Computers generally track the current time using a quartz crystal that oscillates at a known frequency. This frequency is used to advance the local clock at pre-defined intervals. Quartz oscillates with enough stability that it can be used to maintain time within a few milliseconds of accuracy per day. Over time however, these imperfections can accumulate, making the clock inaccurate. To fix these inaccuracies, computers typically run a background process like NTP to synchronize the local clock with servers that are known to be accurate.
This model works well when you care only about the time of a local computer, but fails when you need to compare events that happen on different computers to see which one happened first. NTP allows for a margin of error between the local clock and the accurate time. It also makes corrective adjustments at periodic intervals. These factors can make it appear that one event happened before the other if measured solely by the local clock. Unfortunately, this means that it is impossible to meaningfully compare the timestamps on two different servers to establish any sense of ordering.
In the following example, Server A and Server B are running independently and tracking time using their local clocks. To an outside observer, Event A happened before Event B, but due to differences in the local clock, Event B is registered with a timestamp at an earlier point.
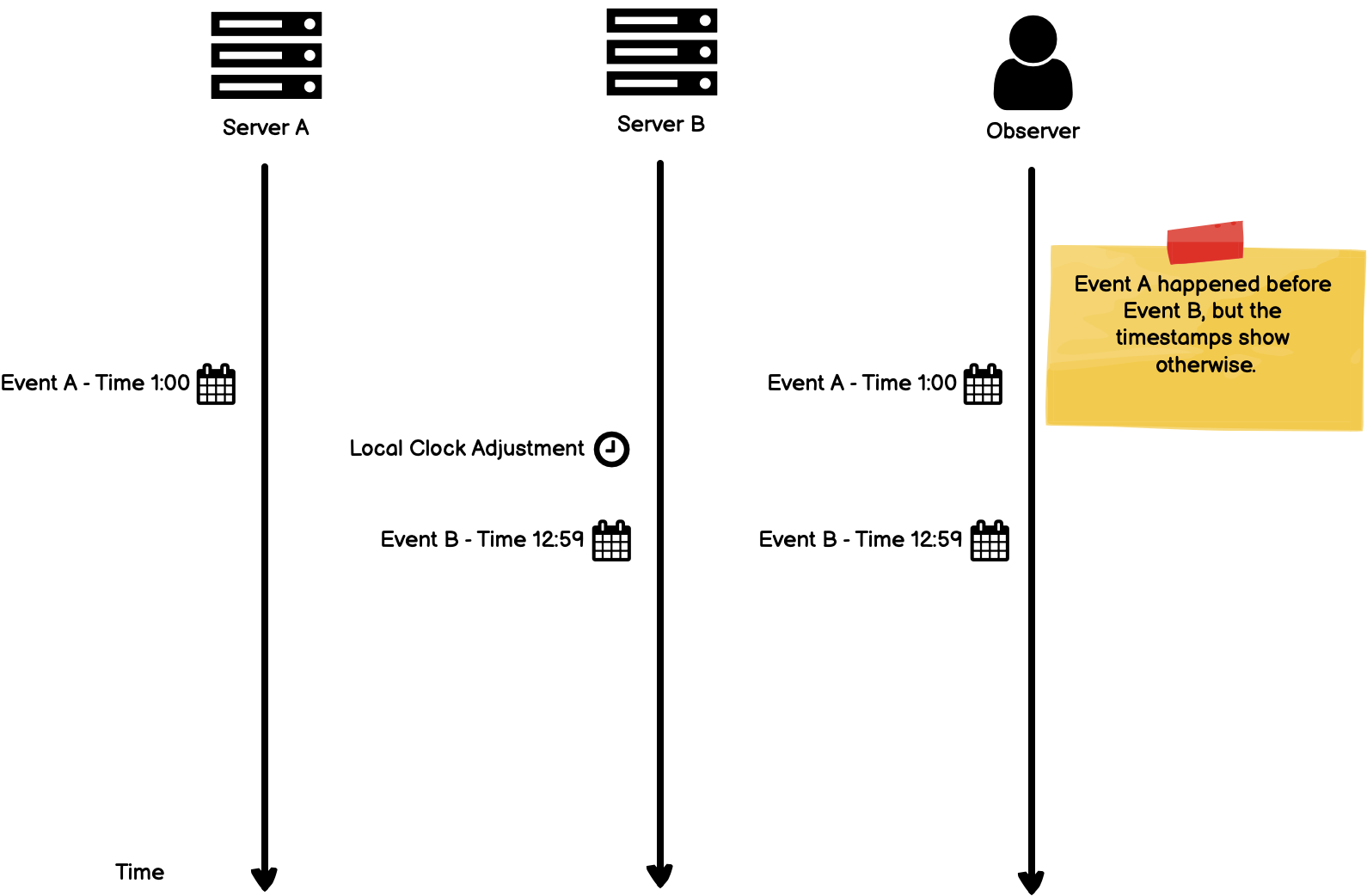
When events occur across multiple servers like in the example above, we would like to have a way of knowing which events happened before the other, regardless of the nuances of the local clock.
