
As a software system scales it becomes sufficiently large that the number of working parts, coupled with the number of working programmers making changes on it, makes the behaviour of the system extremely difficult to reason about. This complexity is exacerbated by the transition of many organizations towards a microservice architecture, as exemplified by the so-called “death star” architecture, where each point in the circumference of the circle represents a microservice and the lines between services represent their interactions.

Image credit: An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., ASPLOS’19
There are some techniques organizations have used to try and tame complexity in such an environment. For example, leveraging event-based infrastructure like Kafka as a unifying data abstraction, or distributing coordination of multiple services using sagas, or partitioning the system into domains using domain-driven design. My own research has led me to ideas for modelling software using concepts from systems engineering like the design structure matrix.
Although these techniques can mitigate the effects of complexity in large systems, there is still sufficient complexity inherent in the problem space itself that we largely fail to enforce much order in the overall system other than some simplified diagrams that vastly minimize the scope of the problem.
This post argues that maybe we are thinking about this problem from the wrong direction. That is, rather than trying to control complexity in large systems, we can instead embrace and use this complexity to model the behaviour of the system, and then to create the correct incentives that help the individual parts succeed while also benefiting the overall system itself.
But first, a detour into what, exactly, a complex system is.
Complex Systems
Software at scale certainly matches the Wikipedia definition of a complex system.
A complex system is a system composed of many components which may interact with each other.
This definition can be further refined by defining complex as any system whose behaviour is difficult to model due to the dependencies, relationships, and interactions between component parts. More colloquially, complex systems are often referred to as “wholes that are more than the sum of their parts.” That is, systems whose overall behaviour cannot be understood without looking at the individual components and how they interact, and at the same time, cannot be understood by looking only at the individual components and ignoring systemic effects.
For example, consider an economic system based on dollars. The properties and characteristics of an individual dollar bill are completely insufficient for describing the system behaviour of a run on bank funds caused by a stock market crash. And yet the bank run could not happen without the component dollar bills and their interactions with other components of the system. An economy can therefore be referred to as a whole that is more than the sum of its parts, and thereby complex.
Although complex systems are, by their very nature, difficult to understand, what makes them interesting is the distinct properties that arise in them due to the complexity itself, and the change in viewpoint that complex systems require us to take to help guide their behaviour.
The study of complex systems regards collective, or system-wide, behaviours as the fundamental object of study; for this reason, complex systems can be understood as an alternative paradigm to reductionism, which attempts to explain systems in terms of their constituent parts and the individual interactions between them.
By accepting that large-scale software systems are, in fact, complex systems, we can turn the problem of controlling complexity on its head. Instead of trying to reduce complexity by isolating individual components and applying design techniques aimed at simplifying them, is it possible to leverage the properties of complex systems to achieve our goals through system-wide means?
Software as a System
Software systems are typically considered “open”. That is, they accept input from outside of their environment, act on that input, and respond with some form of output.
