I was first introduced to ML through the Coursera Programming Languages course. After the initial learning curve, I was impressed by the power of the type system and the flexibility of pattern matching. I’ve been wanting to resume my education in functional programming, and am picking up OCaml for a personal project I’m working on. Diving into the OCaml ecoystem, I was drawn to Reason, a new syntax for OCaml, and BuckleScript a compiler that integrates OCaml with the JavaScript ecosystem. The relationship between Reason, BuckleScript, and OCaml can difficult to understand, leading to this blog post about the OCaml compiler pipeline that highlights the intersection between OCaml and BuckleScript.
The OCaml compiler toolchain
Compiling source code into an executable involves a fairly complex set of parsers, libraries, linkers, and assembers. To develop its statically safe type system, OCaml runs code through a series of stages where each stage performs a unique job independent of other stages in the pipeline. For example, one stage of the compiler pipeline checks for type safety using knowledge of the OCaml type system, while the final stage of the OCaml compiler is outputting low-level assembly code that knows nothing about OCaml objects.
The book Real World OCaml provides an overview of the compilation pipeline that we can walk through to understand the entire process. Nodes in the diagram refer to build artifacts, and arrows are tasks or processes that convert build artifacts to different representations.
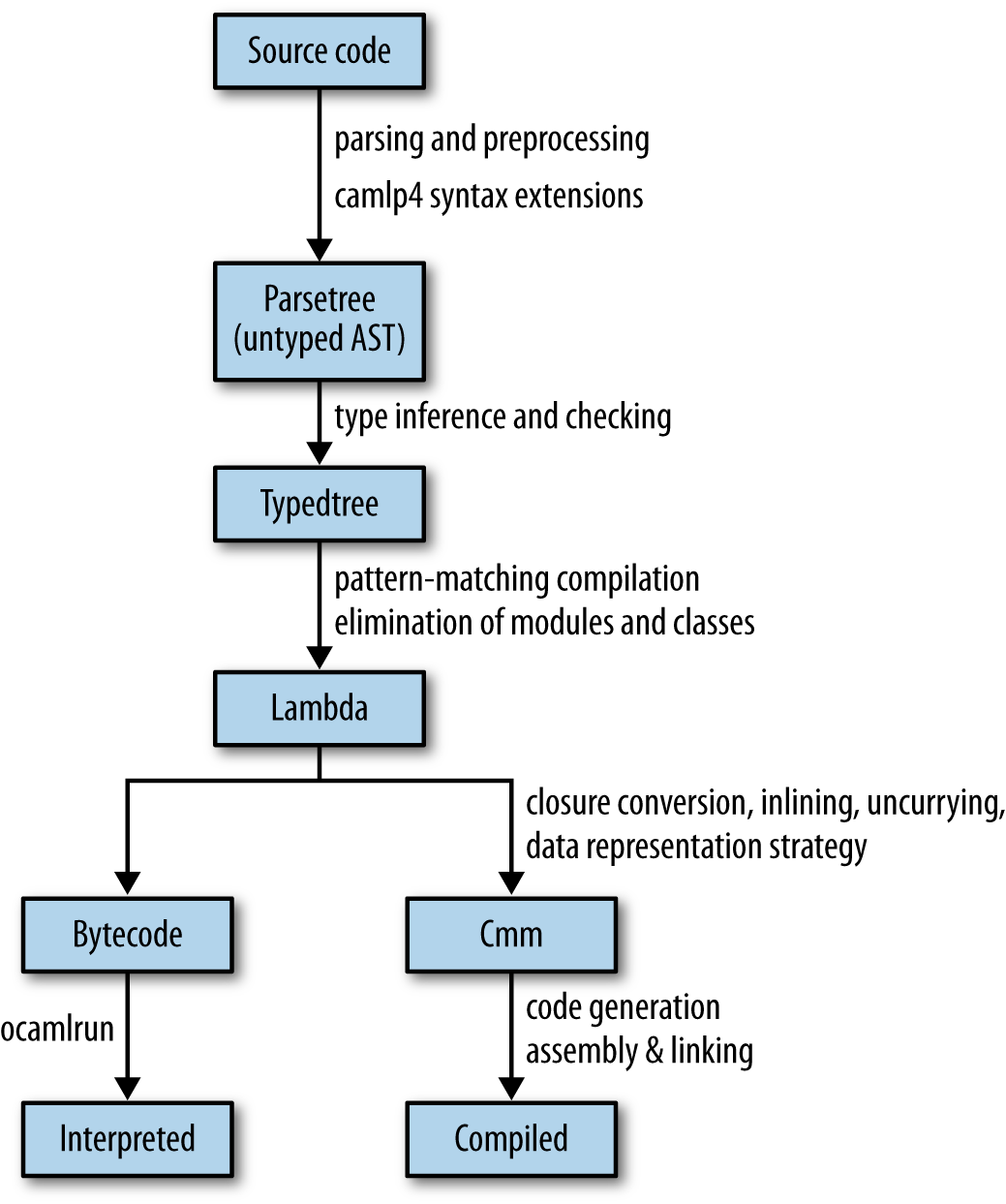
Parsing
The OCaml compiler operates on source files. The first task in the pipeline is to parse the source code into a structured abstract syntax tree (AST). the parsing directory in the source distribution. Assuming the source file is valid OCaml sytanx, the abstract syntax tree is the first artifact generated by the comiler pipeline.