This is the subject of the paper Time, Clocks, and the Ordering of Events in a Distributed System, which is one of the most-cited and influential papers in distributed computing history.
The Algorithm
We say that something happened at 3:15 if it occurred after our clock read 3:15 and before it read 3:16 … this concept must be carefully reexamined when considering events in a distributed system.
The Lamport paper approaches the problem of “happens before” from the viewpoint of a mathematician. This is helpful to define proofs of correctness, but can make the paper itself more difficult to understand than necessary. We can gloss over some of the math for a moment and jump straight to the algorithm implementing a Lamport clock, which is actually quite intuitive:
In short, a Lamport clock is a numerical software counter maintained by each independent process.
The algorithm for updating the counter follows some simple rules:
- A process increments its own counter before each event (e.g., before sending an update message);
- When a process sends a message, it includes its counter value with the message;
- On receiving a message, the recipients counter is updated to the larger of its own counter or the one received by the incoming message.
This algorithm makes sure that any updates to the counter always include the most recent data from each process. You can picture this most clearly from the perspective of the receiver — whenever a new message is received, you update your counter to the largest (i.e. newest) data.
In pseudocode, the algorithm for sending can be expressed as:
# event happens
time = time + 1;
send(message, time);
And the algorithm for receiving a message as:
(message, incoming_time) = receive();
time = max(incoming_time, time) + 1;
Conceptually, when a process receives a message, it re-synchronizes its local clock with that sender. This way, the receiver can be sure that each event has a clear ordering.
Using Lamport Clocks to Version Values
A direct application of Lamport clocks is to use them as a logical timestamp that marks the version for a data value. This allows us to order values across servers.
The article Lamport Clock by Unmesh Joshi of Thoughtworks provides a good example of using Lamport clocks to maintain the ordering of values across multiple servers.
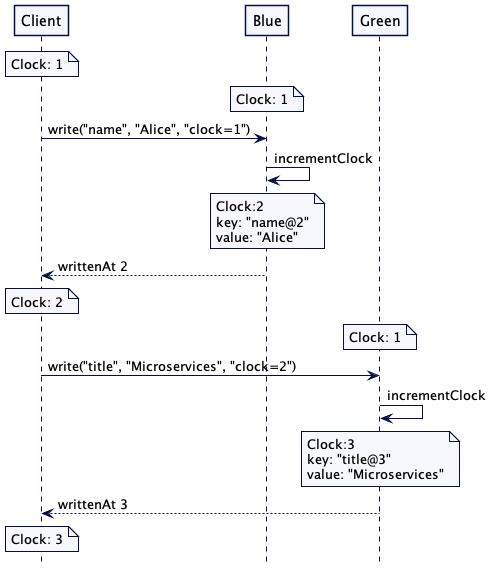
In this diagram, values are stored alongside a Lamport timestamp that is used as a version number. The receiving server compares and updates its own timestamp to the received timestamp and uses it to write a value-version pair. In this way, the client and servers will always know whether or not they are working with the latest version of the data by comparing their local clock to the clock on the incoming message.