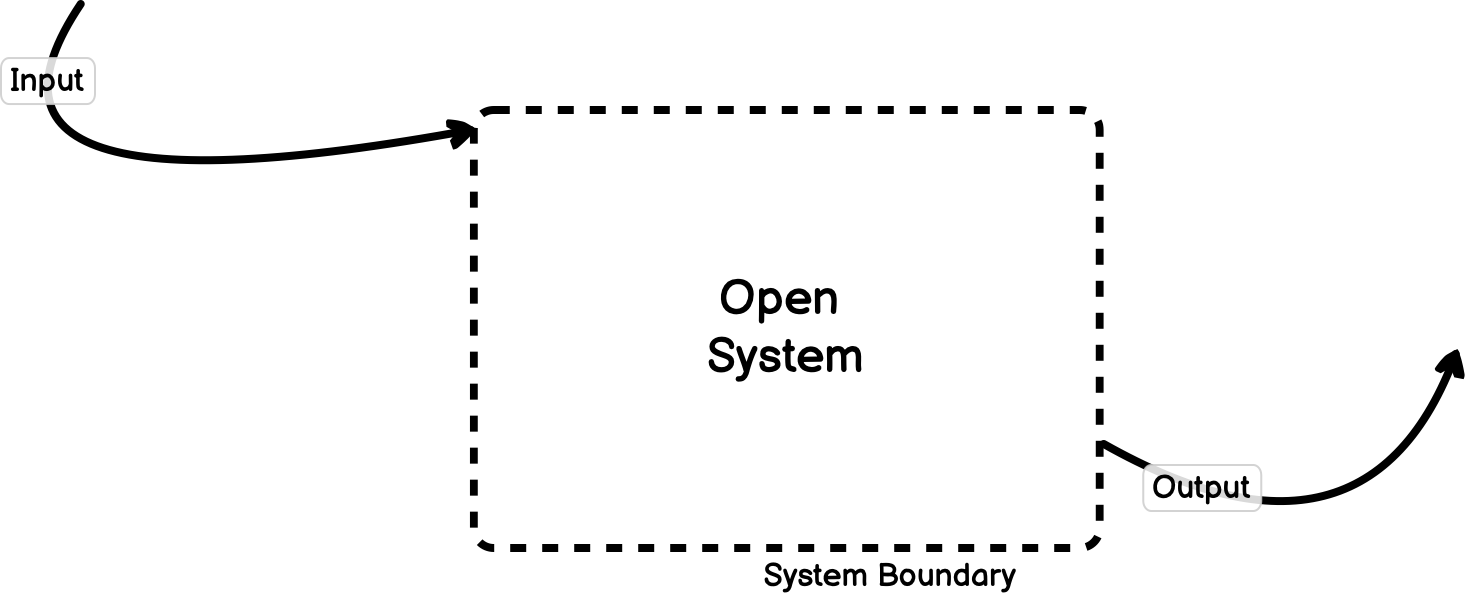
Within the system, there is a set of entities that have dependencies and relationships on one another. Together these sets of entities and relationships form a unified whole that is defined in terms of a boundary between the system and its surrounding world.
Consider a system for booking vacations consisting of a car booking service, flight booking service, and a hotel service. It also has a frontend that presents the API for booking entire trips composed of each of these components. Built as a service-oriented system, each of these services are independent yet related.
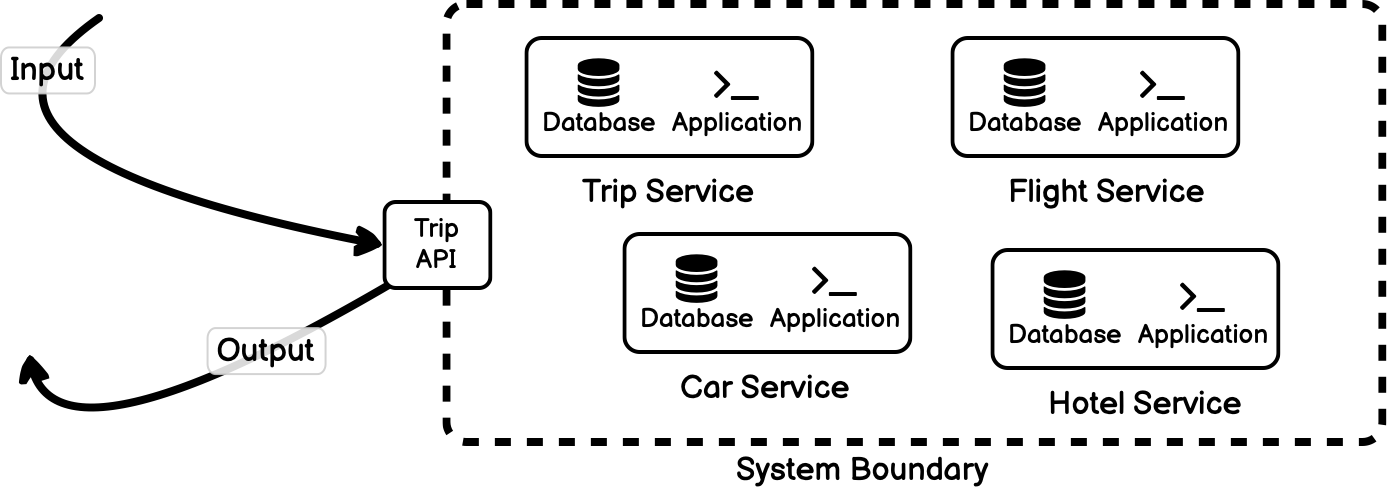
The trip service is clearly a system: it is a set of entities (individual services) that interact to form a unified whole (the trip booking system). And there is a clear system boundary defined by the public facing API.
