')
From here, we simply count the number of elements in each group.
('I', 'am'), 2
('am', 'Sam.'), 1
('Sam.', 'I'), 1
('am', 'Kevin.'), 1
In Cloud Dataflow, the previous operations are combined into the
Count.PerElement operation that counts the number of times an element occurs.

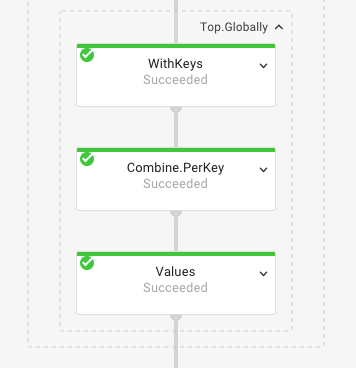
Once all the elements are grouped and counted, we can extract the top x
elements. To do this, we need to be able to combine elements across machines and
across files. Dataflow provides the Combine.PerKey operation for this purpose.
This operation merges elements from multiple files into a single file. We can
then take the top x results to view the top x bigrams. Dataflow provides a
convenience function Top.Globally to extract the top x results from a
PCollection.
Show Me The Code
Let’s go ahead and express our algorithm using Cloud Dataflow. The algorithm is
expressed in two parts. First, extracting n-grams from a block of text. This is
a simple transformation that takes a block of text as input and repeatedly
outputs individual n-grams. This list of n-grams serves as our initial
PCollection for the rest of the algorithm.
/**
* This DoFn tokenizes lines of text into individual ngrams;
* we pass it to a ParDo in the pipeline.
*/
static class ExtractNGramsFn extends DoFn<String, String> {
private static final long serialVersionUID = 0;
private Integer n;
public ExtractNGramsFn(Integer n) {
this.n = n;
}
@Override
public void processElement(ProcessContext c) {
// Split the line into words.
String[] words = c.element().split("\\s+");
// Group into ngrams
List<String> ngrams = new ArrayList<String>();
for (int i = 0; i <= words.length-this.n; i++) {
StringBuilder ngram = new StringBuilder();
for (int j = 0; j < this.n; j++) {
if (j > 0) {
ngram.append("\t");
}
ngram.append(words[i+j]);
}
ngrams.add(ngram.toString());
}
// Output each ngram encountered into the output PCollection.
for (String ngram : ngrams) {
if (!ngram.isEmpty()) {
c.output(ngram);
}
}
}
}
Second, we use the PCollection of all n-grams as input to a transform that outputs
the list of most frequently encountered n-grams in the corpus.
/**
* A PTransform that converts a PCollection containing lines of text into a PCollection of
* word counts.
*/
public static class CountNGrams
extends PTransform<PCollection<String>, PCollection<List<KV<String, Long>>>> {
private static final long serialVersionUID = 0;
private Integer n;
private Integer top;
public CountNGrams(Integer n) {
this.n = n;
this.top = new Integer(100);
}
public CountNGrams(Integer n, Integer top) {
this.n = n;
this.top = top;
}
@Override
public PCollection<List<KV<String, Long>>> apply(PCollection<String> lines) {
// Convert lines of text into individual ngrams.
PCollection<String> ngrams = lines.apply(
ParDo.of(new ExtractNGramsFn(this.n)));
// Count the number of times each ngram occurs.
PCollection<KV<String, Long>> ngramCounts =
ngrams.apply(Count.<String>perElement());
// Find the top ngrams in the corpus.
PCollection<List<KV<String, Long>>> topNgrams =
ngramCounts.apply(Top.of(this.top, new SerializableComparator<KV<String, Long>>() {
private static final long serialVersionUID = 0;
@Override
public int compare(KV<String, Long> o1, KV<String, Long> o2) {
return Long.compare(o1.getValue(), o2.getValue());
}
}).withoutDefaults());
return topNgrams;
}
}
Full Source Code
The rest of the code is boilerplate to setup the pipeline and accept user input. Feel free to use this code as a basis for your own pipelines.
package com.sookocheff.cloud.dataflow.examples;
import com.google.cloud.dataflow.sdk.Pipeline;
import com.google.cloud.dataflow.sdk.io.TextIO;
import com.google.cloud.dataflow.sdk.options.DataflowPipelineOptions;
import com.google.cloud.dataflow.sdk.options.Default;
import com.google.cloud.dataflow.sdk.options.DefaultValueFactory;
import com.google.cloud.dataflow.sdk.options.Description;
import com.google.cloud.dataflow.sdk.options.PipelineOptions;
import com.google.cloud.dataflow.sdk.options.PipelineOptionsFactory;
import com.google.cloud.dataflow.sdk.transforms.Aggregator;
import com.google.cloud.dataflow.sdk.transforms.Count;
import com.google.cloud.dataflow.sdk.transforms.DoFn;
import com.google.cloud.dataflow.sdk.transforms.PTransform;
import com.google.cloud.dataflow.sdk.transforms.ParDo;
import com.google.cloud.dataflow.sdk.transforms.Sum;
import com.google.cloud.dataflow.sdk.transforms.Top;
import com.google.cloud.dataflow.sdk.transforms.SerializableComparator;
import com.google.cloud.dataflow.sdk.util.gcsfs.GcsPath;
import com.google.cloud.dataflow.sdk.values.KV;
import com.google.cloud.dataflow.sdk.values.PCollection;
import java.io.IOException;
import java.util.*;
/**
* Count N-Grams.
