The Google Prediction API offers the power of Google’s machine learning algorithms over a RESTful API interface. The machine learning algorithms themselves are a complete black box. As a user you upload the training data and, once it has been analyzed, start classifying new observations based on the analysis of the training data. I recently spent some time investigating how to use the API to determine the sentiment of a tweet. This article collects my thoughts on the experience and a few recommendations for future work.
The Data
For our experiment we took the text and rating of one million online reviews and normalized them within a scale of zero to 1000 – ratings on a scale of one to four and ratings on a scale of one to ten would be roughly equivalent. We then segmented the reviews into five broad categories: very negative (0-200), negative (200-400), neutral (400-600), positive (600-800), very positive (800-1000). The prediction API requires the data to be in a specific format; following their guidelines, we stripped the review text of all punctuation except the apostrophe and lower cased all characters. What was left was a one million row table with two columns: the review category and the review content.
very negative, "the waiter was so mean"
positive, "the bisque is the best in town"
...
Our data was roughly 1 GB. We uploaded this file to Google Cloud Storage and used the Prediction API to train our model given this dataset.
Examples
Once we had a trained model it was time to make predictions. For our application we took tweets from Twitter mentioning a business and asked the Prediction API to classify the text of the tweet for sentiment between very negative to very positive using the normalized review categories of our model. The results were decidedly mixed as the following examples show. In the first example we attempt to classify the text “this restaurant has the best soup in town” and correctly receive a “very positive” result.
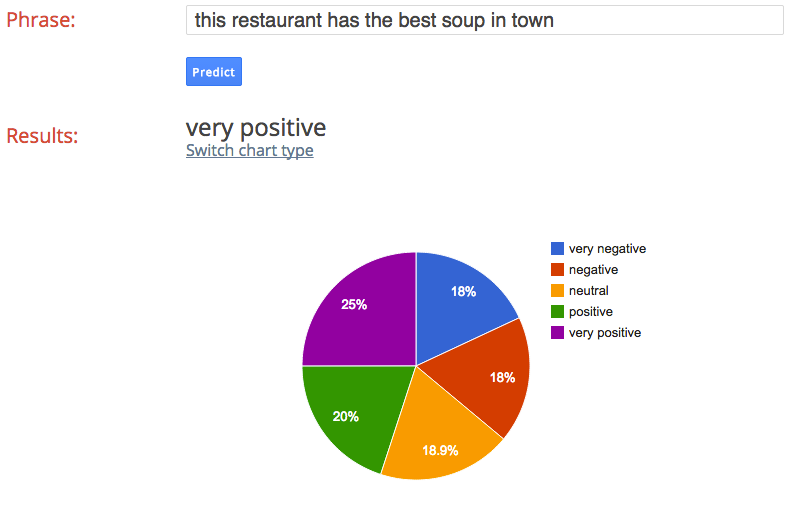
As a counter example, the text “this restaurant has the worst soup in town” also recieves a “very positive” result, although with less confidence and with “very negative” being the most likely second choice.
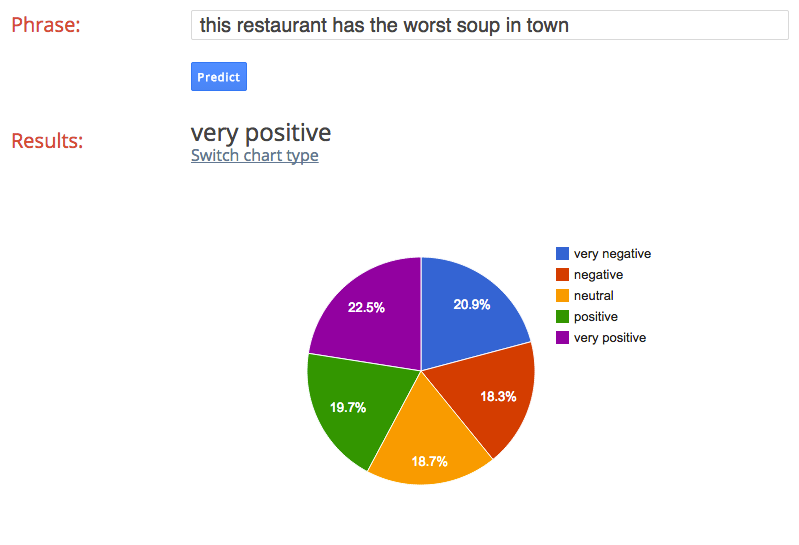
Conclusions
Most of the tweets were categorized as very positive, regardless of content. In addition, most of the tweets had almost equal likelihood of being in the very negative or very positive category with very positive being more likely most of the time.
Why is this?
Most Internet reviews are either very positive or very negative so most of the content from the tweet will fall into one of these categories in our model. I believe that by adjusting our training data to have equal amounts of reviews for each category we would get better results.
My recommendation is that if you intend to use the Prediction API for a serious business task that you also have a strong enough background in machine learning to tweak your model before using the Prediction API to analyze and host it. In short, use the Prediction API as cloud-based access to your existing model that you already know works. Don’t use the Prediction API to help you build a working model. The black box nature of the Prediction API makes it difficult to diagnose and correct any data problems you may have.