The study of complex systems has determined that all systems have a common set of properties and behaviours by virtue of being a system. These properties emerge regardless of the individual components of the system, or how its parts behave. Let’s look at some of the common properties that all complex systems exhibit, such as nonlinearity, emergent behaviour, and adaptivity, and how we can relate them to software systems.
Nonlinearity
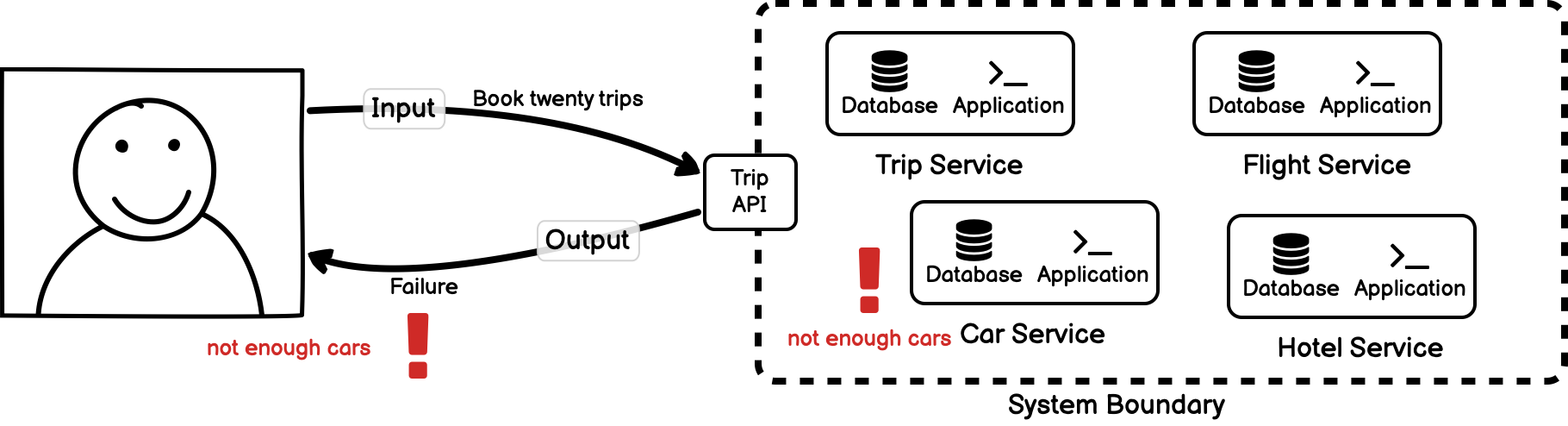
Nonlinearity simply means that the system may respond in different ways to the same input depending on its state or context. Another way of stating the same thing is that a nonlinear system is one where a change in the magnitude of an input does not produce a proportional change in the output. Referring to our trip booking example, we can see that this may apply as we reach the limits of the software. If we book one request for a trip, we will receive one output response for the successful trip booking.
