After reading the Thrift whitepaper and sending your first message, you may still have some questions about how Thrift actually works. This article helps answer those questions by providing a guided tour through the Apache Thrift architecture, highlighting the protocols, transports, and compiler, and how they interact with each other.
Thrift from 10,000 feet
At a high-level, Thrift is organized into several layers as in Figure 1. The layers highlighted in yellow represent application code that is written by a user. The portions in red represent code generated by the Thrift compiler from an interface definition defined in an IDL file. The layers in orange are portions of Thrift available as library code imported into your application as a dependency. Lastly, the device layer in blue represents the physical device transmitting messages.
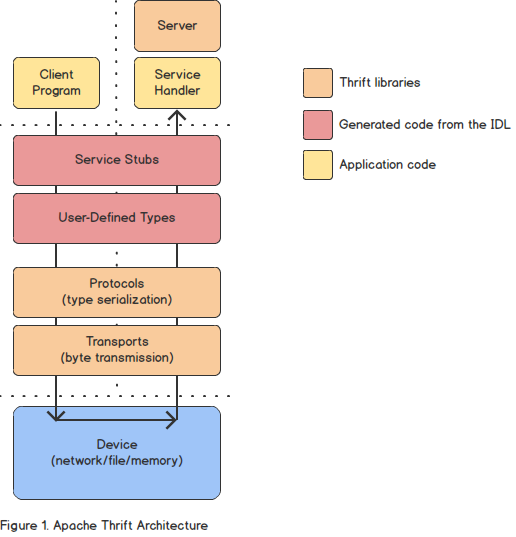
To understand the Thrift architecture requires understanding how each of the layers in Figure 1 interact with one another. Let’s figure that out by discussing each of the layers in turn.
Transports
The Thrift transport layer provides an abstraction over physical devices. This allows Thrift to mask device specific details and provide a common API for upper layers that need to use physical devices. Specifically, the transport layer handles byte-level communication with the underlying device. By providing this abstraction, Thrift allows for new devices or middleware to be supported without any impact to the rest of the Thrift architecture.
Transports are further organized into composable layers called a transport stack. This functionality allows you to abstract a physical device using a particular transport, then wrap that abstraction with another logical transport layer such as buffering or encryption, without changing the interface to transport consumers. Furthermore, the application is free to select or change the transport stack at compile time or run time, allowing you to define a flexible transport stack suitable for different needs.
Protocols
Protocols provide the means for serializing data types into byte streams for use by transports. Thrift does not support every type in every language. Rather, it supports a basic type system that can be converted into representations in each language. Any valid Thrift protocol implementation must be capable of reading and writing all types defined by the Thrift type system (specified by the Thrift interface definition language, or IDL).
The protocol layer sits on top of a transport stack and has the responsibility of serializing language specific data types into language-agnostic byte streams capable of being transmitted using a transport stack. The client and server are required to use the same serialization protocol for proper communication.
The IDL and Compiler
The IDL is designed to make describing an applications data types and interfaces language independent. This language independent representation is then used by the Thrift compiler to generate language specific implementations of the data types and interfaces for use by a user application.
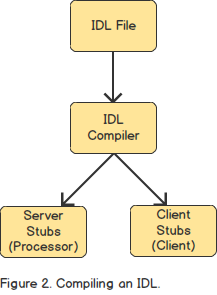
User-Defined Types
While protocols are responsible for serializing at the individual data type level, the IDL provides support for user-defined data types, structs, and interfaces, allowing for cross-language serialization of rich structured data and interfaces. The Thrift compiler uses the IDL to generate code that automates the serialization of these more complex data structures using particular protocols.
Service Stubs
The compiler is also responsible for generating service stubs used by clients and servers to fulfill any interfaces defined by the IDL. This provides Thrift users support for cross language RPC. The service stubs can be divided into two parts: client and server.
Client Stubs
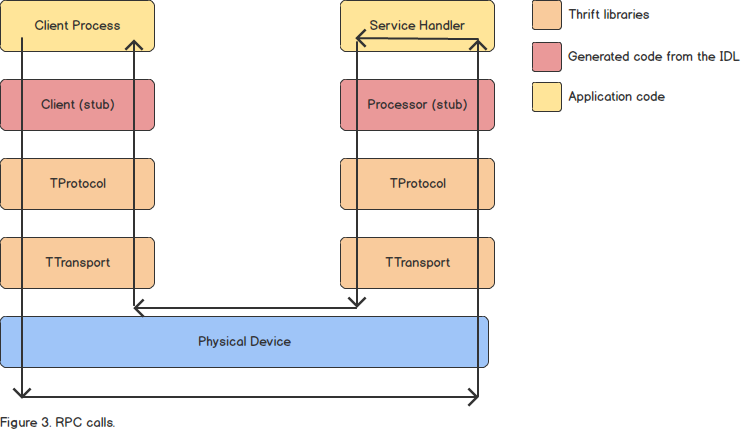
The client stub acts as a proxy for the remote service. The client process calls the proxy to interact with the service and the proxy handles communication with the underlying protocol and transport. The protocol and transport are responsible for serializing the messages and receiving back the results.
Server Stubs
The server stub uses the protocol and transport stack to deserialize incoming method calls, providing hooks into user-defined code for processing messages as they arrive. The result of these method calls are then serialized again using the same protocol and transport stack and delivered back to the client.
The user-defined code is responsible for implementing the service interface. This code is called by the generated service processor for each incoming request.
The full request-response life cycle is shown in Figure 3.
Wrapping Up
That concludes our guided tour to Thrift outlining the key functionality of each layer in the Thrift architecture. The transport is responsible for device abstraction, while the protocol is responsible for data serialization. The IDL and compiler are responsible for user-defined types and service interfaces for each supported language.