The Mathematical Approach
The central idea of Lamport’s paper is to shift away from thinking about exactly when something happened and worry instead about when one event happens before another event. This reframing provides a partial ordering of events in a system.
Most people would probably say that an event a happened before an event b if a happened at an earlier point in time than b.
The problem with this quote from the paper is that to track exact time in a distributed system is — for most practical purposes — not possible. The paper therefore defines the relation “happened before” without using any physical notion of time.
The notation \( \rightarrow \) is used to indicate that an event happens before another event. Strictly speaking, if \( a \rightarrow b \) then:
- If \( a \) and \( b \) are events in the same process, and \( a \) comes before \( b \), then \( a \rightarrow b \).
- If \( a \) is the sending of a message by one process and \( b \) is the receipt of the same message by another process, then \( a \rightarrow b \).
- If \( a \rightarrow b \) and \( b \rightarrow c \) then \( a \rightarrow c \).
Another way of viewing the definition is to say that \( a \rightarrow b \) means that it is possible for event \( a \) to causally affect event \( b \).
As messages travel through time and across space from one process to another, we can start to construct chains of causal events that obey the happens before relation by introducing a simple counter. The counter starts at an initial time (0), and each process treats that counter like their own local clock, incrementing it independently in response to events in the system.
More precisely, we define a clock \( C_i \) for each process \( P_i \) to be a function which assigns a number \( C_i \langle a \rangle \) to any event \( a \) in that process.
Each process must increment their clocks using the following two rules:
IR1. Each process \( P_i \) increments \( C_i \) between any two successive events.
and
IR2. (a) If event \( a \) is the sending of a message \( m \) by process \( P_i \), then the message \( m \) contains a timestamp \( T_m = C_i \langle a \rangle \). (b) Upon receiving a message \( m \), process \( P_j \) sets \( C_j \) greater than or equal to its present value and greater than \( T_m \).
In simpler terms, each clock increments independently, but at different frequencies depending on the events that are happening in their process. When an event occurs, the originating process sends its current value to the target process, which checks whether the value received is greater than its current value. If it is, it changes its current value to received value + 1, else it discards the received value. This allows the clocks to be synchronized with each other over time.
We can reproduce a diagram from the paper to help make this more concrete.
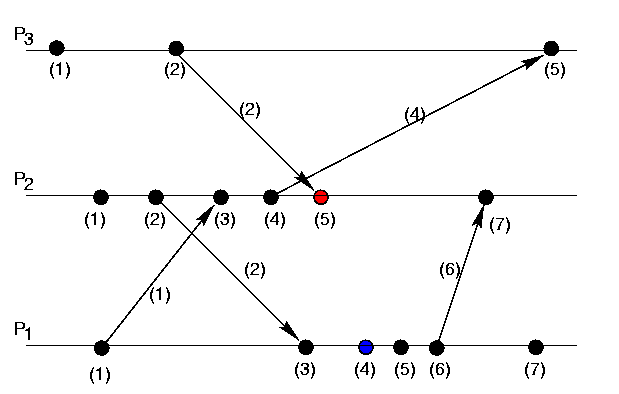
In the example above, time moves from left to right and we have three processes \(P_1\), \(P_2\), and \(P_3\). Each process begins by setting their local clock to 0 and incrementing it by 1 in response to events that happen in the system. Whenever one of the processes needs to communicate with another to establish some form of causal ordering, the message includes the value of the local clock of the sending process. Upon receipt of a message, the local process will update their clock value to the value of the incoming message only if it is greater than their current clock. Otherwise, they will continue to use and increment their current clock.
Resources
In a distributed system, it is not usually possible in practice to synchronize time across nodes within the system. In these cases, the nodes can use the concept of a logical clock attached to the events which they communicate. This kind of information can be important when trying to replay events in a distributed system (such as when trying to recover after a crash). If one node goes down, and we know the causal relationships between messages, then we can replay those messages and respect the causal relationship to get that node back up to the state it needs to be in.
Lamport clocks are a key feature of distributed systems, and have been influential in the design of many distributed databases. Because of this, there are a few well developed resources I’ve included below to help understand them more completely.