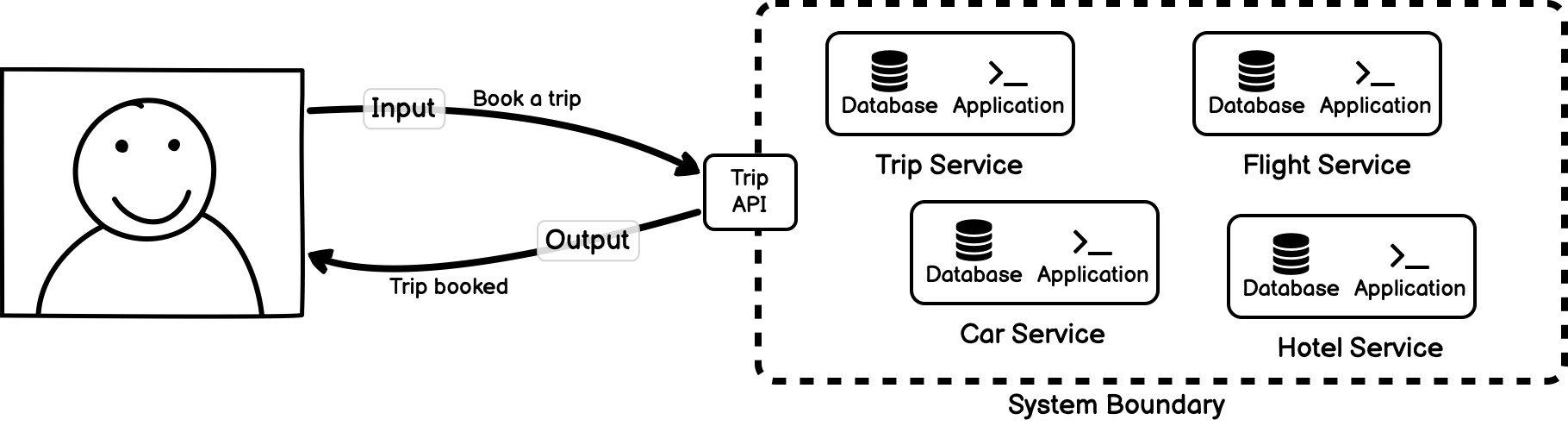
Given this system behaviour, the user might reasonably expect booking ten trips to result in ten successful trip bookings.
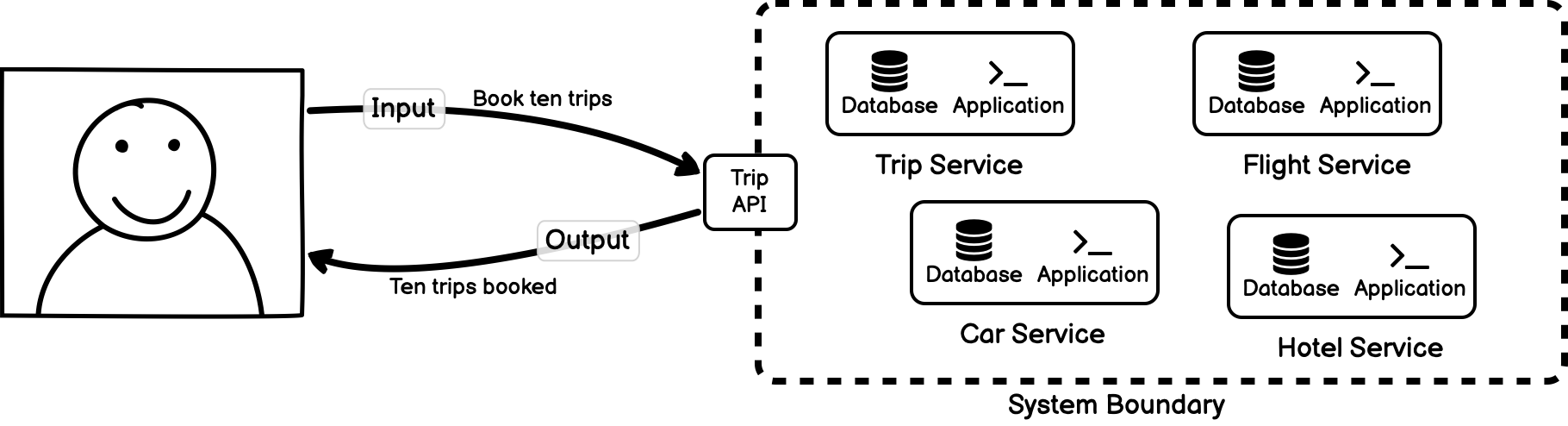
However, for some changes in input, the system may yield changes that aren’t exactly proportional to the change in input (or it may even yield no output at all). For example, if we request twenty bookings we may exceed the limit of available cars — a contextual detail of the individual car service — which changes the system response.