*/
public class NGramCount {
/**
* This DoFn tokenizes lines of text into individual ngrams; we pass it to a ParDo in the
* pipeline.
*/
static class ExtractNGramsFn extends DoFn<String, String> {
private static final long serialVersionUID = 0;
private Integer n;
public ExtractNGramsFn(Integer n) {
this.n = n;
}
private final Aggregator<Long, Long> ngramCount =
createAggregator("ngramCount", new Sum.SumLongFn());
@Override
public void processElement(ProcessContext c) {
// Split the line into words (splits at any whitespace character, grouping
// whitespace together).
String[] words = c.element().split("\\s+");
// Group into ngrams
List<String> ngrams = new ArrayList<String>();
for (int i = 0; i <= words.length-this.n; i++) {
StringBuilder ngram = new StringBuilder();
for (int j = 0; j < this.n; j++) {
if (j > 0) {
ngram.append("\t");
}
ngram.append(words[i+j]);
}
ngrams.add(ngram.toString());
}
// Output each ngram encountered into the output PCollection.
for (String ngram : ngrams) {
if (!ngram.isEmpty()) {
ngramCount.addValue(1L);
c.output(ngram);
}
}
}
}
/** A DoFn that converts an NGram and Count into a printable string. */
public static class FormatAsTextFn extends DoFn<List<KV<String, Long>>, String> {
private static final long serialVersionUID = 0;
@Override
public void processElement(ProcessContext c) {
for (KV<String, Long> item : c.element()) {
String ngram = item.getKey();
long count = item.getValue();
c.output(ngram + "\t" + count);
}
}
}
/**
* A PTransform that converts a PCollection containing lines of text into a PCollection of
* word counts.
*/
public static class CountNGrams
extends PTransform<PCollection<String>, PCollection<List<KV<String, Long>>>> {
private static final long serialVersionUID = 0;
private Integer n;
private Integer top;
public CountNGrams(Integer n) {
this.n = n;
this.top = new Integer(100);
}
public CountNGrams(Integer n, Integer top) {
this.n = n;
this.top = top;
}
@Override
public PCollection<List<KV<String, Long>>> apply(PCollection<String> lines) {
// Convert lines of text into individual ngrams.
PCollection<String> ngrams = lines.apply(
ParDo.of(new ExtractNGramsFn(this.n)));
// Count the number of times each ngram occurs.
PCollection<KV<String, Long>> ngramCounts =
ngrams.apply(Count.<String>perElement());
// Find the top ngrams in the corpus
PCollection<List<KV<String, Long>>> topNgrams =
ngramCounts.apply(Top.of(this.top, new SerializableComparator<KV<String, Long>>() {
private static final long serialVersionUID = 0;
@Override
public int compare(KV<String, Long> o1, KV<String, Long> o2) {
return Long.compare(o1.getValue(), o2.getValue());
}
}).withoutDefaults());
return topNgrams;
}
}
/**
* Options supported by {@link NGramCount}.
*/
public static interface NGramCountOptions extends PipelineOptions {
@Description("Number of n-grams to model.")
@Default.Integer(2)
Integer getN();
void setN(Integer value);
@Description("Number top n-gram counts to return.")
@Default.Integer(100)
Integer getTop();
void setTop(Integer value);
@Description("Path of the file to read from.")
@Default.String("gs://dataflow-samples/shakespeare/kinglear.txt")
String getInputFile();
void setInputFile(String value);
@Description("Path of the file to write to.")
@Default.InstanceFactory(OutputFactory.class)
String getOutput();
void setOutput(String value);
/**
* Returns gs://${STAGING_LOCATION}/"counts.txt" as the default destination.
*/
public static class OutputFactory implements DefaultValueFactory<String> {
@Override
public String create(PipelineOptions options) {
DataflowPipelineOptions dataflowOptions = options.as(DataflowPipelineOptions.class);
if (dataflowOptions.getStagingLocation() != null) {
return GcsPath.fromUri(dataflowOptions.getStagingLocation())
.resolve("counts.txt").toString();
} else {
throw new IllegalArgumentException("Must specify --output or --stagingLocation");
}
}
}
}
public static void main(String[] args) throws IOException {
NGramCountOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(NGramCountOptions.class);
Pipeline p = Pipeline.create(options);
p.apply(TextIO.Read.named("ReadLines").from(options.getInputFile()))
.apply(new CountNGrams(options.getN(), options.getTop()))
.apply(ParDo.of(new FormatAsTextFn()))
.apply(TextIO.Write.named("WriteCounts").to(options.getOutput()));
p.run();
}
}