Type Checking
Given the syntax tree, the next stage in the pipeline is to verify that the syntax obeys the OCaml type rules. At this stage, OCaml performs three tasks:
- automatic type inference. Calculates types for a module where there are no type annotations.
- module system. Combines together modules using the knowledge of their type signatures to make sure that types match across modules.
- explicit subtyping. Checks that polymorphic rules are correct.
When the type checking process has successfully completed, it is combined with the AST to form a typed abstract syntax tree containing precise location information for every token in the input file with concrete type information for each token.
Lambda
The parsing and type checking stage form OCamls error checking capabilities. Once the source file has passed these stages, it can stop emitting syntax and type errors and begin the process of compiling the well-formed modules into executable code.
Since we have verified that the source code is valid and conforms to OCaml’s type rules, the Lambda stage of the compiler pipeline eliminates the static type information into a simpler intermediate lambda form that can be optimized into high-performance code. This stage discards object and module information, and simplifies high-level concepts like pattern matching into optimized state machines .
After the lambda form has been generated, the OCaml compiler pipeline branches into two separate compilers: one for bytecode and one for native code.
Bytecode
Bytecode has the advantage of being simple, portable, and easily compiled, with the disadvantage of being slower to execute and requiring an OCaml runtime. Bytecode generated by the compiler is run by an OCaml runtime that includes an interpeter, garbage collection facilities, and some C functions that implement low-level system calls.
Native Compilation
Native compilation is typically used for production use-cases. The compilation process is slower, but the resulting binary is highly optimized and offers faster performance.
Compiling OCaml to JavaScript using js_of_ocaml
The seperation of the OCaml into multiple stages with distinct artifacts at each stage leads to some interesting possibilities. js_of_ocaml shows one such possibility. By using the bytecode output by the OCaml compiler, we guarantee that the source code has alredy been verified as syntax and type system compliant. The js_of_ocaml project takes this bytecode and converts it to JavaScript code by inserting into the pipeline as shown in the following figure from Javier Chávarri:

Compiling OCaml to JavaScript using BuckleScript
BuckleScript takes a different approach to the same problem by inserting at a different point in the OCaml compiler pipeline, shown in the following figure:
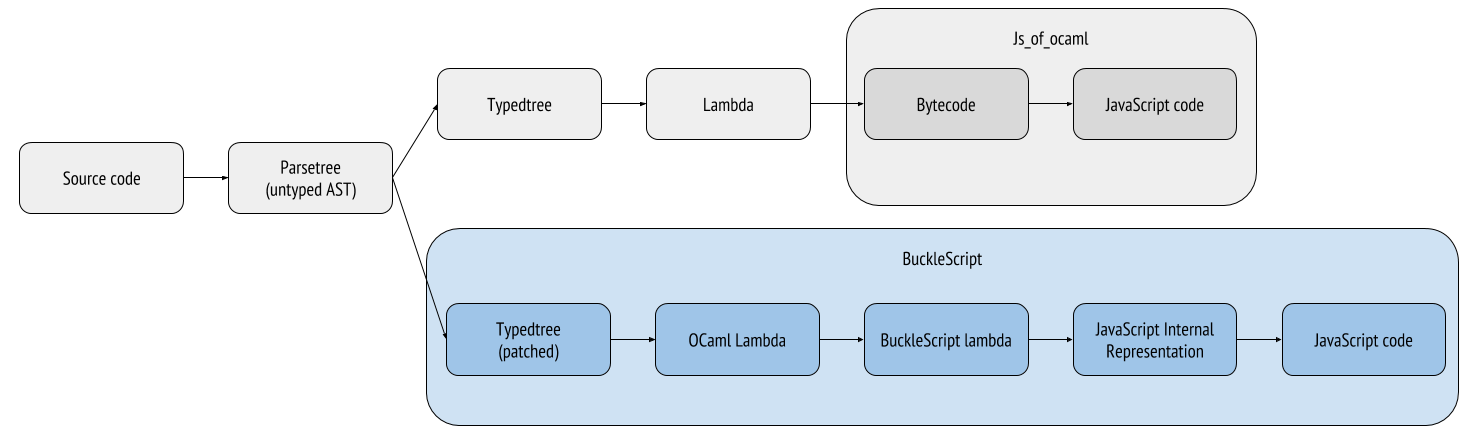
BuckleScript leverages the similarities between JavaScript and OCaml to convert the lambda representation of the code to a JavaScript compatible representation before reducing to native JavaScript.
The OCaml compiler takes a pipeline approach that converts each build artifact to a subsequent representation, adding or removing information at each stage of the process. This pipeline approach offers some flexibility in adapting and extending the compiler into new use cases. This post showed two examples of these use cases: leveraging the lambda representation to generate JavaScript using the BuckleScript compiler, and leveraging the bytecode representation to generate JavaScript by converting bytecode directly.