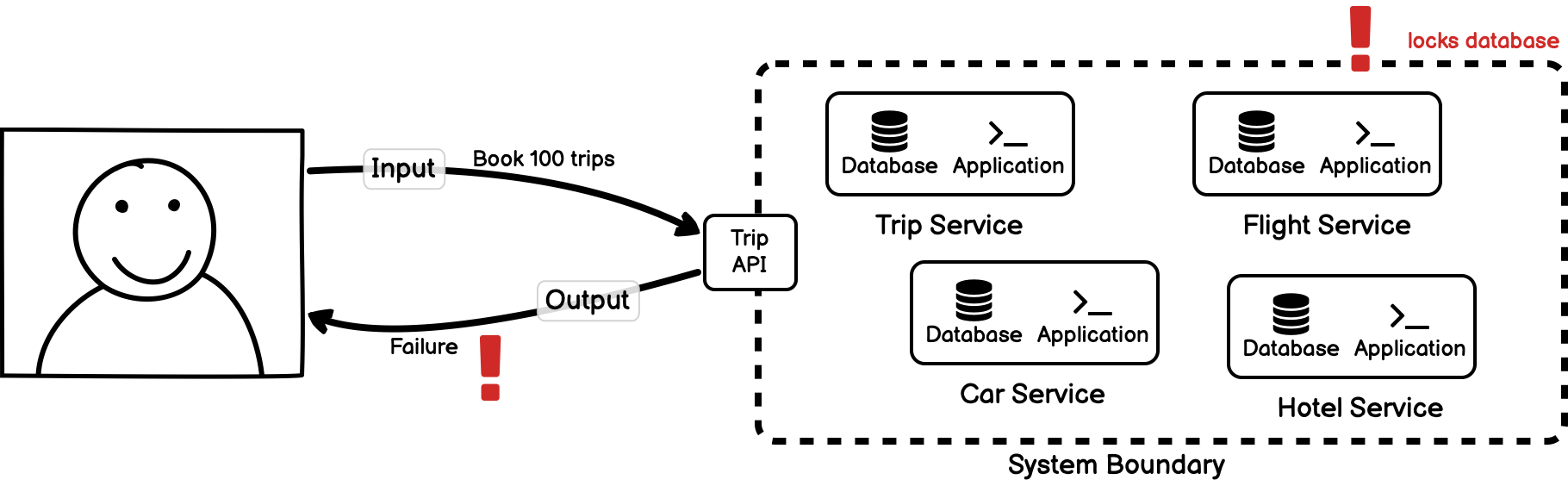
Or, we may make a request that is large enough that it triggers undefined behaviour in one part of the system. For example, the flight service has a previously undiscovered bug where attempting to book more than 50 flights at the same time locks the database. The request triggers this undefined behaviour to occur, and the system call fails.
Nonlinearity is often referred to as sensitivity to initial conditions, or the so-called “butterfly effect” derived from the metaphorical example of a tornado being influenced by the minor perturbations in air current made by a distant butterfly flapping its wings. In such a system, small changes to initial conditions can lead to dramatically different outcomes making it extremely hard to model numerically or deterministically because very small rounding errors at some stage in the model can generate completely inaccurate or exaggerated output.
Returning to our flight booking example, we can imagine our system deployed to a set of EC2 instances on AWS. Further, imagine that the hotel service writes logs to disk without flushing them periodically. At some point, the initial condition for a single API request is such that the local disk for our running application is almost, but not quite, full. The next request triggers a log that exceeds the capacity of the local disk and the application fails to respond. In this case the application cannot recover and is completely disabled until the disk can be flushed. In the meantime, all subsequent calls to this service will fail and the output of the system has significantly changed due to the initial condition of the local disk of a single service.
Emergent Behaviour
Another common feature of complex systems is the presence of emergent behaviour, often called emergence. Emergent behaviours are the traits of a system that are not obvious or apparent from the individual components in isolation, but that occur as a result of the interactions, dependencies, and relationships that form when they are placed together in a system.
Emergent behaviours are the things that are unplanned or difficult to predict solely from analyzing the individual entities that make up a system. One example of a emergent behaviour comes directly from computer science: Conway’s Game of Life. This game takes place on a grid of many cells. Each cell having only two possible states: alive (on) or dead (off). At each discrete step in time, the state of a cell can change from alive to dead or vice versa in response to the state of neighbouring cells.
Although the rules in Conway’s Game of Life are only defined locally for each, they have been shown capable of producing globally interesting global behaviour. For example, the Game of Life is capable of producing a “pulsar” pattern that shows some form of global organization and stability.

Image Credit: JokeySmurf en.wikipedia - created using www.conwaylife.com
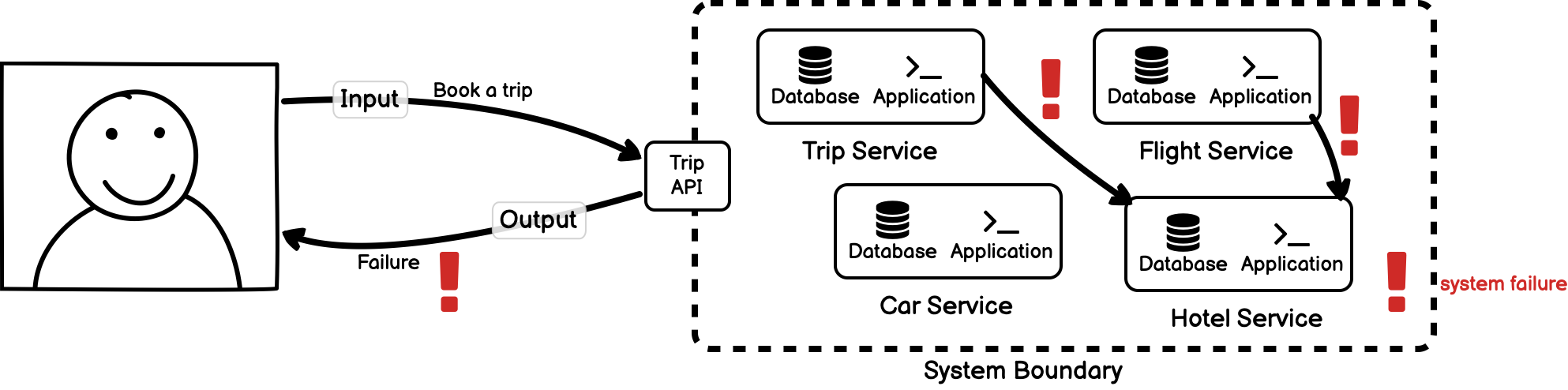
Returning to our trip booking example, can we develop globally emergent behaviour from the individual components of the system? While emergence is often used to refer only to the appearance of unplanned behaviour that appears organized, it can also refer to the breakdown of a system or an organization; it describes any phenomena which are difficult or even impossible to predict from the smaller entities that make up the system. Within our trip booking system, we can absolutely encounter systemic issues which are difficult to predict from the smaller entities themselves. One common example of this phenomenon is cascading failures. A fundamental problem in one system could be a memory leak, blocked threads, or a database fault. Once encountered or triggered by environmental issues, the failure in one system can easily propagate to other systems. If left unchecked, the breakdown of any organizational structure of the system is inevitable.
Adaptivity
Adaptive systems are special cases of complex systems that can change and learn from experience. Examples of complex adaptive systems can be found in the stock market, in ant colony behaviour, in the human brain and immune system, in cities, and more. In each of these cases, both the behaviour of individual components and the behaviour of the collective system itself can change, mutate, or self-organize in response to events. In computer science, neural networks and genetic algorithms are examples of systems that can adapt, learn, mutate, and evolve over time and in response to conditions.
More practically, we can apply the concept of adaptivity to microservice systems by developing the correct set of architectural fitness functions that provide the correct feedback to teams. A well-known example is chaos engineering: by injecting artificial failure conditions into the system, teams develop and learn the correct responses to failures and make individual services more resilient. In response to these changes, the entire system becomes more resilient.
Adaptation in software systems can also occur due to the learning done by organizations that build them: individual services are built by teams of people, and how we incentivize those teams can help develop the correct adaptive behaviour we want from the entire system itself. For example, if the culture of your organization is to reward engineers for delivering features on time, regardless of reliability or engineering quality, then teams and individuals will adapt to this by focusing more on delivering features on time. If, on the other hand, you incentivize resilient and reliable systems and reward individuals accordingly, the system itself will adapt to become more reliable and resilient over time.
This view of adaptation acknowledges that software systems are an example of socio-technical systems that are influenced by human, social, and organizational factors, as well as technical factors, and that it can be hard to separate the two. Where you place incentives and how you model acceptable behaviour in such systems becomes more important.
Making Complex Software Work
Based on these observations, it seems clear that service-oriented software systems are, in fact, complex systems, and that the study of complex systems can tell us a lot about software systems if we are willing to make some connections.
We need to consider both the behaviours of individual systems and how we incentivize them, as well as the behaviours of the collective system, and be able to establish the link between the two. Unfortunately, when things become sufficiently complex, it becomes very difficult to link cause and effect, and very difficult to make predictions. We see this with large software systems: it becomes extremely difficult to predict the effect of a local change on the overall system. We rely on testing to fix this to some extent, but testing also has limits as we start to look at systemic behaviour. The puzzle then becomes how we make decisions and operate in a complex environment that cannot be reduced to individual parts.
One approach is from the article Strategy as Simple Rules, which recommends creating a set of guiding rules or principles that are fixed. These are the things that the organization cares about and stands for. Once fixed, you can then let people and teams decide for themselves how to behave given their local knowledge and experience on the ground. In an ideal case, the team never violates the basic rules, but they have a lot of flexibility to decide from moment to moment how to act to reach the required goals. In this model, like in Conway’s Game of Life, the correct systematic behaviour emerges solely from local decisions. And since we are dealing with software systems, we can codify and automate these rules to the greatest extent possible.
To make this work effectively, you need to able to surrender some control and admit that you don’t necessarily know what teams are going to do next, as long as they have specific ways of thinking about and making decisions. You also need to be able to kill off projects that don’t work to ensure the healthy evolution of the whole. Lastly, it requires management courage to strictly enforce the fixed set of principles and rules and hold teams accountable to meeting them. If each team can bend the rules for personal reasons, the emergence of organized behaviour will be stunted.
We also need to consider how diversity plays a role in complex systems. Complex adaptive systems are evolutionary in nature, and because it is an environment where prediction is difficult, it pays dividends to consider diverse viewpoints, and aggregate the data from those viewpoints effectively to tune the system and make decisions. According to Tim Sullivan in Embracing Complexity, “when information is diverse and aggregation and incentives are healthy, you get very good answers to problems. That’s what nature is doing”.
Connecting these threads together, how do we build successful complex software systems? I’ve reduced that problem down to three main points:
- Define a set of quality architecture principles that the organization believes in and that are systematically enforced. These are the immutable rules governing how individual components within the system behave.
- Develop quality information aggregation systems that allow leaders to determine which components of the system are following the rules, which ones are succeeding and should be nurtured through incentives, and which ones are failing and should be killed.
- Experiment widely and encourage diversity in how we build teams and how we build software. The more broadly we experiment and learn, the more chance we have of breakthroughs that can evolve into the behaviour we want.
Together, these three points allow us to take advantage of the unique properties of complex systems to guide system evolution. By turning the problem on its head, we can avoid reducing software systems into individual components and begin viewing them as the complex socio-technical systems that they are.